

编者按:数据科学开发者Sagar Howal通过一个浅显易懂的示例,介绍了如何使用Google Colaboratory——Google提供的用于数据科学和机器学习的协作开发工具。Colaboratory十分好用,而且是免费的。
Google最近发布了Google Colaboratory(g.co/colab)。Google Colaboratory原为Google数据科学编程的内部协作工具,现在Google把它作为公开服务发布出来。Google Colaboratory基于Jupyter开源项目,并集成了Google Drive。Colaboratory使用户能像使用Google文档或电子表格一样方便地使用Jupyter Notebook。

Colaboratory
使用Colaboratory很简单。如果你有Google账号的话,直接访问Colaboratory网站即可开始使用。Colaboratory让你使用Google的虚拟机运行机器学习任务,这样你可以直接上手构建模型,无需担忧算力问题。而且,它是免费的。
初次打开Colaboratory,你会看到一个欢迎文件“Hello, Colaboratory”,里面有一些基本的例子。你可以尝试一下。
在Colaboratory中,你可以像在Jupyter Notebook中一样编写代码。按Shift+Enter 可以运行代码块,结果会显示在代码块下方。
除了代码之外,你也可以运行shell命令,加上!作为前缀就可以,例如:
!pip install -q keras
下面我将通过一个例子演示如何使用Colaboratory训练神经网络。我们将在UCI机器学习仓库提供的威斯康星州乳腺癌数据库上训练一个神经网络。
这里是与本文配套的Colaboratory notebook。
深度学习
本文假设读者对神经网络和深度学习有一定了解。如果你需要温习这方面的知识,可以参考Carlos Greshenson的论文(这是一篇非常容易阅读的论文)。你也可以参考其他网上资源。
不过,即使你现在还不理解神经网络,也不用担心,因为我们会循序渐进。让我们开始……
代码
问题:
研究人员获取了细针穿刺抽吸活组织检查(FNA)数据,生成对应的数码图像。数据集中包含了描述图像中的细胞核特性的实例。每个实例标注为“恶性”或“良性”。我们的任务是在这些数据上训练网络,以诊断乳腺癌。
在Colaboratory中新建一个notebook(untitled.ipynb文件)。
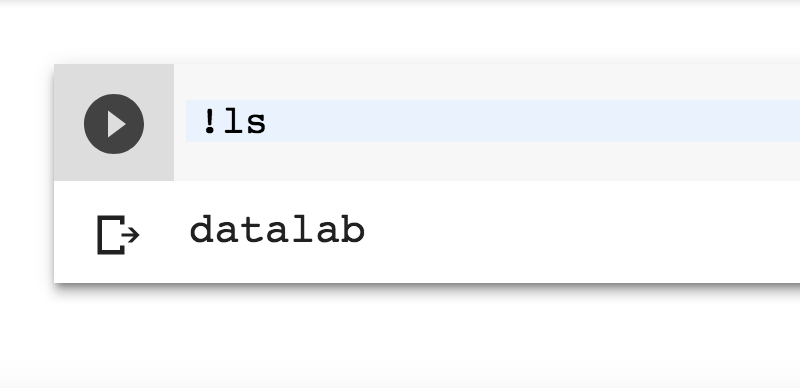
正如我们前面提到的,notebook背后是一个虚拟linux机器,因此你可以安装项目所需的软件包。现在就来试一下,在代码块中输入!ls(记得在所有命令前加!):
接下来我们上传数据集:
# 上传数据集
from google.colab import files
uploaded = files.upload()
# 保存上传的文件到虚拟机
# 感谢StackOverflow的user3800642
with open("breast_cancer.csv", 'w') as f:
f.write(uploaded[uploaded.keys()[0]])
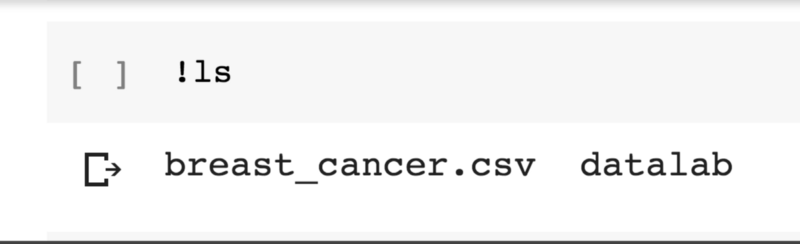
输入!ls检查下文件是否就绪:
数据处理:
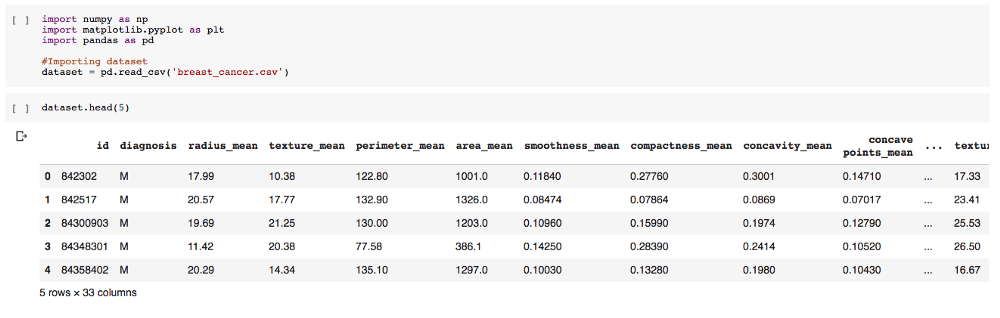
导入数据集(使用pandas):
import numpy as np
import pandas as pd
# 导入数据集
dataset = pd.read_csv('breast_cancer.csv')
# 查看数据集的前5行
dataset.head(5)
分离因变量和自变量:
# 剔除最后一列(全是NaN值)
X = dataset.iloc[:, 2:32].values
y = dataset.iloc[:, 1].values
y包含单独的一列,其中有两个类别M和B,分别代表“恶性”和“良性”。它们需要被编码为相应的数学形式,即 1和0 。这可以通过LabelEncoder类(标签编码器)实现。
# 编码分类数据
from sklearn.preprocessing import LabelEncoder
labelencoder = LabelEncoder()
y = labelencoder.fit_transform(y)
(如果你的数据包含超过2个类别,你可以使用OneHotEncoder)
数据就绪之后,让我们切分训练集和测试集。我们使用Scikit-Learn中的train_test_split 类:
rom sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
test_size = 0.2参数定义了测试集的比例。也就是80%作为训练集,20%作为测试集。
Keras
Keras是构建神经网络的高层API,底层操作基于Tensorflow。因此,安装Keras前先要安装Tensorflow。Colaboratory的虚拟机已经预装了Tensorflow。输入以下命令可以查看当前安装的Tensorflow版本:
!pip show tensorflow
如有必要,你也可以安装特定版本的Tensorflow,例如:
!pip install tensorflow==1.2
安装Keras:
!pip install -q keras
加载Keras:
mport keras
from keras.models import Sequential
from keras.layers import Dense
Sequential和Dense类用来指定神经网络的节点、连接。我们需要这两个类来定制和调整网络的参数。
创建一个Sequential对象以初始化神经网络:
classifier = Sequential()
现在我们需要设计网络。
我们需要为每个隐藏层定义3个基本参数:units、kernel_initializer、activation。units参数定义神经元数目。kernel_initializer定义初始权重(详见keras文档)。activation定义激活函数。
注意:如果这些术语让你感到头大,不用忧虑。请继续阅读,你会逐渐了解这些概念的。
第一层:
我们在第一层放置了16个神经元(统一初始化权重),使用ReLU激活函数。input_dim = 30是因为我们的数据集中有30个特征列。
作弊:
我们是如何决定神经元的数目的?人们会告诉你这是源自经验和专门知识的艺术。对于初学者来说,一个简单的方法是将X和y的列数相加,然后除以2。(30+1)/2 = 15.5 ~ 16. 所以units = 16
第二层:
除了不带input_dim参数外,第二层和第一层一模一样。
输出层:
由于我们的输出是二元值中的一个,我们可以使用统一初始化权重的单个神经元。这里我们使用了sigmoid激活函数。(关于不同激活函数的选择,可以参考这篇文章。)
-
# 输入层和第一个隐藏层
-
classifier.add(Dense(units = 16, kernel_initializer = 'uniform', activation = 'relu', input_dim = 30))
-
-
# 第二个隐藏层
-
classifier.add(Dense(units = 16, kernel_initializer = 'uniform', activation = 'relu'))
-
-
# 输出层
-
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
-
-
# 优化和损失
-
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
拟合:
运行人工神经网络,让反向传播魔法发挥威力吧!
# 拟合训练集
classifier.fit(X_train, y_train, batch_size = 10, epochs = 100)
上面的batch_size是你希望同时处理的输入数量。epoch是所有数据在神经网络中过一遍的完整周期。运行上述代码后,Colaboratory Notebook的输出是这样的:
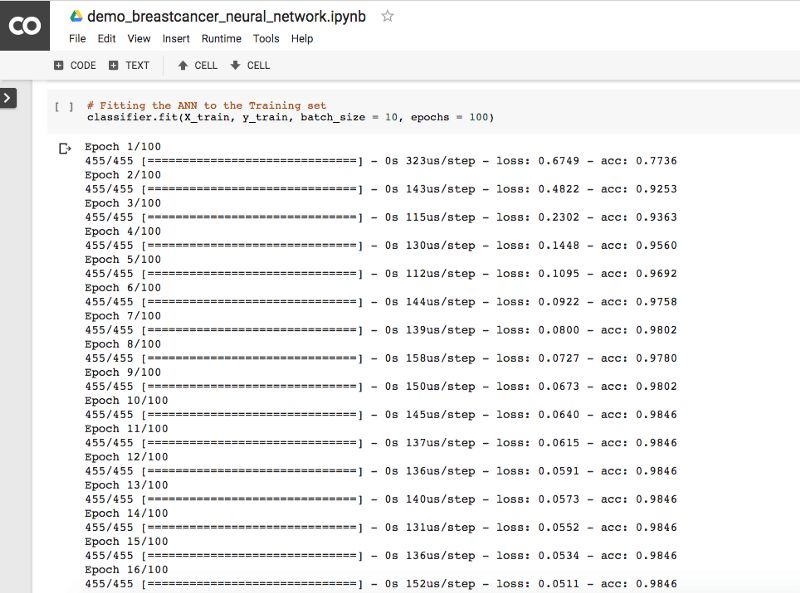
进行预测,生成混淆矩阵。
# 预测测试集结果
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)
# 生成混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
训练网络之后,可以在X_test上运行测试(之前的训练过程中,我们将它放在一边)。输入并执行cm,看看模型在新数据上的表现如何。
混淆矩阵
混淆矩阵,顾名思义,表示模型所做的正确和错误预测。当你打算独立地检查哪些预测混淆的时候,混淆矩阵很有用。下图是一个2x2的混淆矩阵的例子。
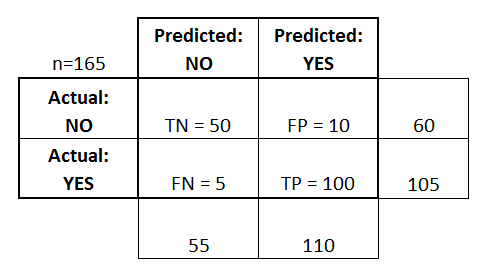
我们的混淆矩阵是这样的。

上面的数字表示:70个正确的否定预测,1个错误的肯定预测,1个错误的否定预测,42个正确的肯定预测。
看到没?混淆矩阵很简单。矩阵的尺寸随分类的类别的增加而增加。
在我们的例子中,我们达到了接近100%的精确度。只有2个错误预测。相当不错。但有时候你可能需要投入更多时间,查探模型的表现,以找到更好、更复杂的解决方案。如果网络的表现不佳,可以通过超参数调优来改进模型。
我希望本文可以帮助你上手Colaboratory。本文配套的Notebook在此(https://colab.research.google.com/notebook#fileId=1aQGl_sH4TVehK8PDBRspwI4pD16xIR0r)。
原文地址:https://towardsdatascience.com/neural-networks-with-google-colaboratory-artificial-intelligence-getting-started-713b5eb07f14

