

距离Facebook发布新版Relay(Relay Modern)已经快一年时间了,但相关的中文资料与实践案例依然不是很多。究其原因,可能和官方文档不够详细有关。本文通过对GraphQL与Relay的浅析,希望能降低其上手难度,同时也便于判断,自己的业务是否适合使用Relay框架。
什么?直接上代码?猴~可以Github克隆Relay应用模版,里面整合了前后端和路由,基本能满足常见App的需求。
GraphQL
GraphQL是一套独立的数据查询系统,关于它的介绍与使用,官方网站已有比较详细的介绍,同时,现在已有中文版可以参考。对于基本概念,建议直接阅读官网,本文不做详细介绍。
设计思想
之所以名称中包含有Graph,是因为GraphQL采用了图结构的查询方式。以一个例子来看:
我们想要设计一个公司的内部人员管理系统,假设一种最简单的场景,至少会包含部门和员工两大信息。以图的结构来表示他们的关系的话,可能会是这样:
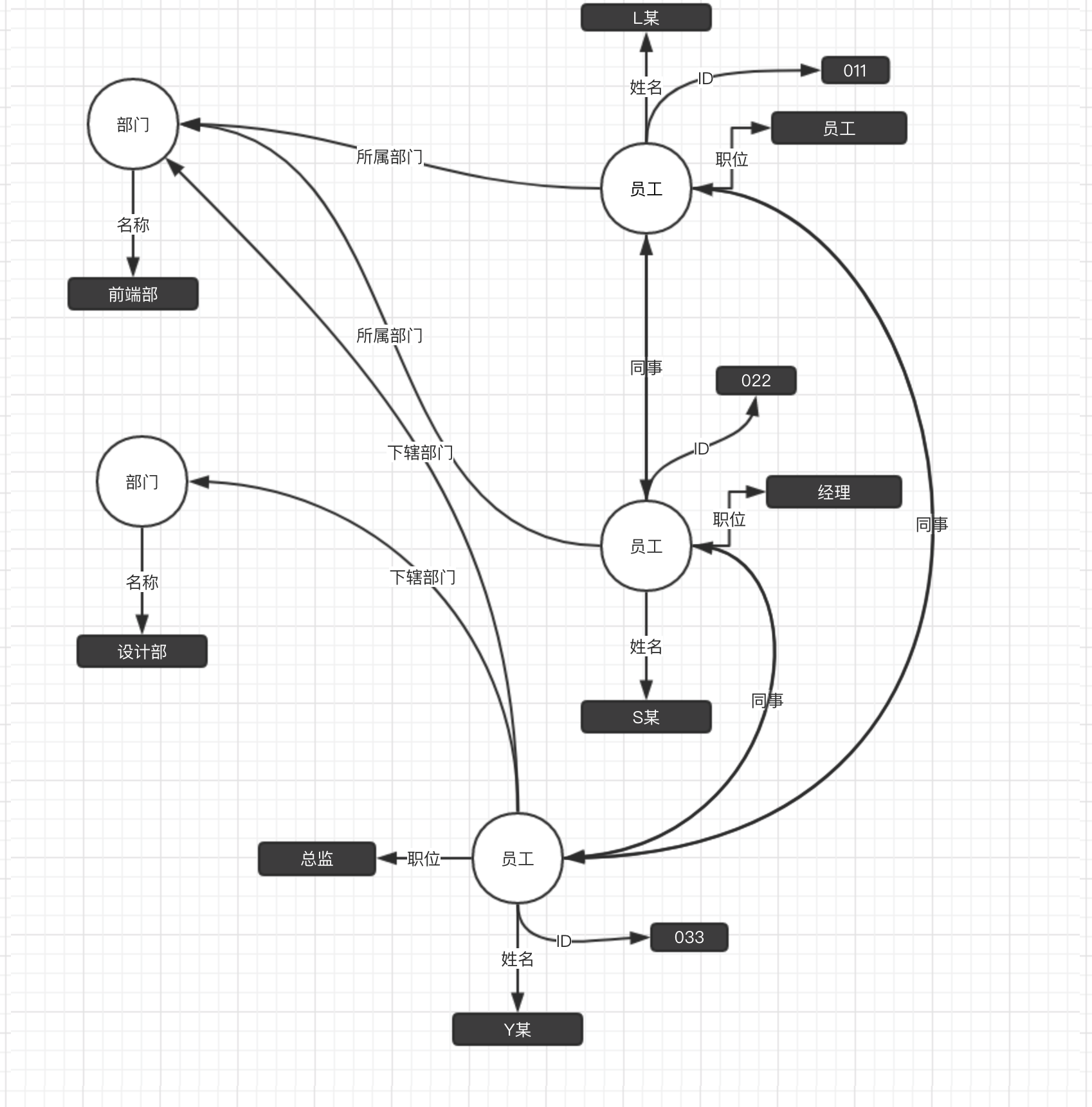
回到上图,假设我们现在要查询员工L某的详细信息,用GraphQL,可以这样来请求(为更加直观,这里以中文来表示):
{
员工(ID: "022") {
姓名
职位
所属部门 {
名称
}
同事 {
ID
姓名
职位
}
}
}
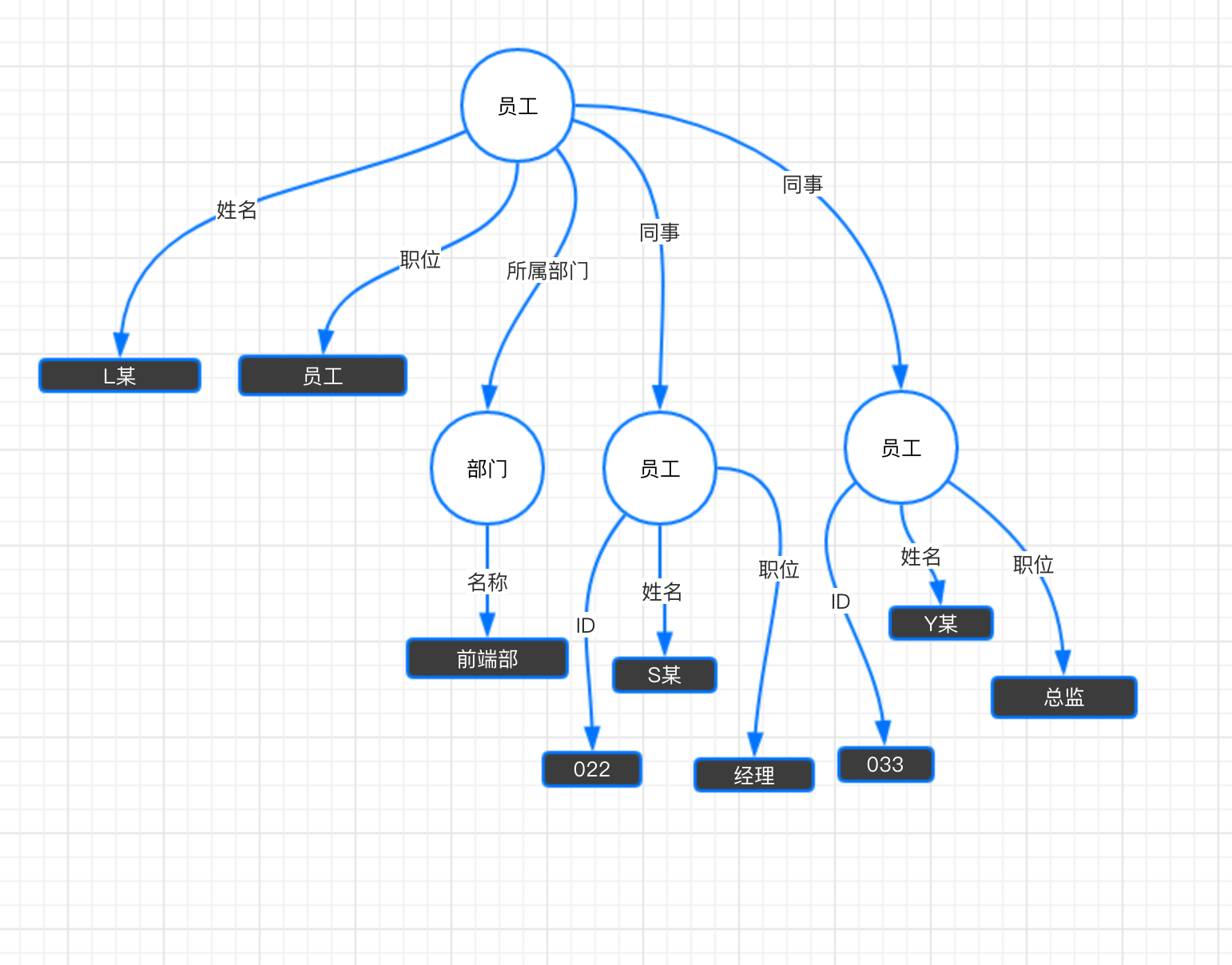
正常情况下,服务端返回的结果是:
{
员工 {
姓名: "L某",
职位: "员工",
所属部门:{
名称: "前端部"
}
同事:[
{
ID: "022",
姓名: "S某",
职位: "经理"
},
{
ID: "033",
姓名: "Y某",
职位: "总监"
}
]
}
}
可以看到,根据查询请求,员工的信息以Json的格式全部返回出来了。对应到图中,其实是提取了蓝色的这部分信息:
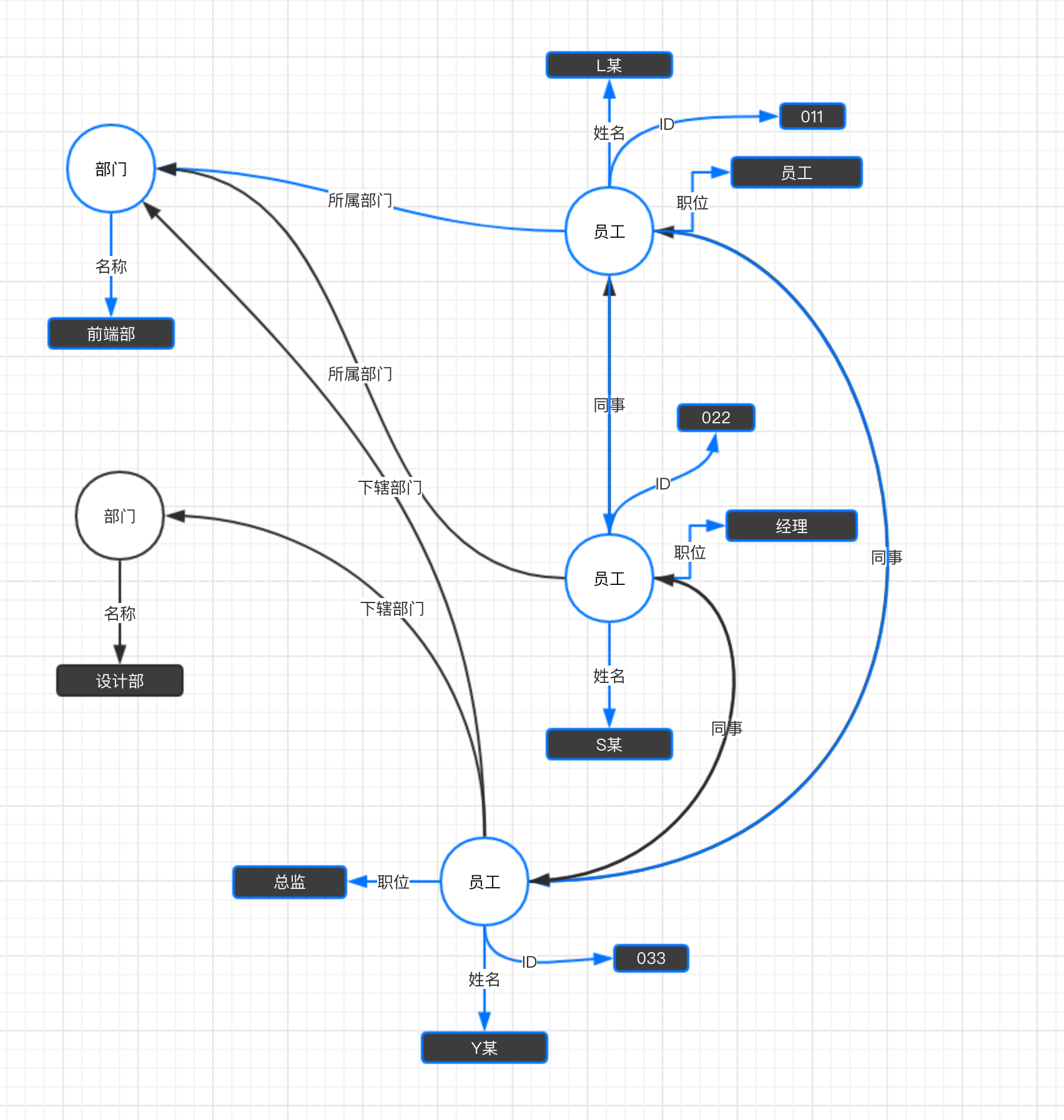
仍以之前的例子来看,如果我想查询员工L某和设计部的信息,但它们之间没有边。这种时候,可以构建一个虚拟的节点,并以它为起点,连接起其他需要查询的节点。大概会是这样的一种结构:
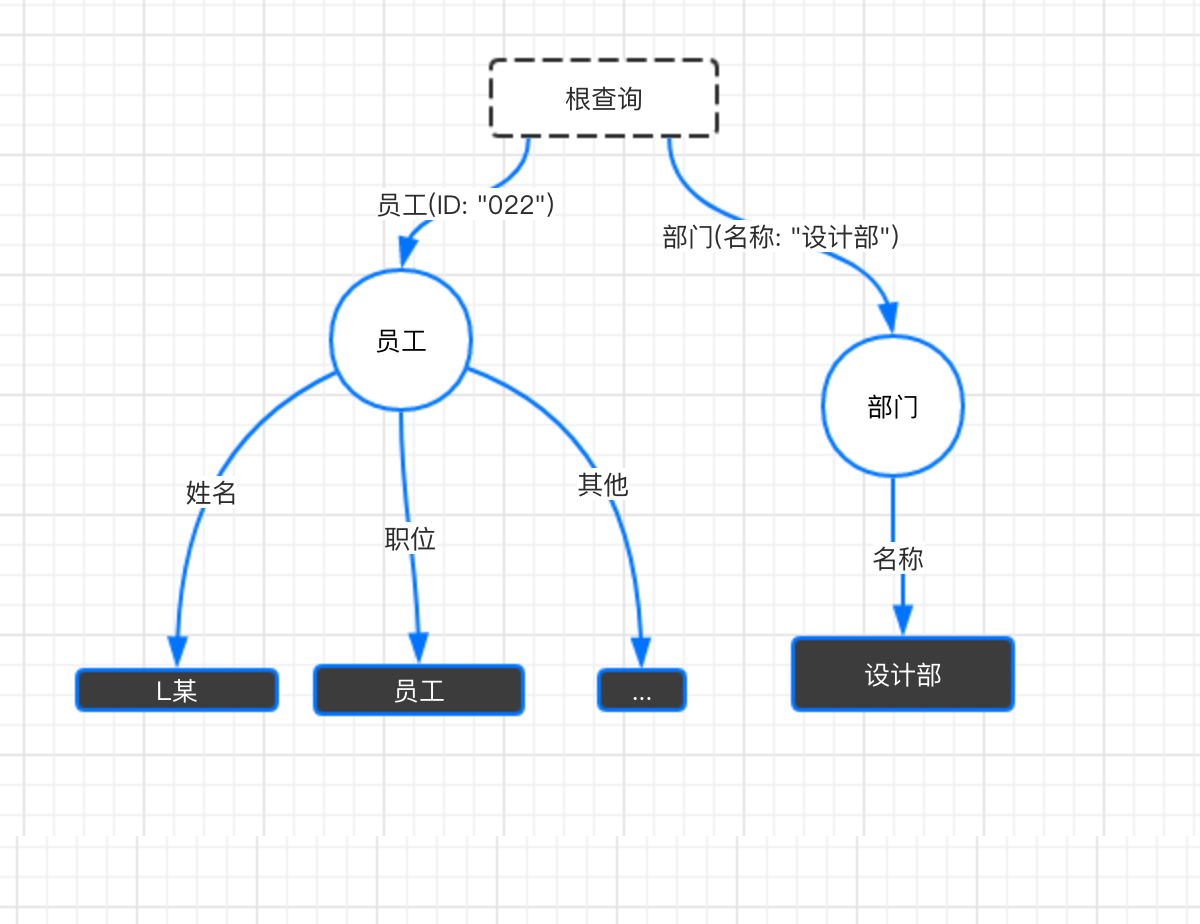
{
员工(ID: "022") {
姓名
职位
...
}
部门(名称: "设计部") {
名称
}
}
返回结果:
{
员工 {
姓名: "L某",
职位: "员工",
...
}
部门 {
名称: "设计部"
}
}
在实际的应用开发中,也通常采用以上这样的设计结构。
到此,我们来总结一下。GraphQL通过查询语句,将图结构的数据,提取成了树状结构作为结果返回。这里的图结构的数据,对应的便是GraphQL的类型系统。而如何将图中的节点,也就是定义的各个类型相互关联,需要通过具体的逻辑代码来实现。官方和社区也提供了各种语言的GraphQL库。
那么还有个问题,如果我想修改数据该怎么办呢?
为解决这个问题,GraphQL引入了Mutation的概念。我们可以把Mutation看作是一种特殊的查询,你需要为它定义名称、参数、返回数据,并在具体的代码逻辑中,完成它的具体数据操作。详细可以参考官方文档。
优势
官方网站简单介绍了GraphQL的一些优点,不过,你可能更想知道,相比其他的API设计模式,GraphQL有什么优势呢?
根据我实践下来的理解,GraphQL主要解决了面向前端的API在开发和后期维护中,常会遇到的一些矛盾点。下面,我们以RESTful API为参照,来具体看一下。
灵活性
再来看上一节的例子,像获取员工全部信息这样的场景在应用开发中还是比较常见的,如果换成RESTful的API,会是怎么样的呢?我想,一般会有两种做法:
- 1、单独的API来拉取全部信息;
- 2、将“同事”、“部门”这些信息作为独立的API,在前端通过多条API来组合。
我们先看第一种做法。这种方式有几点明显的弊端:
首先是信息的冗余。如果我在其他地方只需要显示员工基础信息,不包含具体的部门或同事信息,那就存在了数据的冗余。
其次,从后端角度,会带来维护上的成本。由于前端的展示需求相对多变,很可能会造成许多不再使用的API,而这些API又往往不敢轻易移除。又或者,在新需求中,很可能会新增与现有API重复度较高的API,造成后端业务代码的冗余。
再者,即使考虑通过参数的方式,能使得返回值有可选择性,确实可以增加一定的灵活度,但又不可避免的增加了参数的复杂性。
再看第二种做法。通过这种细粒度的模块划分方式,相对第一种来说,减轻了后端代码的维护成本,但却对前端极不友好。比如,一个列表中的某个字段,后端只提供了单独查询的方式,当列表数据量特别大的时候,请求数也大大增加,将直接影响前端性能与用户体验。此外,大量的异步请求无疑增加了前端代码复杂度,从而提高了前端的维护成本。
而GraphQL只需要定义好类型及对应的数据处理方式,暴露给查询根节点,前端可以随意按需请求,很好的解决了以上的矛盾。
前端友好性
GraphQL用来作为BFF层(Backend For Frontend)有其先天的优势,最主要在于其面向前端的友好性设计。
除了上面提到的,在查询请求中,请求数的减少对前端体验上的提升之外,Mutation同样减少了请求次数。在Restful API中,除了GET请求,其它的请求完成后,前端通常还需要再发出一个GET请求,来拉取变更后的数据。如果在返回结果中,为前端的显示界面而增加了一部分数据,又会破坏后端代码的可复用性。而在GraphQL的Mutation中,返回的数据完全可以根据前端界面的数据需求来决定,而且只需一次请求即可。结合Relay框架,还可以定义理想化更新来减少Loading界面出现的次数,进一步提高用户体验。(这一点会在下一节具体展开)
降低沟通成本
在当下流行的前后端分离开发模式下,前后端开发者的沟通成本也是影响项目进度的一大要素。通常,为了降低沟通成本,后端开发者需要提前定义API文档,前端会根据API文档来MOCK数据以开发前端界面。后端开发者还需要通过各种工具,如PostMan来进行测试。在前后端完成开发后,还需要做联调对接。
对于GraphQL来说,schema自身就是很好的文档。同时,官方还提供了一个类似于PostMan的工具GraphiQL,可以有助于开发中的调试。
其他
GraphQL与Relay框架结合后,还能发挥出更大优势,比如前后端一致的类型校验、前端缓存等,具体请看下一节内容。
Relay
Relay是一套基于GraphQL和React的框架,它将这两者结合,在原来React组件的基础上,进一步将请求封装进组件。
官方提供了一个TodoMVC的demo可以参考,基本涵盖了CRUD操作。
QueryRenderer
Relay框架提供了QueryRenderer这样一个高阶组件(HOC)来封装React组件和GraphQL请求。这个组件接受四个Props:environment、query、variables以及render。
environment需要配置网络请求和Store;query接受的便是GraphQL请求;variables接受GraphQL请求中需要的变量,最后render用来定义组件的渲染。
假设我们要开发一个显示员工基本信息的Relay组件,那么它可能会是这样的:
<QueryRenderer
environment={environment}
query={graphql`
query StaffQuery($id: ID!) {
员工(ID: $id) {
ID
姓名
职位
}
}
`}
variables={{ id: '011' }}
render={({error, props}) => {
if (error) {
return <div>{error.message}</div>;
} else if (props) {
return <div>工号:{props["员工"]["ID"]};姓名:{props["员工"]["姓名"]};职位:{props["员工"]["职位"]};</div>;
}
return <div>Loading...</div>;
}
}
/>
Fragment
现在我们已有了一个展示员工基本信息的组件,如果我们现在要在这个组件的基础上,进一步封装出一个员工列表的组件,该怎么办呢?
参照React组件的方式,可以创建一个新的组件,接收一个包含员工ID数组的props,在这个新的组件内部,根据ID数组Map多个员工信息的Relay组件。
这样似乎可以,但问题是,如果有10个ID,那这样一个组件也就会发出10个GraphQL请求,显然违背了GraphQL的设计理念。
当然也可以创建一个新的Relay组件:query中直接请求一组员工数据,渲染出列表。但这样就失去了组件的复用性,因为很显然,这个新组件中,显示每条员工信息的逻辑和样式,跟单个员工信息的组件是一致的。
这里,Relay提供了一个Fragment的HOC组件,它接受两个Props:component和fragmentSpec。
component接受React组件,用来处理具体的组件视图和逻辑;fragmentSpec则是接受一段GraphQL Fragment。所谓Fragment,对应到上一节的图中,就是节点的某一部分。比如:
fragment 员工信息 on 员工 {
ID
姓名
职位
}
在请求中,就可以这样引入Fragment:
{
员工(ID: "022") {
...员工信息
}
}
那么回到Relay中,可以这样创建一个员工信息的Fragment组件:
createFragmentContainer(
class 员工信息 extends React.Component {
render() {
return <div>工号:{this.props.data["员工"]["ID"]};姓名:{this.props.data["员工"]["姓名"]};职位:{this.props.data["员工"]["职位"]};</div>;
}
},
graphql`
fragment 员工信息 on 员工 {
ID
姓名
职位
}
`,
)
有了这样一个员工信息的Fragment组件后,我们可以再创建员工信息列表的组件:
<QueryRenderer
environment={environment}
query={graphql`
query StaffListQuery($ids: [ID]!) {
员工(IDs: $ids) {
...员工信息
}
}
`}
variables={{ id: ['011', '022', '033'] }}
render={({error, props}) => {
if (error) {
return <div>{error.message}</div>;
} else if (props) {
return <员工信息 data={this.props.data} />;
}
return <div>Loading...</div>;
}
}
/>
这样一来,组件实际的请求还是只有一条,但员工信息的组件得到了成功复用,如果在其他组件中,需要显示员工信息,也同样只需要将该Fragment组件引入即可。
除了基本的Fragment Container,Relay还提供了Refetch Container和Pagination Container组件,前者在原Fragment组件的基础上,注入了refetch方法,以便满足组件需要更新数据的场景(如:用户主动点击数据列表的刷新按钮);而后者,则添加了若干分页的操作,这里就不具体展开了。
Relay Store
在QueryRenderer中配置的environment里面,主要包含的是网络请求和Store。这里的Store于Redux的Store不太一致。Redux中主要用来统一管理组件的State,而Relay Store则记录的是Record。这里的Record,其实就是GraphQL的每个Type,或者对应于上一节的图中的每个节点。
当Relay框架收到GraphQL返回的数据后,会为每一个节点数据记录一个ID,并在Relay Store中存为一个Record。同时,Relay也为这些Record提供了CRUD的方法。具体可以参考官方文档。
Mutations
为了便于在组件中发起GraphQL Mutation操作,Relay提供了commitMutation方法。除了发起Mutation之外,利用Relay Store,可以方便的定位页面数据并进行更新,还能够实现理想更新,进一步提升用户体验。
优势
到这里,基本已经涵盖了Relay的全部功能。从上文可以看出,在GraphQL原有的优势基础上,Relay还带来了以下两点优势:
- 1、实现了数据查询与组件的结合,进一步提高了前端模块化程度,提高组件复用性。
- 2、优秀的客户端缓存,提升用户体验。
除此之外,结合Flow框架的类型检测,Relay可以很好地根据后端提供的schema做类型校验,避免一些潜在的Bug。
总结
通过以上的介绍和分析,相信你对GraphQL与Relay已经有了大致的了解,我认为,Relay比较适合的场景,是那种前端数据展示类别众多,且变化较大的应用,比如社交网站。但具体是否在项目中应用,还是需要结合需求实际来决定。
