

编者按:强化学习是机器学习中的一个领域,它强调如何基于环境而行动,以取得最大化的预期利益。近年来,强化学习的大型研究层见迭出,以AlphaGo为代表的成果不仅轰动了学术界,也吸引了媒体的目光。那么强化学习真的是人工智能的新希望吗?春节期间,软件工程师Alex Irpan引用了过去几年Berkeley、Google Brain、DeepMind和OpenAI的论文,详细介绍了强化学习的弱点和局限。
一次,我在Facebook上发了这样一句话:
每当有人问我强化学习能否解决他们的问题时,我会说“不能”。而且我发现这个回答起码在70%的场合下是正确的。

如今深度强化学习(Deep RL)已经被大量媒体宣传包围。从积极的角度看,强化学习(RL)称得上是万金油,而且它的效果好得令人难以置信,理论上讲,一个强大的、高性能的RL系统应该能解决任何问题。在这基础上,我们把深度学习的思想与之结合起来,这样的尝试是合适的。而且就当前的情况看,Deep RL是最接近AGI的事物之一,它也为吸引了数十亿美元投资的“人工智能梦”提供了助燃剂。
但不幸的是,Deep RL目前还有许多局限。
我相信Deep RL前途无限,如果不是,我也不会选择它作为自己的努力方向。但是说实话,Deep RL还存在很多问题,而且许多问题从根源上就很难解决。表面上人们看到的是仿佛拥有智力的智能体漂亮地完成了任务,但它背后的血汗和泪水只有我们知道。
有好几次,我看到有人被近期的Deep RL工作所吸引,然后毅然投身研究,但他们无一例外地低估了强化学习的深层困难。“玩具问题”并没有他们想象中那么容易,入门强化学习,很可能也就意味着将面对很多次彻底失败,直到那些人在跌倒中学会如何设定现实的研究预期。
我希望能在未来看到更多深层次的RL研究,也希望这个领域能有源源不断的新鲜血液,但是,我也希望这些新人能真正知道他们进入的是一个什么样的世界。
深度强化学习堪忧的采样效率
雅达利游戏是深度强化学习最著名的一个基准。正如Deep Q-Networks论文所示,如果将Q-Learning与合理大小的神经网络,以及一些优化技巧相结合,研究人员可以在几个雅达利游戏中实现人类或超人的表现。
雅达利游戏以每秒60帧的速度运行,那么试想一下,如果要让现在最先进的DQN达到人类表现,它需要多少帧?
答案取决于游戏。我们可以先看看Deepmind近期的一篇论文:Rainbow: Combining Improvements in Deep Reinforcement Learning。这篇论文对原始DQN框架做了一些渐进式改进,证明他们的RainbowDQN性能更优。在实验中,智能体进行了57场雅达利游戏,并在40场中超越了人类玩家。
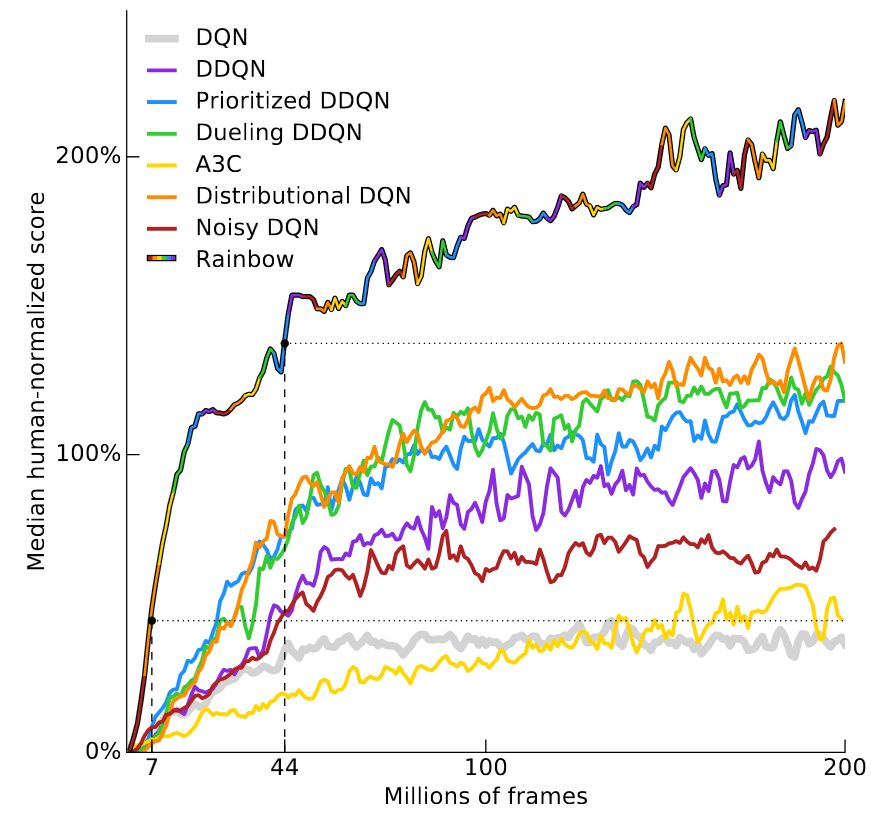
上图的y轴是人类玩家表现的中间得分,研究人员观察了DQN在57场比赛的中的表现,计算了智能体得分情况,之后把人类表现作为衡量指标,绘制出智能体性能曲线。可以看到,RainbowDQN曲线的纵轴在1800万帧时突破100%,也就是超越人类。这相当于83个小时的游戏时间,其中包括训练用时和真实游戏用时,但在大多数时候,人类玩家上手雅达利游戏可能只需要短短几分钟。
需要注意的是,相比较Distributional DQN(橙线)的7000万帧,其实RainbowDQN1800万的成绩称得上是一个不小的突破。要知道就在三年前,Nature刊登了一篇强化学习论文,其中介绍了原始DQN(黄线),而它在实验中的表现是在2亿帧后还无法达到100%。
诺贝尔奖获得者Kahneman和Tversky曾提出一个概念:规划谬误(planning fallacy)。它指的是人们对于完成某件事会持乐观心里,因此低估任务完成时间。Deep RL有其自身的规划谬误——学习策略需要的样本往往比事先预想的多得多。
事实上雅达利游戏并不是唯一的问题。强化学习领域另一个颇受欢迎的基准是MuJoCo基准测试,这是MuJoCo物理模拟器中的一组任务。在这些任务中,系统的输入通常是某个模拟机器人每个关节的位置和速度。但即便是这么简单的任务,系统通常也要经过105—107个步骤才能完成学习,它所需的经验量大得惊人。
下面演示的是DeepMind的跑酷机器人,研究人员在论文Emergence of Locomotion Behaviours in Rich Environments中介绍称实验用了64名worker和100小时,虽然他们并没有解释worker是什么,但我认为一个worker就相当于一个CPU。
DeepMind的成果很棒,这个视频刚发布时,我还因强化学习能让机器人学会跑步惊讶了许久。但在看过论文后,6400小时的CPU耗时还是有点令人沮丧。这不是说我认为它耗时过久,而是Deep RL的实际采样效率还是比预想的高了几个数量级,这一点更让人失望。
这里有一个问题:如果我们忽略采样效率,后果会怎样?如果只是为了获取经验,有时我们只需要调整几个参数就能做到,游戏就是一个很典型的例子。但是如果这个做法不管用了,那强化学习就会陷入艰难的境地。不幸的是,大多数现实世界的任务属于后者。
如果只关心最终性能,其他方法效果更好
在为研究课题寻找解决方案时,研究人员往往要做出“抉择”。一方面,他们可以只关心问题的完成效果,即优化一种性能最佳的方法;另一方面,他们也可以参考前人的成果,优化一种科研价值更高的方法,但它的最终效果不一定是最好的。理想的情况是兼顾性能最优和贡献最大,但鱼与熊掌不可兼得,这样的研究课题可遇不可求。
谈及更好的最终效果,Deep RL的表现有些不尽如人意,因为它实际上是被其他方法吊打的。下面是MuJoCo机器人的一个视频,通过在线轨迹优化控制,系统可以近乎实时地在线进行计算,而无需离线训练。需要提一点的是,这是2012年的成果。
这个视频刚好可以拿来和跑酷视频相比。两篇论文最大的不同在于这篇论文使用的是模型预测控制,它可以针对地面实况世界模型(物理模拟器)进行规划,而不构建模型的强化学习系统没有这个规划的过程,因此学习起来更困难。换句话说,如果直接针对某个模型进行规划效果更好,那我们为什么还要花精力去训练RL策略?
同样的,现成的蒙特卡洛树搜索在雅达利游戏中也能轻松超越DQN。2014年,密歇根大学的论文Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning被NIPS收录,它研究的是在实时Atari游戏使用离线蒙特卡洛树搜索的效果。如下图所示,研究人员把DQN的得分和UCT(UCT是如今MCTS的标准版本)智能体的得分相比较,发现后者的性能更加优秀。


需要注意的是,这又是一次不公平的对比,因为DQN不能搜索,而MCTS可以根据地面实况模型(雅达利模拟器)执行搜索。但是这种程度的不公平有时是不重要的,如果你只想得到一个好结果的话。
强化学习理论上可以用于任何事情,包括世界模型未知的环境。然而,这种通用性也是有代价的,就是我们很难把它用于任何有助于学习的特定问题上。这迫使我们不得不需要使用大量样本来学习,尽管这些问题可能用简单的编码就能解决。
因此除少数情况外,特定领域的算法会比强化学习更有效。如果你入门强化学习是出于对它的热爱,这没问题,但当你想把自己的强化学习成果和其他方法相比较时,你要做好心理准备。此外,如果你还对机器人这个问题感到费解,比如Deep RL训练的机器人和经典机器人技术制作的机器人的差距究竟有多大,你可以看看知名仿生机器人公司的产品——如波士顿动力。

这个双足机器人Atlas没有用到任何强化学习技术,阅读他们的论文可以发现,它用的还是time-varying LQR、QP solvers和凸优化这些传统手段。所以如果使用正确的话,经典技术在特定问题上的表现会更好。
强化学习通常需要奖励
强化学习的一个重要假设就是存在奖励,它能引导智能体向“正确”的方向前进。这个奖励函数可以是研究人员设置的,也可以是离线手动调试的,它在学习过程中一般是一个固定值。之所以说“一般”,是因为有时也有例外,如模仿学习和逆RL,但大多数强化学习方法都把奖励视为“预言”。
更重要的是,为了让智能体做正确的事,系统的奖励函数必须准确捕捉研究人员想要的东西。注意,是准确。强化学习有一种恼人的倾向,就是如果设置的奖励过度拟合你的目标,智能体会容易钻空子,产生预期外的结果。这也是雅达利游戏是一个理想基准的原因,因为游戏不仅能提供大量样本,每场比赛的目标都是最大限度地提高得分,所以我们不用担心怎么定义奖励。
同样的,MuJoCo由于是在在模拟中运行的,所以我们对目标的所有状态了如指掌,奖励函数容易设计,这也是它广受欢迎的主要原因。

上图是Reacher任务,我们需要控制连接到中心点(蓝点)的这个手臂,让手臂末端(橙点)与红色目标物重合。由于所有位置都是已知的,我们可以把奖励定义为手臂末端到目标的聚集,再加上一个小的控制成本。理论上,如果传感器足够灵敏,我们完全可以把这个任务放到现实环境中实现。但一旦涉及通过解决这个问题我们想让系统做什么,任务的奖励就很难设计了。
当然,就其本身而言,有奖励函数并不是什么太大的问题,但是它之后会造成一些连锁反应。
奖励函数设计困难
设置一个回报函数不是什么难事,但当你试图设计一个奖励函数来鼓励想要的行动,同时仍想让智能体不断学习时,困难就随之而来了。
在HalfCheetah环境中,我们有一个受限于一个垂直平面的双足机器人,这意味着它只能向前或向后运动。

机器人的目标是学会跑步步态,奖励是速度。这是一种形式化的奖励,机器人越接近奖励目标,系统给予的奖励就越多。这和稀疏奖励形成鲜明对比,因为这种奖励只在目标状态下给予奖励,在其他任何地方则没有奖励。这种形式化的奖励通常更容易促进学习,因为即使策略没有找到解决问题的完整解决方案,它们也能提供积极的反馈。
不幸的是,形式化的奖励也可能会影响学习效果。如前所述,它可能会导致机器人动作与预期不符。一个典型的例子是OpenAI的博文Faulty Reward Functions in the Wild,如下图所示,这个赛艇游戏的预定目标是完成比赛。你可以想象,一个稀疏的奖励会在给定的时间内给予+1奖励,否则奖励为0。研究人员在这个游戏中设置了两种奖励,一是完成比赛,二是收集环境中的得分目标。最后OpenAI的智能体找到了一片“农场”反复刷分,虽然没能完成比赛,但它的得分更高。

说实在的,这篇文章刚发布时,我有点气愤,因为这并不是强化学习的问题,而是奖励设置的问题。如果研究人员给出了奇怪的奖励,强化学习的结果肯定也是奇怪的。但在写这篇文章时,我发现这样一个吸睛力很强的错误案例也很有用,因为每次提到这个问题,这个视频就能被拿来做演示。所以基于这个前提,我会勉强承认这是篇“不错”的博客。
强化学习算法关注的是一个连续统一的过程,它假设自己或多或少地了解现在所处的环境。最广泛的无模型强化学习和黑盒优化技术差不多,它只允许假设存在于MDP中,也就是智能体只会被简单告知这样做可以获得奖励+1,至于剩下的,它得自己慢慢摸索。同样的,无模型强化学习也会面临和黑盒优化技术一样的问题,就是智能体会把所有奖励+1都当做是积极的,尽管这个+1可能是走了邪门歪道。
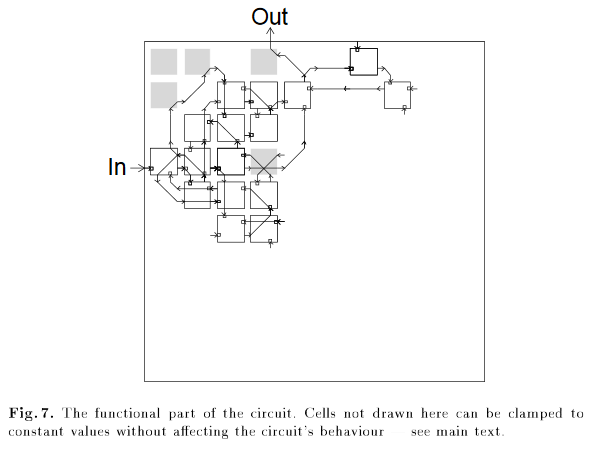
一个典型的非强化学习例子是有人把遗传算法应用到电路设计中,并得到了一幅电路图。在这个电路中,最终设计需要一个不连接的逻辑门。
更多相关研究可以看Salesforce2017年的博客,他们研究的方向是自动生成文字摘要。他们把基准模型用监督学习进行训练,然后使用一种名为ROUGE的自动化度量进行评估。ROUGE是不可微的,但强化学习可以处理其中的非微分奖励,因此他们也尝试着直接用强化学习来优化ROUGE。虽然实验效果不错,但文章并没有给出详细总结,以下是一个例子:
Button denied 100th race start for McLaren after ERS failure. Button then spent much of the Bahrain Grand Prix on Twitter delivering his verdict on the action as it unfolded. Lewis Hamilton has out-qualified and finished ahead of Mercedes team-mate Nico Rosberg at every race this season. Bernie Ecclestone confirms F1 will make its bow in Azerbaijan next season.
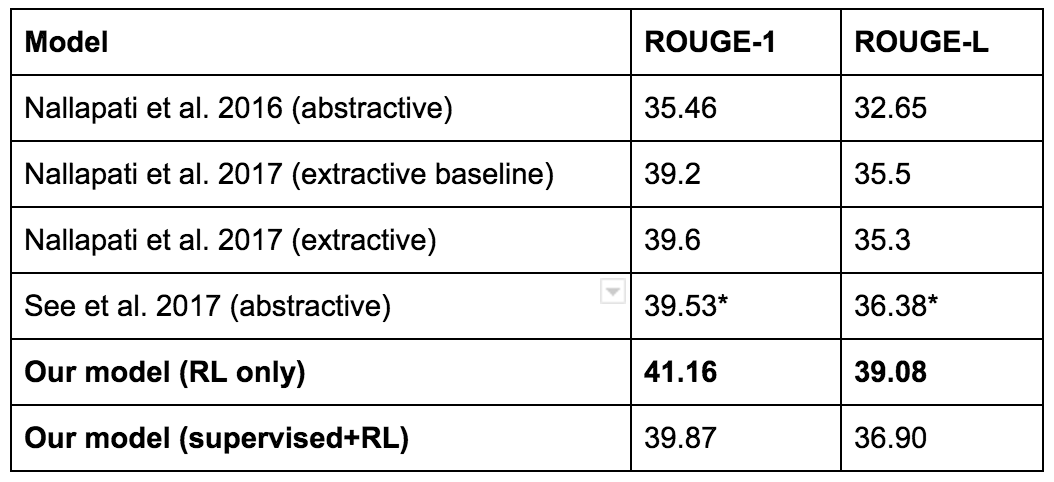
尽管强化学习模型评分最高,但是他们最后还是用了别的模型……
另一个有趣的例子是2017年波波夫等人的“乐高堆叠”论文。研究人员用分布式的DDPG来学习掌握学习策略,在他们的实验中,机器人的目标是抓住红色乐高积木,并把它堆叠到蓝色积木上方。

他们的研究总体上取得了成功,但也存在一些失败的地方。对于一开始的提升动作,研究人员设置的奖励是红色积木的高度,也就是红色积木底面的z轴数值,在学习过程中,机器人发现简单地把积木翻转过来,凸点面朝下,也能获得相当的奖励。
解决这一问题的方法是把奖励变得稀疏,只在机器人把积木堆叠起来后再给予回报。当然,有时候这是有效的,因为稀疏的奖励也可以促进学习。但一般情况下,这种做法并不可取,因为积极奖励的缺乏会让学习经验难以稳固,从而训练困难。另一种解决方法则是更小心地设置奖励,增加新的奖励条件或调整现有的奖励系数,直到机器人不再走任何捷径。但这种做法本质上是人脑和强化学习的博弈,是一场无情的战斗,虽然有时候“打补丁”是必要的,但是我从来没有觉得自己能从中学到什么。
如果你不信,可以看看“乐高堆叠”的奖励函数做个参考:
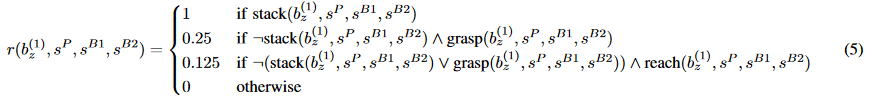
我不知道他们在设计这个奖励上花了多少时间,但是根据条件数量和不同系数的数量,我猜测这个数值会“很高”。
在与其他强化学习方向的研究人员交流时,我也听到了许多关于不当奖励设置的轶事:
-
某人正在训练机器人室内导航。如果智能体走出“房间”,情节就会终止,系统判定机器人为“自杀”,不会有任何负面奖励。训练到最后,机器人几乎每次都选择“不活了”,因为积极奖励太难获取,而负面奖励又异常丰富,对它来说,0奖励快速终止是一种更可取的方法。
-
某人正在训练一个模拟机器人手臂,以让它达到桌面上的一个点。这个实验出现问题的关键在于有没有定义桌子,这是个移动的桌子还是被固定在某地的桌子。经过长时间训练,智能体习得的最佳策略是猛砸桌子,使桌子翻倒并让目标点自动滚到手臂末端。
-
某人正在训练让机器人用锤子锤钉子。刚开始的时候,他们定义的奖励是钉子推入洞孔的距离,因此机器人完全忽视了锤子,而是用四肢不断敲打钉子。后来,他们增加了一些奖励条件,如鼓励机器人拿起锤子,重新训练后,机器人学会了捡起锤子,但它又马上扔掉了,继续用四肢敲敲打打。
不可否认,这些都是道听途说,并没有现成的视频或论文佐证,但以我多年被强化学习“坑害”的经验来看,它们都合情合理。我也认识那些喜欢谈论诸如“回形针产量最大化”故事的人,我真的理解他们的恐惧,但像这样通过假想超现实的AGI来编造一起“毁灭人类”故事的套路实在令人心生厌烦。尤其是当上述这些傻乎乎的案例一次次地出现在我们面前。
最合理的奖励也不能避免局部最优
之前的这些强化学习案例被称为“奖励黑客”(reward hacking),对我而言,这其实就是一个聪明的开箱即用解决方案,智能体最终能获得比研究者预期值更多的奖励。当然,奖励黑客其实只是一些例外,强化学习中更常见的问题是因为“获取观察值—采取行动”这一流程出现错误,导致系统得到局部最优解。
下图是一个HalfCheetah环境中的Normalized Advantage Function的实现,它很典型:

从旁观者的角度看,这个机器人有点傻。但我们也只能评论它“傻”,因为我们站在上帝视角,并且拥有大量先验知识。我们都知道用脚跑步更合理,但是强化学习不知道,它看到的是一个状态向量、自己即将采取的动作向量,以及之前获得的奖励而已。
在学习过程中,智能体是这么想的:
-
在随机探索过程中,前进策略不站着不动更好;
-
自己可以一直持续这种行为,所以保持前进状态;
-
策略实施后,如果一下子用更大的力,自己会做后空翻,这样得分更高;
-
做了足够多的后空翻后,发现这是一个刷分的好主意,所以把后空翻纳入已有策略中;
-
如果策略持续倒退,哪一种会更容易?是自我修正然后按“标准方式”运行,还是学会在仰卧时用背部前进?选择后者。
这之中的思路很有趣,但决不是研究人员所期待的。
另一个失败案例来自我们之前提到过的Reacher。

在这个任务中,最初的随机权重会倾向于输出高度正面或者高度负面的动作输出,也就是大部分动作会输出最大或最小的加速度。这就出现一个问题,就是这个连杆机械臂一不小心就会高速旋转,只要在每个关节输入最大力,它就会转得完全停不下来。在这种情况下,一旦机器人开始训练,这种没有多大意义的状态会使它偏离当前策略——为了避免这种情况的发生,你必须实现做一些探索来阻止不停旋转。虽然理论上这是可行的,但是动图中的机器人没能做到。
这些就是经典的探索—利用困境(exploration-exploitation dilemma),它是困扰强化学习的一个常见问题:你的数据来源于你当前的策略,但如果当前策略探索得过多,你会得到一大堆无用数据并且没法从中提取有效信息。而如果你进行过多的尝试(利用),那你也无法找到最佳的动作。
对于解决这个问题,业内有几个直观而简便的想法:内在动机、好奇心驱动的探索和基于计数的探索等。这些方法中有许多早在20世纪80年代以前就被提出,其中的一些方法甚至已经被用深度学习模型进行过重新审视,但它们并不能在所有环境中都发挥作用。我一直在期待一种通用型更强的探索技巧,相信在之后的几年内,行业内就能给出更好的答案。
我曾把强化学习想象成一个满怀恶意的对象,它故意曲解你的奖励,之后再积极寻找最偷懒的局部最优解。虽然听起来有点荒谬,但这实际上还是一个蛮贴切的形容。
Deep RL起作用时,它可能只是过度适应环境中的怪异模式
强化学习是受欢迎的,因为它是唯一一个可以只在测试集上进行训练的机器学习网络。
强化学习的一个好处在于,如果你想在一个环境中表现更好,你可以疯狂地过拟合。但是这样做的缺点是这个系统只在特定任务中起作用,如果你想扩展到其他环境,对不起做不到。
DQN可以解决很多雅达利游戏问题,但它的做法是把所有学习中在一个目标上——在一个游戏中获得非常出色的效果,因此它的最终模型不适用于其他游戏。你可以微调参数,让已经训练好的模型适应新的游戏(论文:Progressive Neural Networks),但你并不能保证它能转化,而且人们一般不指望它能转化。因为从预训练的ImageNet图像来看不是很有效。
当然,有些人对此会持不同想法。的确,原则上来说如果在广泛分布的环境中训练,模型应该能避免这些问题,导航就是一个例子,您可以随机抽样目标位置,并使用通用值函数进行概括(Universal Value Function Approximators)。我觉得这项工作非常有前途,稍后会给出更多这方面的例子,但是,我依然认为Deep RL的泛化能力不足以处理多种任务。虽然它的“感知”更敏锐了,但它还没有到达“用于控制ImageNet”的水平,OpenAI Universe试图挑战这一点,但它现在还有诸多局限。
在高度泛化的Deep RL到来之前,我们现在面对的还是适应面十分狭小的学习策略。对此,我参与的论文Can Deep RL Solve Erdos-Selfridge-Spencer Games?可以提供一个合适的案例。我们研究的是一个双人组合的玩具游戏,它只有一个封闭式的解决方案来获得最佳成果。在第一个实验中,我们保持玩家1不变,并用强化学习算法训练玩家2,这实际上是把玩家1作为环境的一部分。通过玩家2和玩家1的对抗,最后我们得到了最佳性能的玩家2。但当我们反过来训练玩家1时,我们却发现它的表现越来越差,因为它只会对抗最佳的玩家2,而不会对抗非最佳的其他情况。
Marc Lanctot等人被NIPS 2017收录的论文A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning也展示了类似的结果。下图中有两个智能体正在玩laser tag(激光枪游戏),它们的训练方式是多智能体的强化学习。为了检测系统的通用性,研究人员用5个种子随机生成的智能体进行游戏,以下是固定一个玩家,并用强化学习训练另一个玩家的结果:

可以发现,玩家1和玩家2相互靠近,并朝对方射击。之后,研究人员把这个实验中的玩家1放进另一个实验去对抗玩家2。训练结束后,理论上应该学会所有对抗策略的玩家们却变成了这样:

这似乎是多智能体强化学习的一个特点:当智能体互相训练时,他们会共同进化;智能体善于对抗,但当它是和一个看不见的对手一起训练时,它的性能则会下降。以上两张动图用了相同的学习算法、相同的超参数,它们的唯一区别是前者用了随机种子,它的发散行为完全来自初始条件下的随机性。
话虽如此,这类竞争游戏环境也有一些看似矛盾的结果。OpenAI的这篇博客Competitive Self-Play介绍了他们在这方面的研究进展,自我博弈也是AlphaGo和AlphaZero的重要组成部分。对此我的猜想是,如果智能体以同样的速度学习,它们可以互相对抗彼此并加速自己进化,但是,如果其中一方学习速度较快,它就会过多利用较落后的另一方并导致过拟合。这看似容易解决,但当你把对称博弈改成一般的多智能体对抗时,你就知道确保相同的学习速率有多困难。
Deep RL不稳定,结果难以重现
超参数会影响学习系统的行为,它几乎存在于所有机器学习算法中,通常是手动设置或随机搜索调试的。监督学习是稳定的:固定的数据集、实时目标。如果你稍微改变超参数,它不会对整个系统的性能造成太大影响。虽然超参数也有好有坏,但凭借研究人员多年来积累的经验,现在我们可以在训练过程中轻松找到一些反映超参数水平的线索。根据这些线索,我们就能知道自己是不是已经脱离正轨,是该继续训练还是回头重新设计。
但是目前Deep RL还很不稳定,这也成了制约研究的一个瓶颈。
刚进Google Brain时,我做的第一件事是根据NAF算法论文重现他们的算法。我想着自己能熟练使用Theano(方便转成TensorFlow),也有不少Deep RL经历,论文的一作也在Google Brain,我可以随时向他请教,这样的天时地利人和,2—3周应该就能搞定了吧。
但事实证明,我花了6周时间才重现了他们的结果。失败的原因主要是一些软件bug,但重点是,为什么要这么长时间?
对于这个问题,我们可以先看OpenAI Gym中最简单的任务:Pendulum。Pendulum有一个锚点固定在一点上的钟摆,向摆锤施加力后它会摆动起来。它的输入状态是三维的(钟摆的位置和速度),动作空间是一维的(向摆锤施加的力),我们的目标是完美平衡钟摆。它的实现方法很简单,既然要让钟摆接近垂直(倒立),那我们就可以针对钟摆和垂直方向的夹角来设置奖励:夹角越小,奖励越高。由此可知奖励函数是凹形的。

下图是我修正所有bug后得到的一张性能曲线图,每一条线都是独立跑了10次计算出来的,它们用了同样的超参数,但随机种子不同。
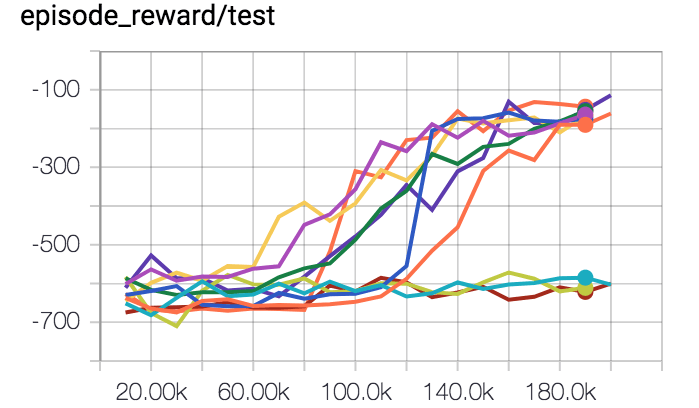
可以发现,10个actor中只有7个起作用了。其实30%的失败率也还算正常,让我们来看Variational Information Maximizing Exploration这篇论文的结果,他们的环境是HalfCheetah,奖励稀疏,图中y轴是episode奖励,x轴是时间步长,使用的算法是TRPO。
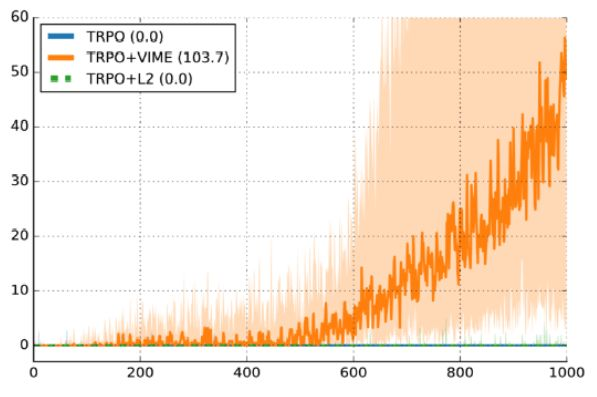
深色曲线是10个随机种子的表现中值,阴影部分则表示25%—75%。首先要声明一点,这张图是支持VIME的一个很好的论据,但就是这样一个表现非常好的实验,它在25%的时间内奖励一直接近0,也就是有25%的失败率,而且原因仅仅是因为随机种子。
所以虽然监督学习很稳定,但在少数情况下它也有例外。如果我的监督学习代码有30%的概率不能击败随机情况,那我可以确信是代码出了问题。但是如果这是强化学习,那我就不知道这些bug是因为超参数还是只是因为我脸不好。
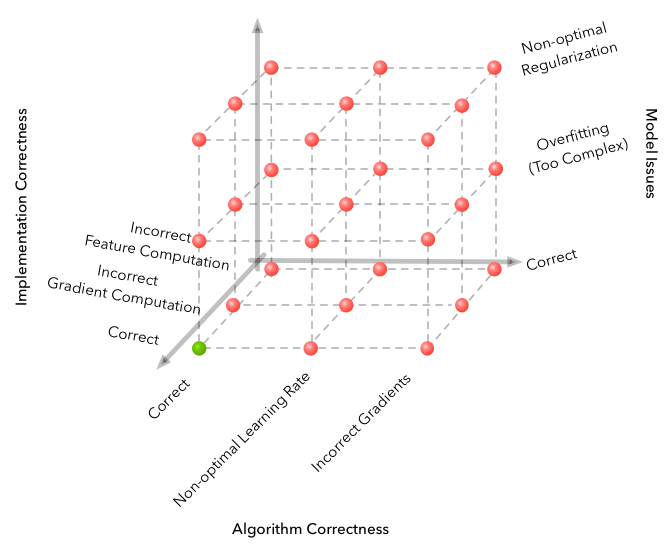
上图来自一篇文章“为什么机器学习这么难?”,作者的核心观点是机器学习会为失败案例空间增加许多维度,这些维度进一步丰富了失败的种类方式。而Deep RL的在强化学习基础上又增加了一个“随机”的新维度,它的唯一应对之法就是在问题上投入更多的实验来减少噪声数据。
之前提到了,Deep RL算法原本就存在采样效率低、训练结果不稳定等问题,随机维度无疑是雪上加霜,会大大降低最后的成果率。也许原本我们只要跑100万步,但乘上5个随机种子,再加上超参数调整后,光是检验假设我们都要爆炸级的计算量。
Andrej Karpathy还在OpenAI时曾经说过这样一段话:
给你一个安慰。我之前在处理一系列强化学习问题时,要花50%的时间,也就是差不多6周重新建立策略梯度。那会儿我已经干这行很久了,还有一个GPU阵列可以用,而且还有一大帮关系很好的经验老道的专家朋友可以天天见面。
我发现对于强化学习这个领域,自己从监督学习上学到的所有关于CNN的设计理论好像都没什么用。什么credit assignment、supervision bitrate,完全没有用武之地;什么ResNets、batchnorms、深层网络,完全没有话语权。
在监督学习里,如果我们想要实现什么,即使最后做的很糟糕,我们还是能总结一些非随机性的东西。但是强化学习不是这样的,如果函数设计错了,或者超参数没调好,那最后的结果可能比随机生成的都差。而且就是因为它是强化学习,即使一切条件都很完美,我们还会有30%的失败率。
简而言之,你的失败不是因为选了神经网络这条路,而是因为选了Deep RL这条不归路。
随机种子就像放入矿坑检查气体是否有毒的金丝雀,它尚且能导致这样大的差异,那么如果我们的代码出现偏差,最后的结果可想而知……当然,一个好消息是,我们不用自己绞尽脑汁想象,因为有人帮我们想好了—— Deep Reinforcement Learning That Matters。他们给出的结论是:
-
将奖励和常数相乘可能会对性能造成显著影响;
-
5个随机种子(论文常用标准)可能不足以说明问题,因为仔细筛选后可以得到非重叠的置信区间;
-
即使使用全部相同的超参数、算法,不同实现在解决同一任务时也会出现性能不一的情况。
我对此的看法是,强化学习对初始化过程和训练过程中发生的变化非常敏感,因为所有数据都是实时收集的,而我们唯一可以监控的指标——奖励,是一个标量。随机表现出色的策略会比随机不适用的策略更快地被启用,而好的策略如果没能及时给出优秀案例,那强化学习会贸然断定它的所有表现都是差的。
Deep RL的落地应用
不可否认,Deep RL现在看起来是一个非常cool的领域,尤其是在新闻宣传方面。试想一下,单个模型只用原始图像就能学习,还无需为每个游戏单独调整,再想想AlphaGo和AlphaZero,是不是到现在还有点小激动?
但是,除了这几个成功的案例,我们很难再找到其他具有现实价值的Deep RL应用案例。
我也考虑过如何把Deep RL技术用于现实生活,生活的、生产的,最后发现实现起来太过困难。最后,我只找到两个看起来有点前途的项目——一个是降低数据中心耗电量,另一个则是最近刚提出的AutoML Vision工作。两个都是谷歌的项目,但OpenAI之前也提出过类似后者的东西。
据我所知,奥迪也在尝试强化学习方面的探索,他们在NIPS上展示了一辆自动驾驶汽车,据说使用了Deep RL技术。另外也有基于Deep RL的文本摘要模型、聊天机器人、广告投放,但一旦涉及商用,即便真的已经做到了,现在他们也会“理智”地选择沉默。
所以Deep RL现在还只是一个狭窄的、比较热门的研究领域,你可以猜测大公司存在什么商业阴谋,但作为业内人士,我觉得这个的可能性不大。
展望未来
学术圈有句老话——每个科研人员都必须学会如何憎恨自己研究的领域。它的梗在于大多数科研人员是出于热情和兴趣从事这项工作的,他们不知疲倦。
这大概也是我在研究强化学习过程中的最大体验。虽然只是我个人的想法,但我依然觉得我们应该把强化学习扩展到更丰富的领域,甚至到那些看起来没有应用空间的问题上。我们应该把强化学习研究得更透彻。
以下是我认为有助于Deep RL实现进一步发展的一些条件:
-
易于产生近乎无限的经验;
-
把问题简化称更简单的形式;
-
将自我学习引入强化学习;
-
有一个清晰的方法来定义什么是可学习的、不可取消的奖励;
-
如果奖励必须形成,那它至少应该是种类丰富的。
下面是我列出的一些关于未来研究趋势的合理猜测 ,希望未来Deep RL能带给我们更多惊喜。
-
局部最优就足够了。 我们一直以来都追求全局最优,但这个想法会不会有些自大呢?毕竟人类进化也只是朝着少数几个方向发展。也许未来我们发现局部最优就够了,不用盲目追求全局最优;
-
代码不能解决的问题,硬件来。 我确信有一部分人认为人工智能的成就源于硬件技术的突破,虽然我觉得硬件不能解决所有问题,但还是要承认,硬件在这之中扮演着重要角色。机器运行越快,我们就越不需要担心效率问题,探索也更简单;
-
添加更多的learning signal。 稀疏奖励很难学习,因为我们无法获得足够已知的有帮助的信息;
-
基于模型的学习可以释放样本效率。 原则上来说,一个好模型可以解决一系列问题,就像AlphaGo一样,也许加入基于模型的方法值得一试;
-
像参数微调一样使用强化学习。 第一篇AlphaGo论文从监督学习开始,然后在其上进行RL微调。这是一个很好的方法,因为它可以让我们使用一种速度更快但功能更少的方法来加速初始学习;
-
奖励是可以学习的。 如果奖励设计如此困难,也许我们能让系统自己学习设置奖励,现在模仿学习和反强化学习都有不错的发展,也许这个思路也行得通;
-
用迁移学习帮助提高效率。 迁移学习意味着我们能用以前积累的任务知识来学习新知识,这绝对是一个发展趋势;
-
良好的先验知识可以大大缩短学习时间。 这和上一点有相通之处。有一种观点认为,迁移学习就是利用过去的经验为学习其他任务打下一个良好的基础。RL算法被设计用于任何马尔科夫决策过程,这可以说是万恶之源。那么如果我们接受我们的解决方案只能在一小部分环境中表现良好,我们应该能够利用共享来解决所有问题。之前Pieter Abbeel在演讲中称Deep RL只需解决现实世界中的任务,我赞同这个观点,所以我们也可以通过共享建立一个现实世界的先验,让Deep RL可以快速学习真实的任务,作为代价,它可以不太擅长虚拟任务的学习;
-
难与易的辨证转换。 这是BAIR(Berkeley AI Research)提出的一个观点,他们从DeepMind的工作中发现,如果我们向环境中添加多个智能体,把任务变得很复杂,其实它们的学习过程反而被大大简化了。让我们回到ImageNet:在ImageNet上训练的模型将比在CIFAR-100上训练的模型更好地推广。所以可能我们并不需要一个高度泛化的强化学习系统,只要把它作为通用起点就好了。
原文地址:www.alexirpan.com/2018/02/14/rl-hard.html

