

本篇为elasticsearch源码分析系列文章的第十一篇,本篇开始进入索引有关操作的讲解。以后的若干篇我们会连续讨论文档的创建,检索,更新,删除,版本控制等一系列内容。
文档
ElasticSearch存储系统中的实体叫做文档,document。如果用关系型数据库来类比的话,一个文档相当于数据库中的一行记录。ElasticSearch中的文档有个特点,相同字段必须是相同的类型,也就是说所有包含title字段的文档,title字段类型都必须一样,要么同为string,要么同为int。
文档由多个字段组成,每个字段的类型可以是,文本,数值,日期,还可以是字符串数组这种复杂的类型。字段类型在ElasticSearch中非常重要,它涉及到各种分析和排序操作如何被执行的信息。Elastic官方推荐我们使用Mapping映射来干预字段的类型。与关系型数据库不同,ElasticSearch不需要有固定的结构,每个文档可以有不同的字段,此外,在程序开发期间,不必确定有哪些字段。
文档的类型
在ElasticSearch中,文档类型可以让程序员轻松的区分单个索引中的不同对象。每个文档可以有不同的结构,但在实际生产环境中我们还是推荐将文档中的类型详细化,这样对以后的开发会有很大的帮助。
文档类型的映射
上面提到的映射,指的是ElasticSearch在映射中存储有关字段的信息,这种类型信息就是映射Mapping。每个文档类型都有自己的映射,即使在初始化时没有提前定义。在涉及到全文搜索和倒排索引的内容中,会有对文档分析的过程,在这个过程中每个字段都必须根据不同类型作相应的分析。举例来说,对数值字段和文本字段的分析肯定是不同的分析过程,数字的分析就不应该是按照字母的排序来分析。
使用ElasticSearch的ResultAPI来新建文档
在ElasticSearch中,所有文档都是数据,所有数据都有定义好的索引和类型。现在我们通过一个比较常见的例子来建立文档:
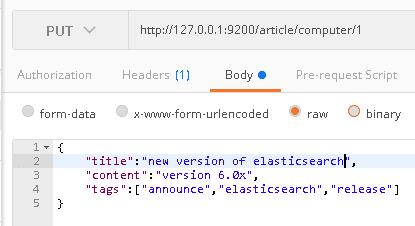
上面操作的意思是,我们建立了一个名为article的索引和名为computer的类型,文档的标示符为1。
如果一切正常,那么这种使用RESTfulAPI的创建方式会返回一个JSON响应,与如下输出类似:
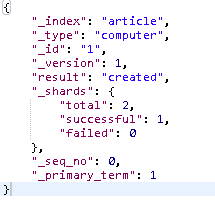
前面的相应包含了操作状态的信息,显示了创建的文档放在什么地方,还包含了文档的唯一标示符**_id和当前版本_version**的信息。每次ElasticSearch的更新版本都会自动递增。
而且ElasticSearch在创建文档时,如果没指定文档标示符,那么这个文档的标示符会被自动创建。
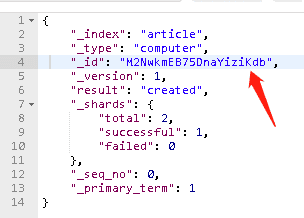
这都是怎么做到的呢?我们会在下一节从源码的角度解释。
ElasticSearch源码如何新建文档
在以前文章中强调的Node实例化的过程中,加载了ActionModule这个模块,这个模块是接收客户端发送的RESTful请求的的模块,ActionModule的加载如下:
ActionModule actionModule = new ActionModule(false, settings, clusterModule.getIndexNameExpressionResolver(), settingsModule.getIndexScopedSettings(), settingsModule.getClusterSettings(), settingsModule.getSettingsFilter(), threadPool, pluginsService.filterPlugins(ActionPlugin.class), client, circuitBreakerService, usageService);
在加载完了ActionModule后,会通过ActionModule的方法**initRestHandlers()**来初始化HTTP处理程序,这个handler就能解析客户端通过http协议发送到ElasticSearch集群中的RESTful请求。
加载RestIndexActionindex处理器,
registerHandler.accept(new RestIndexAction(settings, restController))
如下图所示,注册不同的REST处理程序路径,以用来不同的匹配请求。
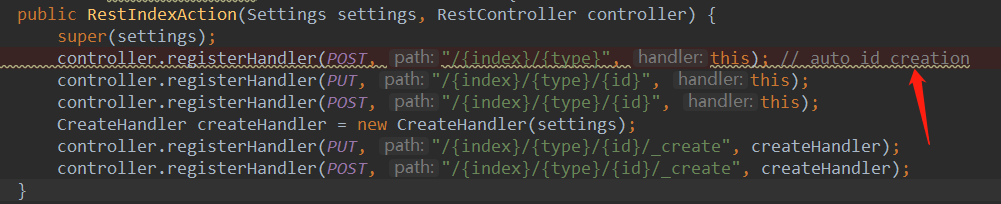
可以看到控制器匹配路径中,有index,type和id,如果不指定id,则id会被自动创建,而且不指定id必须用POST方法来发送请求。
因为ElasticSearch中的Controller底层都是Netty实现的。所以在端口绑定后,Netty4HttpChannel会去监听端口收到的http请求。在ElasticSearch的Controller接收到Netty4HttpChannel转发的请求后,会调用RestIndexAction中的方法prepareRequest()。该方法返回RestChannelConsumer类型的实例,该实例是虚拟类BaseRestHandler中的Functional接口。阅读这个接口的定义的方法,可以知道ElasticSearch中的REST请求是通过准备一个表示通道的请求执行的通道消费者(a channel consumer)来处理的。
接收到请求后开始构建IndexRequest,这个实例作用是将JSON类型的文档转换为一个特定的和可搜索的索引。
IndexRequest回首先取得RestRequest中的三个构造实例必须的参数:
- index:文档的索引
- type:文档的类型
- id:文档指定的标识
然后在依次取得一些附加参数:
- routing:控制分片的路由请求。使用这个值来哈希的分片,而不是id。
- parent:设置document的父id。
- pipeline:在执行索引document前,设置摄取管道(ingest pipeline)
- source:设置document索引的字节形式。
- timeout:超时时间
- refresh:解析刷新策略
- version_type:设置版本类型
- op_type:字符串,用来表示是索引数据还是新建数据
参数详情如下图:
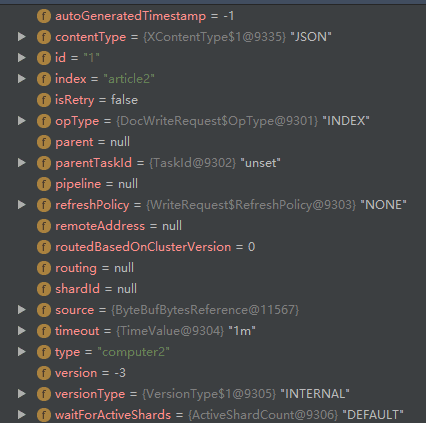
这参数都是NodeClient在索引文档时候需要用到的数据,NodeClient在Node初始化时候就加载完成,他是用来在本地节点上执行操作的模拟客户端。
方法prepareRequest最后返回channel -> client.index(indexRequest, new RestStatusToXContentListener<>(channel, r -> r.getLocation(indexRequest.routing()))),因为该方法需要返回RestChannelConsumer类型的返回值,所以改写成jdk7版本易于理解的代码版本如下图所示:
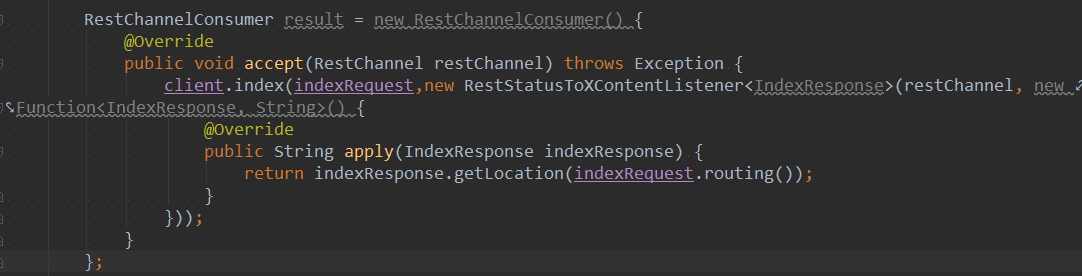
该段代码中最重要的就是NodeClient的index()方法,此方法的关键是新建了一个Task,这个Task包含了id,type,action,description,parentTask,startTime等信息。
该task在老版本会被TransportIndexAction处理,但是6.0版本后TransportBulkAction已经取代了TransportIndexAction。task会被当做参数送入TransportBulkAction的doExecute方法中,另外两个参数是BulkRequest和ActionListener
void doExecute(Task task, BulkRequest bulkRequest, ActionListener<BulkResponse> listener)
BulkRequest中包含了该文档存储的信息,而ActionListener则用来监听action的响应或失败,用以做回调操作。
doExecute方法主要做了以下操作:
- 收集请求中的所有索引
- 过滤掉不存在的索引,同时建立一个我们无法创建的索引图。判断不存在的索引和无法创建的索引主要是看索引是否有别名
- 如果有遗漏的索引,则创建缺少的所有索引。注意在所有的创建完成后开始批量处理数据
然后执行TransportBulkAction类的executeBulk方法,完成数据的落地。
