

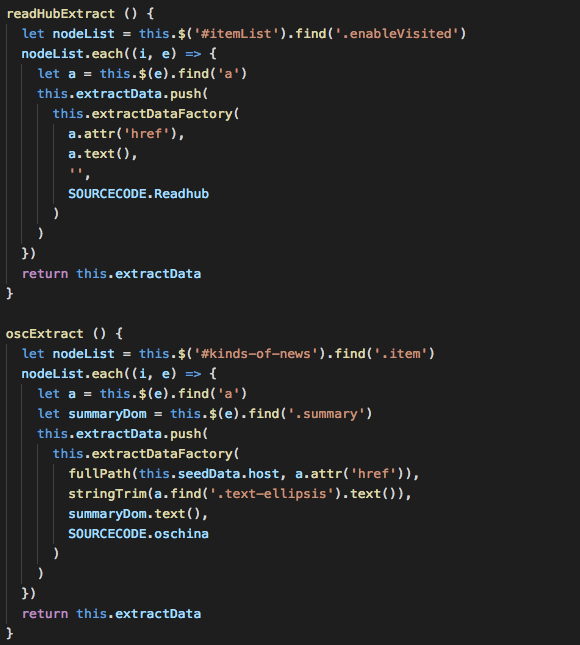
之前写过一篇使用 Node.js 来开发一个资讯爬虫,其中的HTML内容提取使用cheerio设置提取页面元素,如果只需要抓取一个网站那是没有什么问题的,但是如果需要抓取多个网站的话就会产生很多如下面截图逻辑结构差不多的代码,所以就进行了一下优化
达到的效果
根据设置好的数据结构和提取的元素就可以提取对应的数据
数据结构
let obj = {
title: { dom: '.title-link', target: 'text' },
link: { dom: '.title-link', target: 'attr', attrName: 'href' },
content: { dom: '.content-text', target: 'text' }
}
数据结果
[ { title: '我是标题',
link: 'https://juejin.cn',
content: '我是内容' } ]
实现代码
extract () {
// 列表元素
let nodeList = this.$(this.zoneDom).find(this.listDom)
// 列表对象数据提取
nodeList.each((i, e) => {
// 遍历设置好的数据结构,通过dom和target进行数据提取
Object.keys(this.dataDoms).forEach(objEle => {
})
})
}
详细的代码地址:Extract.js
这样就可以啦:)
