

在《用Python模拟2018世界杯夺冠之路》一文中,我选择从公开的足球网站用爬虫抓取数据,从而建模并模拟比赛,但是略过了爬虫的实施细节。虽然爬虫并不难做,但希望可以让更多感兴趣的朋友自己动手抓数据下来玩,提供便利,今天就把我抓取球探网的方法和Python源码拿出来分享给大家,不超过100行代码。希望球友们能快速get爬虫的技能。
#-*- coding: utf-8 -*-
from __future__ import print_function, division
from selenium import webdriver
import pandas as pd
class Spider(object):
def __init__(self):
## setup
#self.base_url = base_url
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.verificationErrors = []
self.accept_next_alert = True
def get_all_team_data(self):
# 先通过世界杯主页获取所有32只队的ID(构成球队URL)
self.get_team_ids()
# 循环爬取每一支队的比赛数据
data = []
for i, [team_id, team_name] in enumerate(self.team_list):
#if i == 1:
# break
print(i, team_id, team_name)
df = self.get_team_data(team_id, team_name)
data.append(df)
output = pd.concat(data)
output.reset_index(drop=True, inplace=True)
#print(output)
output.to_csv('data_2018WorldCup.csv', index=False, encoding='utf-8')
self.driver.close()
def get_team_ids(self):
main_url = 'http://zq.win007.com/cn/CupMatch/75.html'
self.driver.get(main_url)
teams = self.driver.find_elements_by_xpath("//td[@style='background-color:#fff;text-align:left;']")
data = []
for team in teams:
team_id = int(team.find_element_by_xpath(".//a").get_attribute('href').split('/')[-1].split('.')[0])
team_name = team.find_element_by_xpath(".//a").text
print(team_id, team_name)
data.append([team_id, team_name])
self.team_list = data
#self.team_list = pd.DataFrame(data, columns=['team_name', 'team_id'])
#self.team_list.to_excel('国家队ID.xlsx', index=False)
def get_team_data(self, team_id, team_name):
"""获取一个国家队的比赛数据。TODO:没有实现翻页"""
url = 'http://zq.win007.com/cn/team/CTeamSche/%d.html'%team_id
self.driver.get(url)
table = self.driver.find_element_by_xpath("//div[@id='Tech_schedule' and @class='data']")
matches = table.find_elements_by_xpath(".//tr")
print(len(matches))
# 抓取比赛数据,并保存成DataFrame
data = []
for i, match in enumerate(matches):
if i == 0:
headers = match.find_elements_by_xpath(".//th")
h1, h2, h3, h4, h5 = headers[0].text, headers[1].text, headers[2].text, headers[3].text, headers[4].text
print(h1, h2, h3, h4, h5)
continue
try:
info = match.find_elements_by_xpath(".//td")
cup = str(info[0].text.encode('utf-8'))
match_time = str(info[1].text.encode('utf-8'))
home_team = str(info[2].text.encode('utf-8'))
fts = info[3].text
#print('-', cup, '-')
fs_A, fs_B = int(fts.split('-')[0]), int(fts.split('-')[1])
away_team = str(info[4].text.encode('utf-8'))
print(cup, match_time, home_team, away_team, fs_A, fs_B)
data.append([cup, match_time, home_team, away_team, fs_A, fs_B, team_name])
except:
break
df = pd.DataFrame(data, columns=['赛事', '时间', '主队', '客队', '主队进球', '客队进球', '国家队名'])
return df
if __name__ == "__main__":
spider = Spider()
# 第一步:抓2018世界杯球队的ID。第二部:循环抓取每一支队的比赛数据。
spider.get_all_team_data()
是的,上面就是全部的代码,不到100行。首先,打开球探网2018世界杯球队页面,32个国家队名都列在这个页面里,每个国家点进去都是一页比赛列表数据,我们要爬取的就是这32个页面。那么我们必须分两部分完成:
第一步,找到32个国家队各自的网页链接;
第二步,分别进入32个链接,爬取各自的比赛记录数据。
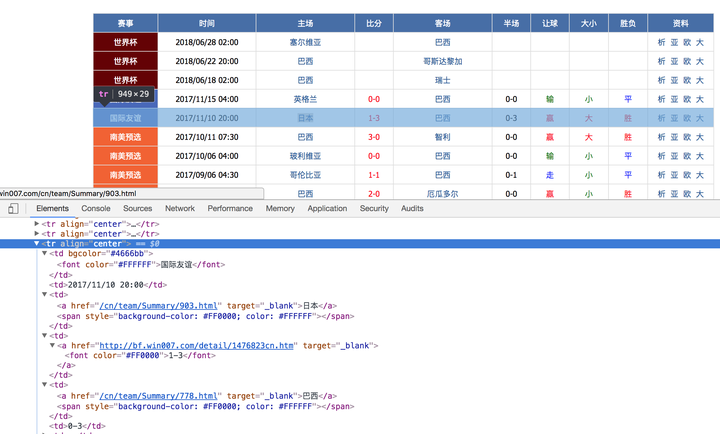
主程序定义了一个Spider类,你可以理解它就是负责完成爬虫这件事的责任人。在它下面定义了一个方法叫get_team_ids,来完成第一步,它读取这个主页面地址main_url = 'zq.win007.com/cn/CupMatch…',通过xpath的方式先找到所有32个国家队名赋给teams变量,再进一步分解出各自的team_id和team_name,注意,球探网每一个球队的url都由一个team_id构造成,换句话说只要知道team_id便可找到确切的球队链接,这也是网站方便管理那么多链接的一个办法。(比如 巴西队的id是778,注意链接zq.win007.com/cn/team/CTe…)
随后,Spider类下还定义了一个get_team_data方法,它需要传入两个参数team_id和team_name,就是球队链接和球队名。由它来负责进入一个给定的国家队页面,抓取这个队所有历史比赛数据。比如巴西队,可以看到比赛数据是一条一条列出来,内容是很整齐的,包括赛事名称、比赛时间、主队、客队、比分、还有一切让球、大小球盘口数据等。就像一个excel表格的网页版,实际上,我们真的可以把每一条数据整整齐齐地爬下来,存进一个excel格式里。而且这种整齐的html表单数据很容易爬取,因为格式是固定的。只要从html源码中找到每一个数字对应的源码就可以通过爬虫语言定位到数据。
最后,为了方便,Spider类下的方法get_all_team_data只是把上面两步整合在一起,完成整个数据抓取过程。在最后调用这个爬虫程序时,先初始化爬虫spider = Spider(),然后调用spider.get_all_team_data()即可开始自动爬取32个国家队的历史比赛数据咯。
由于采用了selenium的webdriver接口,它会让python自动模拟人的行为去打开你的浏览器,所以程序一旦运行你会看到你电脑的浏览器将自动打开、自动地跳转链接,跳转32个国家队的页面。最终,它将爬取下来的比赛数据保存进一张csv存到你电脑本地。
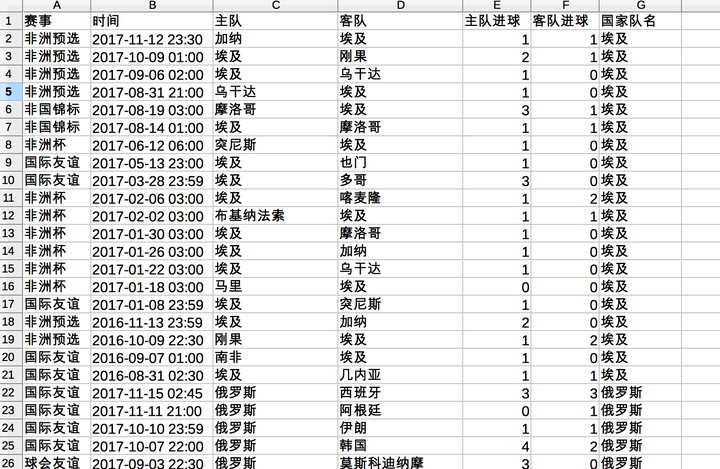
此外,这个爬虫程序稍作修改,可以爬取联赛的数据,比如英超2017-2018赛季,所有的比赛记录同样可以抓下来。更牛逼的地方是我发现它其实有 100多个国家,3-10个级别联赛,近10年的比赛记录,粗略一算也有小10万场比赛。全部抓下来,比分、赛事、让球等等都有,应该还是挺有趣的。
