

起因
事件的起因是这个样子的,今天本来打算登录 CSDN 看我的以前的一篇博客,结果登陆的时候是这个样子的:
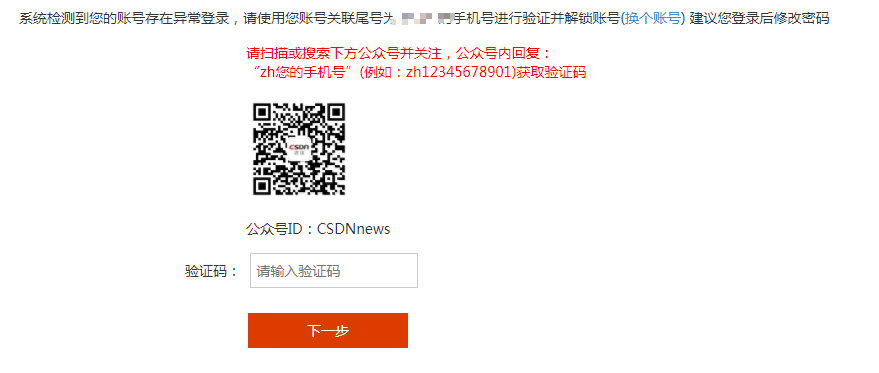

这已经不是第一次 CSDN 这么干了,之前让我验证用手机编辑短信发送验证已经恶心到我了。这一次简直让我忍无可忍。难道就是为了强行推官一波公众号。CSDN 的博客我从 15 年开始维护,后来其实都不是很喜欢,但毕竟是维护了一个蛮久的平台,这一次我终于不能忍了,再也不要忍受丑陋的模块,再也不要忍受恶心的广告,再也不要忍受这鬼逻辑。但是我之前的博客我得保存下来,马上动手。
动手
本来想装个逼,心想半个小时写个爬虫不就搞定了,人生苦短,我有 python. Naive。又折腾了好几个小时,兜兜转转。废话不说,先分析网络请求吧。我只希望保存博客的 markdown 格式文件,我首先打开文章编辑,老规矩,打开控制台网络窗口,看看请求,搞不好 xhr 里面就有,果不其然:

哈哈,一目了然,markdowncontent 不正是我们需要的么。心里顿时觉得半个小时更稳了。爬虫,当然是 requests,听说这个库的作者最近又出了 requests-html 正好可以用来解析。前面都很顺利,分析页面,看看博客内容一共有多少页,然后在每一页获取博客的 articleid 再去请求博客。
def get_page_urls(html):
page_urls_arr = []
page_urls = html.find('.pagination-wrapper .page-item a')
for page_url in page_urls:
if 'href' in page_url.attrs:
href = page_url.attrs['href']
page_urls_arr.append(href)
print(href)
page_urls_arr = list(set(page_urls_arr))
return page_urls_arr
def get_article_id_list(url):
id_list = []
r = session.get(url)
html = r.html
page_urls = get_page_urls(html)
for page_url in page_urls:
id_list = id_list + get_article_ids_by_page(page_url)
# print(id_list)
return id_list
def get_article_ids_by_page(page_url):
r = session.get(page_url)
html = r.html
article_ids = html.find('.blog-unit a')
article_isd_arr = []
for article_id in article_ids:
href = article_id.attrs['href']
article_isd_arr.append(parse_article_id(href))
return article_isd_arr
def parse_article_id(url):
return url.replace('http://blog.csdn.net/neal1991/article/details/', '')
我们这样就可以获取一个 article_id 组成的数组,然后通过和 ttp://mp.blog.csdn.net/mdeditor/getArticle?id= 拼接组成 url 就可以去请求博客了。
问题
很显然,我低估了问题吗,或许也可以说我没有从一个正确的角度去思考这个问题。去访问这个文章是需要权限的,也就是需要登陆之后才可以访问,我尝试直接访问,响应都是无权操作。那我们就登陆好了:
session = HTMLSession()
r = session.post(login_url, auth=(username, passwd))
session.get(url)
这里其实就是这个大概的意思,通过 session 似乎是可以直接访问的,但是还是不可以。后来我尝试首先获取 cookies,然后再次请求的时候把 cookies 塞进去请求,结果还是不行。哇。后来我才发现:

CSDN 果然不是一般的恶心,每次登陆的时候会给一个流水号,登陆验证的时候需要验证这个流水号,但是你拿 cookies 的时候和登陆的时候流水号不一致,所以无法通过验证。后来想到或许可以使用 headless chrome,于是就去用 puppeteer,使用体验和phantomjs 类似,顺嘴提一句,phantomjs 感觉都快不行了,最近维护者又内讧了。这种方式还是比较低效,而且还得去慢慢调试,最后还是用 python 吧。
找到了我最不愿意使用的方法,先从浏览器中把 cookies 拷贝下来,然后再去请求。因为一开始心里总是接受不了这种半自动化的方式,显得太 low。白猫黑猫,抓到老鼠就可以了。罢了。
def parse_cookie(str):
cookies = {}
for line in str.split(';'):
name, value = line.strip().split('=', 1)
cookies[name] = value
return cookies
def get_markdown_files(id_list, base_url):
for id in id_list:
url = base_url + id
get_markdown(url)
def get_markdown(url):
cookies = parse_cookie(config['cookies'])
r = requests.get(url, cookies=cookies)
data = r.json()['data']
title = data['title']
markdown_content = data['markdowncontent']
invalid_characaters = '\\/:*?"<>|'
for c in invalid_characaters:
title = title.replace(c, '')
generate_file('data/' + title.strip() + '.md', markdown_content)
def generate_file(filename, content):
if not os.path.exists(filename):
if content is None:
print(filename + 'is none')
else:
print(filename)
with open(filename, 'w', encoding='utf8') as f:
f.write(content)
f.close()
这里有几点注意一下,首先需要 format 下 cookies,然后就是文件名中的特殊字符需要转义,否则 oepn 会提示 FileNotFound。
结语
不管怎么样,最终问题还是解决了,虽然不是一开始期望的方式。其实有时候经常觉得写代码好费劲,没有一次是刷刷刷就把代码全部写出来,还要不断地调试,不断地 解决问题,最终才能达到目的。最终发花了几个小时,写了这几小段代码,一个小时写了这篇文章总结。累。
以上。
欢迎搜索微信号 mad_coder 或者扫描二维码关注公众号:

