

Spark Streaming VS Storm
| 对比点 | Storm | Spark Streaming |
|---|---|---|
| 实时计算模型 | 纯实时,来一条数据,处理一条数据 | 准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
| 实时计算延迟度 | 毫秒级 | 秒级 |
| 吞吐量 | 低 | 高 |
| 事务机制 | 支持完善 | 支持,但不够完善 |
| 健壮性 / 容错性 | ZooKeeper,Acker,非常强 | Checkpoint,WAL,一般 |
| 动态调整并行度 | 支持 | 不支持 |
要求纯实时,强大可靠的事务机制,动态调整并行度(高峰期),可以使用Storm
Spark Streaming的优点在于和spark体系的整合
Spark Streaming注意点
- 只要一个StreamingContext启动之后,就不能再往其中添加任何计算逻辑了。
- 一个StreamingContext停止之后,是肯定不能重启的。调用
stop()之后,不能再调用start() - 一个JVM同时只能有一个StreamingContext启动(和SparkContext一样)。在应用程序中,不能创建两个StreamingContext。
- 调用
stop()方法时,会同时停止内部的SparkContext,如果希望后面继续使用SparkContext创建其他类型的Context,比如SQLContext,可以用stop(false)。 - 一个SparkContext可以创建多个StreamingContext,只要上一个先用
stop(false)停止,再创建下一个即可。
DStream和Receiver
除了文件数据流之外,所有的输入DStream都会绑定一个Receiver对象,Receiver用来从数据源接收数据,并将其存储在Spark的内存中,以供后续处理。
Receiver是一个长时间在executor中运行的任务,一个Receiver会独占一个cpu core,必须保证分配给Spark Streaming的每个executor分配的core>1,保证分配到executor上运行的输入DStream,有两条线程并行,一条运行Receiver接收数据;一条处理数据。否则的话,只会接收数据,不会处理数据。
receiver在 blockInterval 毫秒生成一个新的数据块,总共创建 N = batchInterval/blockInterval的数据块,并由当前 executor 的 BlockManager 分发给其他执行程序的 block managers,所有这些块组成一个RDD(在 batchInterval 期间生成的块是 RDD 的 partitions)
实时读取HDFS文件流
监控一个HDFS目录,只要其中有新文件出现,就实时处理,相当于处理实时的文件流。
Spark Streaming会监视指定的HDFS目录,并且处理出现在目录中的文件。
- 所有放入HDFS目录中的文件,都必须有相同的格式;
- 必须使用移动或者重命名的方式,将文件移入目录;
- 一旦处理之后,文件的内容即使改变,也不会再处理了;
- 基于HDFS文件的数据源是没有Receiver的,因此不会占用一个cpu core。
Receiver-Kafka数据源
默认receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理数据。这种方式可能会因为底层的失败而丢失数据
启用高可靠机制,让数据零丢失,可以启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中
-
Kafka中的topic的partition,与Spark中的RDD的partition是没有关系的。所以在
KafkaUtils.createStream()中,提高partition的数量,只会增加一个Receiver中,读取partition的线程的数量。不会增加Spark处理数据的并行度。 -
可以创建多个Kafka输入DStream,使用不同的consumer group和topic,来通过多个receiver并行接收数据。
-
如果基于容错的文件系统,比如HDFS,启用了预写日志机制,接收到的数据都会被复制一份到预写日志中。因此,在
KafkaUtils.createStream()中,设置的持久化级别是StorageLevel.MEMORY_AND_DISK_SER。
自定义Receiver
实现以下两个方法:onStart()、onStop()
onStart()和onStop()方法必须不能阻塞数据,onStart()方法会启动负责接收数据的线程,onStop()方法会确保之前启动的线程都已经停止了。
负责接收数据的线程可以调用isStopped()方法来检查它们是否应该停止接收数据。
一旦数据被接收,就可以调用store(data)方法将数据存储在Spark内部。可以将数据
每次一条进行存储,或是每次存储一个集合或序列化的数据。
接收线程中的任何异常都应该被捕获以及正确处理,从而避免receiver的静默失败。restart()方法会通过异步地调用onStop()和
onStart()方法来重启receiver。stop()方法会调用onStop()方法来停止receiver。reportError()方法会汇报一个错误消息给driver,但是不停止或重启receiver。
官方说明Spark Streaming Custom Receivers
Direct数据源
这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据
优点:
-
简化并行读取
如果要读取多个partition,不需要创建多个输入DStream然后对它们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据。所以在Kafka partition和RDD partition之间,有一个一对一的映射关系如果不使用Direct数据源,那么一个partition对应一个DStream,一个DStream对应一个receiver,一个receiver对应一个cpu core. 数据源通常会在多个partition中,就会使用多个receiver,消耗多个cpu core
-
高性能
如果要保证零数据丢失,在基于receiver的方式中,需要开启WAL机制。这种方式其实效率低下,因为数据实际上被复制了两份,Kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中
基于direct的方式,不依赖Receiver,不需要开启WAL机制,只要Kafka中作了数据的复制,那么就可以通过Kafka的副本进行恢复。避免重复备份
-
一次且仅一次的事务机制
基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的
基于direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据是消费一次且仅消费一次
DStream的transformation操作
| Transformation | Meaning |
|---|---|
| transform | 对数据进行转换操作 |
| updateStateByKey | 为每个key维护一份state,并进行更新 |
| window | 对滑动窗口数据执行操作 |
updateStateByKey
updateStateByKey操作,可以为每个key维护一份state,并持续不断地更新该state
对于每个batch,Spark都会为每个之前已经存在的key去应用一次state更新函数,无论这个key在batch中是否有新的数据。如果state更新函数返回none,那么key对应的state就会被删除。
进行updateStateByKey、window等有状态的操作时,spark会自动进行checkpoint,必须开启Checkpoint机制
val ssc = new StreamingContext(spark.sparkContext,Seconds(1))
//必须checkpoint
ssc.checkpoint("hdfs://spark1:9000/checkpoint")
val lines = ssc.socketTextStream("spark1", 9999)
val words = lines.flatMap { _.split(" ") }
val pairs = words.map { word => (word, 1) }
//不是按批次,而是按全局数据处理
val wordCounts = pairs.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
//state缓存的数据
var newValue = state.getOrElse(0)
//values新进的一批数据,可能有多个key值相等的
for(value <- values) {
newValue += value
}
//如果state更新函数返回none,那么key对应的state就会被删除
Option(newValue)
})
wordCounts.print()
//上面仅仅设置了计算,只有在启动时才会执行,并没有开始真正地处理
// 真正开始计算
ssc.start()
// 等待计算被中断
ssc.awaitTermination()
Transform
transform操作,应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作。可以用于实现DStream API中所没有提供的操作
val transformedDStream = DStream.transform(xxxRDD => {
//当做rdd使用
...
})
window滑动窗口
每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作
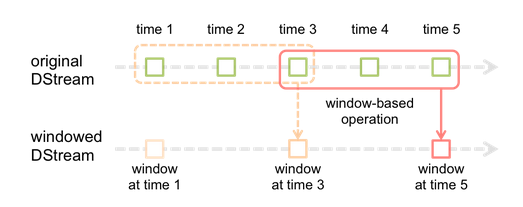
//每隔10s,将最近60s的数,执行reduceByKey操作
val searchWordCountsDSteram = searchWordPairsDStream.reduceByKeyAndWindow(
(v1: Int, v2: Int) => v1 + v2,
Seconds(60),
Seconds(10))
| Transform | 意义 |
|---|---|
| window | 对每个滑动窗口的数据执行自定义的计算 |
| countByWindow | 对每个滑动窗口的数据执行count操作 |
| reduceByWindow | 对每个滑动窗口的数据执行reduce操作 |
| reduceByKeyAndWindow | 对每个滑动窗口的数据执行reduceByKey操作 |
| countByValueAndWindow | 对每个滑动窗口的数据执行countByValue操作 |
DStream output操作
| Output | Meaning |
|---|---|
| 打印每个batch中的前10个元素,主要用于测试,或者是用于简单触发一下job。 | |
| saveAsTextFile(prefix, [suffix]) | 将每个batch的数据保存到文件中。每个batch的文件的命名格式为:prefix-TIME_IN_MS[.suffix] |
| saveAsObjectFile | 同上,但是将每个batch的数据以序列化对象的方式,保存到SequenceFile中。 |
| saveAsHadoopFile | 同上,将数据保存到Hadoop文件中 |
| foreachRDD | 最常用的output操作,遍历DStream中的每个产生的RDD,进行处理。可以将每个RDD中的数据写入外部存储,比如文件、数据库、缓存等。通常在其中,是针对RDD执行action操作的,比如foreach。 |
DStream中的所有计算,都是由output操作触发的,比如print()。如果没有任何output操作,就不会执行定义的计算逻辑。
此外,即使使用了foreachRDD output操作,也必须在里面对RDD执行action操作,才能触发对每一个batch的计算逻辑。否则,光有foreachRDD output操作,在里面没有对RDD执行action操作,也不会触发任何逻辑。
foreachRDD
需求:在foreachRDD中,创建一个Connection,然后通过Connection将数据写入外部存储。
- 误区一:在RDD的foreach操作外部,创建Connection
这种方式是错误的,因为它会导致Connection对象被序列化后传输到每个Task中。而这种Connection对象,实际上一般是不支持序列化的,也就无法被传输。
dstream.foreachRDD { rdd =>
//connection应该放在foreach代码内部
val connection = createNewConnection()
rdd.foreach { record => connection.send(record)
}
}
- 误区二:在RDD的foreach操作内部,创建Connection
这种方式是可以的,但是效率低下。因为它会导致对于RDD中的每一条数据,都创建一个Connection对象。
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
- 合理方式一:使用RDD的foreachPartition操作,并且在该操作内部,创建Connection对象,这样就相当于是,为RDD的每个partition创建一个Connection对象,节省资源的多了。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
//Partition内存创建
val connection = createNewConnection()
//遍历每个RDD
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
- 合理方式二:手动封装一个静态连接池,使用RDD的foreachPartition操作,并且在该操作内部,从静态连接池中,通过静态方法,获取到一个连接,使用之后再还回去。这样的话,甚至在多个RDD的partition之间,也可以复用连接了。而且可以让连接池采取懒创建的策略,并且空闲一段时间后,将其释放掉。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection)
}
}
缓存与持久化机制
对DStream调用persist()方法,就可以让Spark Streaming自动将该数据流中的所有产生的RDD,都持久化到内存中
对于基于窗口的操作,比如reduceByWindow、reduceByKeyAndWindow,以及基于状态的操作,比如updateStateByKey,默认就隐式开启了持久化机制
对于通过网络接收数据的输入流,比如socket、Kafka、Flume等,默认的持久化级别是将数据复制一份,以便于容错,用的是类似MEMORY_ONLY_SER_2
默认的持久化级别,统一都是要序列化的
Checkpoint机制
Checkpoint类型
Spark Streaming 有两种数据需要被进行checkpoint
-
元数据checkpoint:为了从driver失败中进行恢复
- 配置信息——创建Spark Streaming应用程序的配置信息,比如SparkConf中的信息。
- DStream的操作信息——定义了Spark Stream应用程序的计算逻辑的DStream操作信息。
- 未处理的batch信息——那些job正在排队,还没处理的batch信息。
-
数据checkpoint:对有状态的transformation操作进行快速的失败恢复
将实时计算过程中产生的RDD的数据保存到可靠的存储系统中
使用场景
- 使用了有状态的transformation操作
- 要保证可以从driver失败中进行恢复
除此之外,Spark Streaming中不应该使用Checkpoint机制,降低性能
checkpoint使用方式
将checkpoint间隔设置为窗口操作的滑动间隔的5~10倍
- 数据checkpoint
val ssc = new StreamingContext(spark.sparkContext,Seconds(1))
ssc.checkpoint("hdfs://spark1:9000/checkpoint")
- 从Driver失败中进行恢复
- 更改程序
//当Driver从失败中恢复过来时,需要从checkpoint目录中记录的元数据中,恢复出来一个StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...)
val lines = ssc.socketTextStream(...)
ssc.checkpoint(checkpointDirectory)
ssc
}
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
context.start()
context.awaitTermination()
- 更改spark-submit
--deploy-mode:
默认其值为client,表示在提交应用的机器上启动Driver;要能够自动重启Driver,就必须将其值修改为cluster;--supervise:
对于Spark自身的standalone模式,需要进行一些配置去supervise driver,监控Driver运行的过程,在它失败时将其重启。
部署应用程序
- 一个集群资源管理器,比如standalone模式下的Spark集群,Yarn模式下的Yarn集群等。
- 打jar包
- 为executor配置充足的内存 : Receiver接受到的数据,是要存储在Executor的内存中的。注意如果要执行窗口操作,那么Executor的内存资源就必须足够保存窗口内的数据
- 配置checkpoint,配置一个Hadoop兼容的文件系统(比如HDFS)的目录作为checkpoint目录.[可选]
- 配置driver的自动恢复,要重写driver程序,要在spark-submit中添加参数.[可选]
启用预写日志机制
如果启用该机制,Receiver接收到的所有数据都会被写入配置的checkpoint目录中的预写日志。这种机制可以让driver在恢复的时候,避免数据丢失,并且可以确保整个实时计算过程中,零数据丢失。
-
使用方式
- StreamingContext的
checkpoint()方法设置一个checkpoint目录 spark.streaming.receiver.writeAheadLog.enable=true
- StreamingContext的
-
缺点
会导致Receiver的吞吐量大幅度下降,因为单位时间内,有相当一部分时间需要将数据写入预写日志。 -
优化
- 创建多个输入DStream,启动多个Rceiver
注意cpu core数量
- 禁用复制持久化机制,因为所有数据已经保存在容错的文件系统中了
DStream默认持久化机制为StorageLevel.MEMORY_AND_DISK_SER_2,改为StorageLevel.MEMORY_AND_DISK_SER
设置Receiver接收速度
Receiver可以被设置一个最大接收限速,以每秒接收多少条单位来限速
- 普通Receiver
spark.streaming.receiver.maxRate - Kafka Direct
spark.streaming.kafka.maxRatePerPartition- backpressure机制(推荐)
不需要设置Receiver的限速,Spark可以自动估计Receiver最合理的接收速度,并根据情况动态调整spark.streaming.backpressure.enabled=true
升级应用程序
- 旧程序消费后的数据还可以被新程序消费:
升级后的Spark应用程序直接启动,与旧的Spark应用程序并行执行,再关闭旧程序 - 数据源支持数据缓存,未消费不会丢失
StreamingContext.stop():确保接收到的数据都处理完之后才停止,再部署新程序,新的应用程序会从老的应用程序未消费到的地方继续消费
如Kafka、Flume数据源支持数据缓存 - driver自动恢复机制配置了checkpoint
让新的应用程序针对新的checkpoint目录启动,或者删除之前的checkpoint目录
容错机制
在大多数情况下,Spark Streaming数据都是通过网络接收的(除了使用fileStream数据源)。要让Spark Streaming的RDD,都达到与普通Spark程序RDD相同的容错性,接收到的数据必须被复制到多个Worker节点上的Executor内存中,默认的复制因子是2。
数据恢复
- 对于网络接收数据,在出现失败的事件时,有两种数据需要被恢复
- 数据已接收并复制
一个Worker节点挂掉时,其他Worker节点上,还有副本 - 数据已接收在缓存中等待复制
需要重新从数据源获取一份数据
- 节点失败
- Worker节点的失败
任何一个运行了Executor的Worker节点挂掉,都会导致该节点上所有在内存中的数据都丢失。如果有Receiver运行在该Worker节点上的Executor中,那么缓存的和待复制的数据都会丢失。 - Driver节点的失败
如果运行Spark Streaming应用程序的Driver节点失败了,那么显然SparkContext会丢失,那么该Application的所有Executor的数据都会丢失。可以设置driver自动恢复
流式计算系统的容错语义
- 最多一次:每条记录可能会被处理一次,或者根本就不会被处理。可能有数据丢失。
- 至少一次:每条记录会被处理一次或多次,确保零数据丢失。但是可能会导致记录被重复处理几次。
- 一次且仅一次:每条记录只会被处理一次。这是最强的一种容错语义。
Spark Streaming处理数据
- 接收数据:使用Receiver或其他方式接收数据。
- 计算数据:使用DStream的transformation操作对数据进行计算和处理。
- 推送数据:最后计算出来的数据会被推送到外部系统,比如文件系统、数据库等
对应的语义保障
- 接收数据:不同的数据源提供不同的语义保障
- 计算数据:所有接收到的数据一定只会被计算一次,这是基于RDD的基础语义所保障的。
- 推送数据:output操作默认能确保至少一次的语义,因为它依赖于output操作的类型,以及底层系统的语义支持(比如是否有事务支持等),但是用户可以实现它们自己的事务机制来确保一次且仅一次的语义
接收数据的容错语义
- 基于容错的文件系统的数据源:一次且仅一次
- 基于Receiver的数据源
- 可靠的Receiver
这种Receiver会在接收到了数据,并且将数据复制之后,对数据源执行确认操作,数据源没有收到确认,会在Receiver重启之后重新发送数据 - 不可靠的Receiver
这种Receiver不会发送确认操作,因此当Worker或者Driver节点失败的时候,可能会导致数据丢失。
- 可靠的Receiver
| 部署场景 | Worker失败 | Driver失败 |
|---|---|---|
| 没有开启预写日志机制 | 1. 不可靠Receiver,会导致缓存数据丢失 2.可靠的Receiver,可以保证数据零丢失;3.至少一次的语义 | 1、不可靠Receiver,缓存的数据全部丢失;2.任何Receiver,过去接收的所有数据全部丢失;3.没有容错语义 |
| 开启了预写日志机制 | 1. 可靠Receiver,零数据丢失;2.至少一次的语义 | 1.可靠Receiver和文件,零数据丢失 |
Kafka Direct API,可以保证所有从Kafka接收到的数据,都是一次且仅一次。
基于该语义保障,如果自己再实现一次且仅一次语义的output操作,那么就可以获得整个Spark Streaming应用程序的一次且仅一次的语义
输出数据的容错语义
output操作,可以提供至少一次的语义:当Worker节点失败时,转换后的数据可能会被写入外部系统一次或多次
要真正获得一次且仅一次的语义
- 幂等更新:多次写操作,都是写相同的数据,例如saveAs系列方法,总是写入相同的数据
- 事务更新:所有的操作都应该做成事务的,从而让写入操作执行一次且仅一次。给每个batch的数据都赋予一个唯一的标识,然后更新的时候判定,如果数据库中还没有该唯一标识,那么就更新,如果有唯一标识,那么就不更新。
dstream.foreachRDD { (rdd, time) => rdd.foreachPartition { partitionIterator => val partitionId = TaskContext.get.partitionId() val uniqueId = generateUniqueId(time.milliseconds, partitionId) // partitionId和foreachRDD传入的时间,可以构成一个唯一的标识 } }
steaming 高可用HA
checkpoint
updateStateByKey、window等有状态的操作,自动进行checkpoint,必须设置checkpoint目录
val ssc = new StreamingContext(spark.sparkContext,Seconds(1))
//必须checkpoint
ssc.checkpoint("hdfs://spark1:9000/checkpoint")
Driver高可用性
第一次在创建和启动StreamingContext的时候,将元数据写入容错的文件系统(比如hdfs),driver挂掉后可以从容错文件系统(比如hdfs)中读取之前的元数据信息,包括job的执行进度,继续接着之前的进度
前提条件:cluster模式(driver运行在worker)
JavaStreamingContextFactory contextFactory = new JavaStreamingContextFactory() {
@Override
public JavaStreamingContext create() {
JavaStreamingContext jssc = new JavaStreamingContext(...);
JavaDStream<String> lines = jssc.socketTextStream(...);
jssc.checkpoint(checkpointDirectory);
return jssc;
}
};
//getOrCreate
JavaStreamingContext context = JavaStreamingContext.getOrCreate(checkpointDirectory, contextFactory);
context.start();
context.awaitTermination();
spark-submit
--deploy-mode cluster
--supervise
RDD高可用性:启动WAL预写日志机制
一个batch创建一个rdd,启用预写日志后receiver接收到数据后,就会立即将数据写入一份到容错文件系统(比如hdfs)上的checkpoint目录中去
spark.streaming.receiver.writeAheadLog.enable true
Spark Streaming性能调优
数据接收并行度调优
-
Receiver并行化接收数据
每一个输入DStream都会在某个Worker的Executor上启动一个Receiver,可以创建多个输入DStream,并且配置它们接收数据源不同的分区数据,达到接收多个数据流的效果。
比如,一个接收两个Kafka Topic的输入DStream,可以被拆分为两个输入DStream,每个分别接收一个topic的数据。多个DStream可以使用union算子进行聚合,从而形成一个DStream。后续使用transformation算子操作int numStreams = 5; List<JavaPairDStream<String, String>> kafkaStreams = new ArrayList<JavaPairDStream<String, String>>(numStreams); for (int i = 0; i < numStreams; i++) { kafkaStreams.add(KafkaUtils.createStream(...)); } JavaPairDStream<String, String> unifiedStream = streamingContext.union(kafkaStreams.get(0), kafkaStreams.subList(1, kafkaStreams.size())); unifiedStream.print(); -
调节block interval
spark.streaming.blockInterval:设置block interval,默认是200ms
对于大多数Receiver来说,在将接收到的数据保存到Spark的BlockManager之前,都会将数据切分为一个一个的block。而每个batch中的block数量,则决定了该batch对应的RDD的partition的数量,以及针对该RDD执行transformation操作时,创建的task的数量。每个batch对应的task数量是大约估计的,即task ≈ batch interval / block interval,比如batch interval为2s,block interval为200ms,则创建10个task
调优目的是让batch的task数量大于每台机器的cpu core数量,尽量利用cpu core,推荐task数量是cpu core数量的2~3倍如果集群中有多个spark程序在跑,应该设置成所有应用的task数量总和是cpu core数量的2~3倍
推荐的block interval最小值是50ms,如果低于这个数值,那么大量task的启动时间,可能会变成一个性能开销点。
-
重分区
inputStream.repartition(<number of partitions>):可以将接收到的batch分布到指定数量的机器上再操作。
任务启动调优
发送task去Worker节点上的Executor的有延迟,耗时
- Task序列化:使用Kryo序列化机制来序列化task,可以减小task的大小,从而减少发送这些task到各个Worker节点上的Executor的时间
官网上并未提出这一点
- 执行模式:在Standalone/ coarse-grained Mesos模式下运行Spark,比fine-grained Mesos 模式有更少的task启动时间
These changes may reduce batch processing time by 100s of milliseconds
数据处理并行度调优
让在stage中使用的并行task的数量足够多,充分利用集群资源
如reduce,默认的并行task的数量是由spark.default.parallelism决定,为全局变量;也可以手动指定该操作的并行度
数据序列化调优
两种场景会序列化
- 默认情况下,接收到的输入数据,是存储在Executor的内存中的,使用的持久化级别是
StorageLevel.MEMORY_AND_DISK_SER_2,Receiver反序列化从网络接收到的数据,再使用Spark的序列化格式序列化数据 - 流式计算操作生成的持久化RDD会持久化到内存中,默认持久化级别是
StorageLevel.MEMORY_ONLY_SER
优化
目标:减少用于序列化和反序列化的CPU性能开销和GC开销
- 使用Kryo序列化
- 禁止序列化:数据总量并不是很多,可以将数据以非序列化的方式进行持久化
batch interval调优
batch处理时间(可以通过观察Spark UI上的batch处理时间)必须小于batch interval时间,否则会堆积数据
由于临时性的数据增长导致的暂时的延迟增长是合理的,只要延迟情况可以在短时间内恢复即可
内存调优
增大内存
在窗口时间内通过Receiver接收到的数据,会使用StorageLevel.MEMORY_AND_DISK_SER_2持久化级别来进行存储,因此无法保存在内存中的数据会溢写到磁盘上,会降低应用性能
另外,若窗口操作中要使用大量 keys 的updateStateByKey,同样会消耗大量内存
垃圾回收
- DStream的持久化
输入数据和某些操作生产的中间RDD,默认持久化时都会序列化为字节,可以使用Kryo序列化,也可以设置spark.rdd.compress=true压缩数据,代价是 CPU 时间 - 清理旧数据
默认隔一段时间会清理数据,如按窗口时间长度清理,可以使用streamingContext.remember()延长清理时间,以便给其他操作使用数据 - CMS垃圾回收器
并行的GC会降低吞吐量,但GC低开销,减少batch的处理时间- driver端
spark-submit中使用--driver-java-options:-XX:+UseConcMarkSweepGC - executor端
spark.executor.extraJavaOptions:-XX:+UseConcMarkSweepGC
- driver端
- 其他
使用 OFF_HEAP 存储级别的保持 RDDs
使用更小的 heap sizes 的 executors.这将降低每个 JVM heap 内的 GC 压力
