

1、JVM是什么
Java虚拟机(Java Virtual Machine),一种能够运行字节码的虚拟机,将字节码解释成不同os下的机器指令,有了jvm,java语言在不同平台上运行时不需要重新编译,即平台无关性。
原理:编译后的 Java 程序指令并不直接在硬件系统的 CPU 上执行,而是由 JVM 执行。JVM屏蔽了与具体平台相关的信息,使Java语言编译程序只需要生成在JVM上运行的目标字节码(.class),满足了高级语言要求的可移植性、可传输性、预编译等等需求。
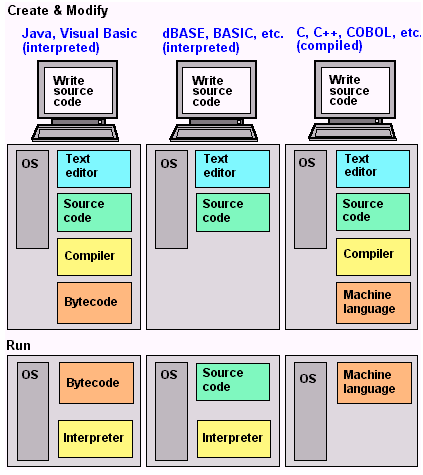
1、以 Java 为例,我们在文本编译器写好了 Java 代码,交由「编译器」编译成 Java Bytecode。然后 Bytecode 交由 JVM 来执行,这时候 JVM 充当了「解释器」的角色,在解释 Bytecode 成 Machine Code 的同时执行它,返回结果。 2、以 BASIC 语言(早期的可以由计算机直译的语言)为例,通过文本编译器编写好,不用经历「编译」的过程,就可以直接交由操作系统内部来进行「解释」然后执行。 3、以 C 语言为例,我们在文本编译器编写好源代码,然后运行 gcc hello.c 编译出 hello.out 文件,该文件由一系列的机器指令组成的机器码,可以直接交由硬件来执行。
1.2 jvm的启动流程
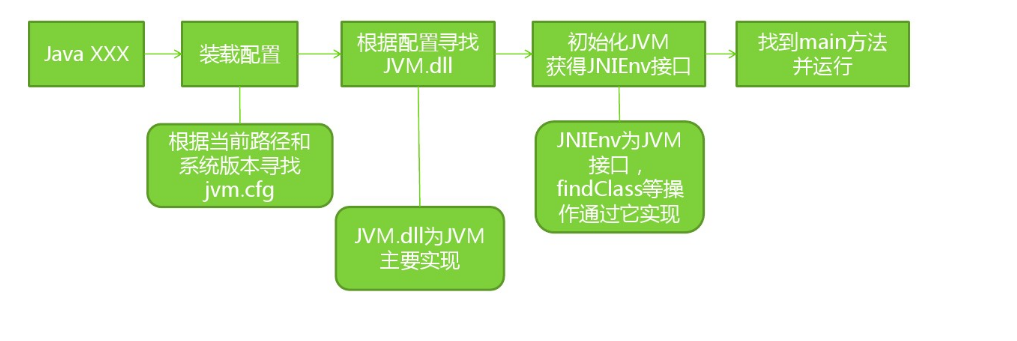
jvm.cfg
-server KNOWN
-client IGNORE
-hotspot ALIASED_TO -server
-classic WARN
-native ERROR
-green ERROR
KNOWN 表示存在 、IGNORE 表示不存在 、ALIASED_TO 表示给别的JVM去一个别名 WARN 表示不存在时找一个替代 、ERROR 表示不存在抛出异常
1.3 jvm的优势,其他语言选择在JVM实现
目前有很多语言选择了jvm,比如说Scala,Kotlin,Ceylon,Xtend,Groovy,Clojure;
JVM经过长期的发展,已经足够成熟和完备。一个完整的语言包括 前端、优化、后端、runtime、库 JVM 把后面四个都给包办了。
- 非常经济地实现跨平台。语言编译器只需要输出 JVM 字节码就可以。跨平台需要极大的工作量,举个例子,只是独立开发生成本地代码,就需要花费大量精力去针对不同平台和处理器进行优化 。
- JVM 卓越的 JIT (Just-In-Time 即时编译)性能。 JIT 可以在运行中记录程序运行的特征,并在其基础上做大量的优化(Java 企业级应用的优秀性能很大程度上是由此而来)。 JIT 自从 HotSpot JVM 随 Java 1.2 发布以来,JVM JIT 的性能不断提高,是无可争议的成功产品。把 JVM 作为目标平台意味着大量的性能优化工作可以「外包」给 JVM 来做,大大缩减了 Guest 语言的开发预算。
- 已经有多个成熟的实例,有大量的经验可以借鉴
- JVM 作为一个成熟的高层运行环境,为 Guest 语言提供了很多运行时所需要的服务,比如内存管理(有业界领先的垃圾回收等),很大程度上避免了额外的独立开发。
- JVM 有多个独立实现,也有若干厂商会持续推进,资料完备,社区巨大。
- Java 社区有大量成熟的库,一般来说,运行在 JVM 上的其它语言都会设计一个专用的「桥」来帮助直接使用 Java 的库,对潜在客户来说是个很好的卖点。
- Java 有还算不错的开发工具和环境。目标为 JVM 的很多语言会考虑用 Java 语言实现(至少在 bootstrap 阶段)。
2、JVM结构
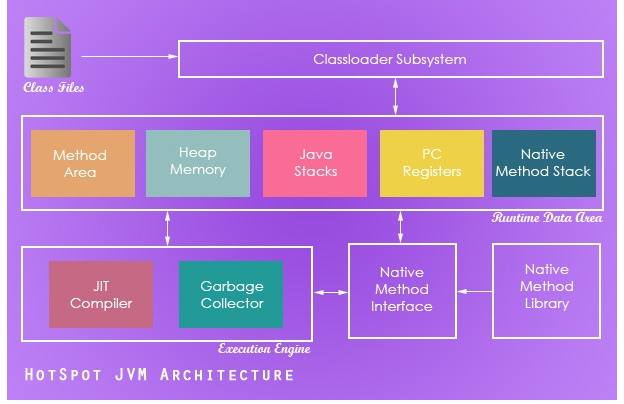
在Java虚拟机的规范中定义了一系列的子系统、内存区域、数据类型和使用指南。这些组件构成了Java虚拟机的内部结构,他们不仅仅为Java虚拟机的实现提供了清晰的内部结构,更是严格规定了Java虚拟机实现的外部行为。
这里简单介绍一下各个组件的作用
-
类加载器子系统:每一个Java虚拟机都由一个类加载器子系统(class loader subsystem),负责加载程序中的类型(类和接口),并赋予唯一的名字。每一个Java虚拟机都有一个执行引擎(execution engine)负责执行被加载类中包含的指令。
-
程序的执行需要一定的内存空间,如字节码、被加载类的其他额外信息、程序中的对象、方法的参数、返回值、本地变量、处理的中间变量等等。Java虚拟机将 这些信息统统保存在数据区data areas中。虽然每个Java虚拟机的实现中都包含数据区,但是Java虚拟机规范对数据区的规定却非常的抽象。许多结构上的细节部分都留给了 Java虚拟机实现者自己发挥。不同Java虚拟机实现上的内存结构千差万别。一部分实现可能占用很多内存,而其他以下可能只占用很少的内存;一些实现可 能会使用虚拟内存,而其他的则不使用。这种比较精炼的Java虚拟机内存规约,可以使得Java虚拟机可以在广泛的平台上被实现。
-
数据区中的一部分是整个程序共有,其他部分被单独的线程控制。每一个Java虚拟机都包含方法区(method area)和堆(heap),他们都被整个程序共享。Java虚拟机加载并解析一个类以后,将从类文件中解析出来的信息保存与方法区中。程序执行时创建的 对象都保存在堆中。 当一个线程被创建时,会被分配只属于他自己的PC寄存器“pc register”(程序计数器)和Java堆栈(Java stack)。当线程不掉用本地方法时,PC寄存器中保存线程执行的下一条指令。Java堆栈保存了一个线程调用方法时的状态,包括本地变量、调用方法的 参数、返回值、处理的中间变量。调用本地方法时的状态保存在本地方法堆栈中(native method stacks),可能再寄存器或者其他非平台独立的内存中。
-
Java堆栈有堆栈块(stack frames (or frames))组成。堆栈块包含Java方法调用的状态。当一个线程调用一个方法时,Java虚拟机会将一个新的块压到Java堆栈中,当这个方法运行结束时,Java虚拟机会将对应的块弹出并抛弃。
-
Java虚拟机不使用寄存器保存计算的中间结果,而是用Java堆栈在存放中间结果。这是的Java虚拟机的指令更紧凑,也更容易在一个没有寄存器的设备上实现Java虚拟机。
2.1、解释器
解释器我们可以理解为,把一种高级语言转换成另一种语言的程序。在JVM中,解释器即将字节码文件转成机器二进制语言,使我们的电脑可以直接执行。然而因为每次运行程序时都要先转成另一种语言再作运行,因此解释器的运行速度可想而知,这也造成了java运行速度比较慢的印象。
从本质上讲,每个程序都是一台机器的“描述”,而解释器就是在“模拟”这台机器的运转,也就是在进行“计算”。所以从某种意义上讲,解释器就是计算的本质
解释器一般都是“递归程序”。之所以是递归的原因,在于它处理的数据结构(程序)本身是“递归定义”的结构。
在java1.2版本之后,如今的HotSpot VM中不仅内置有解释器,还内置有先进的JIT(Just In Time Compiler)编译器,在Java虚拟机运行时,解释器和即时编译器能够相互协作,各自取长补短
2.2、JIT
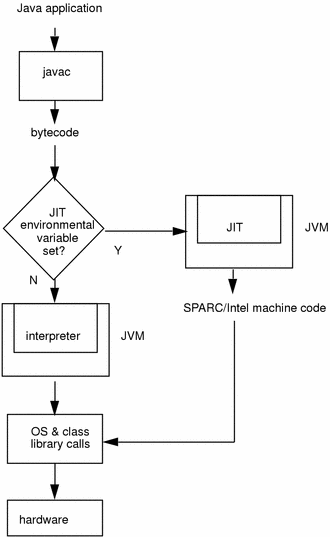
HotSpot虚拟机采用了热点代码探测技术:通过计数器找出最具编译价值的代码,通知JIT以方法为单位进行编译。如果方法被频繁调用,则触发标准编译;如果方法中循环次数很多,触发栈上替换编译动作。 HotSpot无需等待本地代码输出后才能执行程序,使得即时编译压力减小,有助于采用更更多的代码优化技术。输出高质量的操作系统本地代码。
为什么HotSpot虚拟机要使用解释器与编译器并存的架构?
尽管并不是所有的Java虚拟机都采用解释器与编译器并存的架构,但许多主流的商用虚拟机(如HotSpot),都同时包含解释器和编译器。解释器与编译器两者各有优势:当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。当程序运行环境中内存资源限制较大(如部分嵌入式系统中),可以使用解释器执行节约内存,反之可以使用编译执行来提升效率。此外,如果编译后出现“罕见陷阱”,可以通过逆优化退回到解释执行。
编译的时间开销
解释器的执行,抽象的看是这样的:
输入的代码 -> [ 解释器 解释执行 ] -> 执行结果
而要JIT编译然后再执行的话,抽象的看则是:
输入的代码 -> [ 编译器 编译 ] -> 编译后的代码 -> [ 执行 ] -> 执行结果
说JIT比解释快,其实说的是“执行编译后的代码”比“解释器解释执行”要快,并不是说“编译”这个动作比“解释”这个动作快。 JIT编译再怎么快,至少也比解释执行一次略慢一些,而要得到最后的执行结果还得再经过一个“执行编译后的代码”的过程。 所以,对“只执行一次”的代码而言,解释执行其实总是比JIT编译执行要快。 怎么算是“只执行一次的代码”呢?粗略说,下面两个条件同时满足时就是严格的“只执行一次”
1、只被调用一次,例如类的构造器(class initializer,())
2、没有循环
对只执行一次的代码做JIT编译再执行,可以说是得不偿失。 对只执行少量次数的代码,JIT编译带来的执行速度的提升也未必能抵消掉最初编译带来的开销。
只有对频繁执行的代码,JIT编译才能保证有正面的收益。 编译的空间开销 对一般的Java方法而言,编译后代码的大小相对于字节码的大小,膨胀比达到10x是很正常的。同上面说的时间开销一样,这里的空间开销也是,只有对执行频繁的代码才值得编译,如果把所有代码都编译则会显著增加代码所占空间,导致“代码爆炸”。 这也就解释了为什么有些JVM会选择不总是做JIT编译,而是选择用解释器+JIT编译器的混合执行引擎。
为何HotSpot虚拟机要实现两个不同的即时编译器?
HotSpot虚拟机中内置了两个即时编译器:Client Complier和Server Complier,简称为C1、C2编译器,分别用在客户端和服务端。目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作。程序使用哪个编译器,取决于虚拟机运行的模式。HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式。
用Client Complier获取更高的编译速度,用Server Complier 来获取更好的编译质量。为什么提供多个即时编译器与为什么提供多个垃圾收集器类似,都是为了适应不同的应用场景。
开发人员可以通过如下命令显式指定Java虚拟机在运行时到底使用哪一种即时编译器,如下所示:
-client:指定Java虚拟机运行在Client模式下,并使用C1编译器;
-server:指定Java虚拟机运行在Server模式下,并使用C2编译器。
wiki上总结的jvm产品 https://en.wikipedia.org/wiki/Comparison_of_Java_virtual_machines
3、通过jclasslib查看字节码文件
字节码转义后可以容易的看出,是如何加载了init方法和add方法。
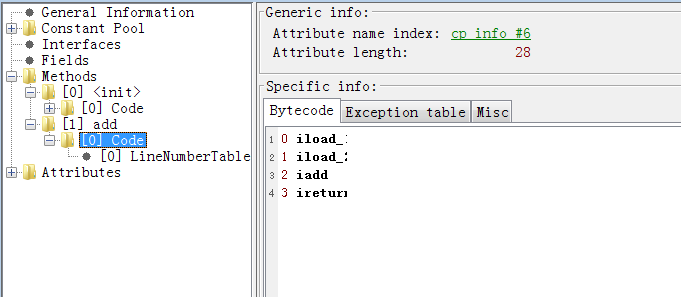
iload_1 从局部变量0中装载int类型值
iload_2 从局部变量0中装载int类型值
iadd 执行int类型的加法
ireturn 从方法中返回int类型的数据
1、[讨论] [HotSpot VM] JIT编译以及执行native http://hllvm.group.iteye.com/group/topic/39806
2、JVM编译器的编译过程 http://blog.csdn.net/tingfeng96/article/details/52261219
3、JVM即时编译(JIT) http://blog.csdn.net/sunxianghuang/article/details/52094859
