

go不go哇?吼哇!已经过了两个星期了,陆陆续续看了go中内存模型的代码,发现go代码里面的锁,真是无处不在。所以,本期打算先和大家分享交流一下golang中的锁(同步机制)。
目录
----- 锁是什么?
----- 计算机中的锁
----- golang锁概括
----- runtime / sema (信号量)
----- sync / atomic (原子操作)
----- sync / mutex (互斥锁)
----- sync / rwmutex (读写锁)
----- 后记
00. 锁是什么?
在开始下面的讨论之前,童鞋们不妨先想想,锁是什么?
举个有味道的例子。
问:厕所隔间为什么要有门?
答:厕所坑只有一个啊,不关门难道两个人同时上么 = = !?
问:那没有锁也可以啊,A正在上,B看见了不进去就行了么?
答:那可不一定,万一那B素质比较差,憋得慌,是有可能把正在上洗手间的A拖出来,抢占坑位的!
问:...... ,想想觉得可怕,还是加上锁好了,总不能上到一半被叫出来,等一会再继续啊。
那,那如果A占着茅坑不拉怎么办?外面的人气不是气得团团转?(吐槽:有点像自旋)
答:......,这个话题我们稍后再说,我去买个橘子,你在此处等我。
综上,锁可以保护共享的资源(坑位)只能被一个任务(人)访问,保证各个任务能够正确地访问资源。
wiki百科对lock的解释是:
In computer science, a lock or mutex (from mutual exclusion) is a synchronization mechanism for enforcing limits on access to a resource in an environment where there are many threads of execution. A lock is designed to enforce a mutual exclusionconcurrency control policy.
大意是,锁是一种同步机制,用于在多任务环境中限制资源的访问,以满足互斥需求。
那么,锁的定义很明显了,它是一种机制,目的是做到多任务环境中的对资源访问的同步。
01. 计算机中的锁
上面的概念放到计算机中,任务可以看做线程(thread) or 协程(routine),共享资源可以看做临界资源(critical resource)。代码片段中,访问临界资源的代码片段,叫做临界区(critical section)。
所以为了避免竞争条件,我们只要保证只有一个线程 or 协程在临界区就好了。
先不看系统怎么给我们实现,我们先想想,如果让我们自己来设计锁,怎么做?
.......
比如说在多线程程序中,为了保证共享资源只能被一个线程访问,我们可以在共享内存空间设置一个全局变量flag,当这个flag = 0时,表示资源可以访问,当flag = 1时,资源无法访问,需要占用资源的线程置flag = 0来释放占有权。
想想也没什么不对,但是,童鞋们有没有发现,flag是不是也是一个共享资源啊,大家都可以访问。如果在A正在占用资源,出现了恶意第三者,把flag设置为0,岂不是可以随便访问共享资源了?
这时候,我们需要一种机制,能够保证这个flag不被随意篡改。
这个机制就是,原子操作。顾名思义,原子操作是不能被中断的的一系列操作。我个人以为,原子操作是相对的,比如对于多线程中某个线程来说,对一系列操作加上mutex互斥锁就可以变成原子操作(与其它线程互斥),但是在内核中,它不一定是原子的,甚至一条汇编指令都不一定是原子的,需要通过一些机制才能保证(比如总线锁,后面会说)。
我们平时在编写代码时,接触的原子操作是软件层面的,它是在硬件原子操作的基础上实现的。所以我们先大概了解硬件原子操作~
- 硬件原子操作
硬件的原子操作分单核和多核(SMP)了,因为单核中的一条指令可以看做原子的,但如果涉及内存访问,在多核系统中,就不一定是原子的了(别的核会有线程也去同时访问改内存)。
单核:一条指令就是原子的,中断只会发生在指令之间。比如说有些cpu指令架构提供了test-and-set指令来原子地设属性值,使得临界资源互斥。
多核:多个核心同时运行,某个核心指令在执行单条指令访问内存地时候,也可能会受到其它核心的影响。所以,CPU有一种机制,在指令执行的过程中,对总线加锁,这种加锁是硬件级别的。这里引用一下别人的解释,如下:
CPU芯片上有一条引线#HLOCK pin,如果汇编语言的程序中在一条指令前面加上前缀"LOCK",经过汇编以后的机器代码就使CPU在执行这条指令的时候把#HLOCK pin的电位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的CPU就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中的原子性。
补充:但是,总线锁把CPU和内存之间的通信锁住了,这使得其它CPU不能操作其它内存地址的数据,相当于锁的粒度比较大,导致代价也比较大。所以,有一种方式是通过CPU缓存锁来代替总线锁,来进行优化。
- 软件原子操作
软件原子操作是基于硬件原子操作的。比如linux内核,提供了两种原子操作接口,一种是针对整数的(通常用作计数操作),一种是针对位的。这里我们不细讲。又比如golang中的sync/atomic,针对不同的系统架构,用汇编语言实现了一套原子操作接口。
总结一下,原子操作的意义是啥?
- 原子操作可以实现互斥锁。
- 当我们知道一个操作在它的执行环境原子的,那么多任务处理时,我们可以省去加锁带来的开销。
- 反过来,如果我们实现互斥锁,那么我们可以扩大原子操作的范围。(临界区可以有多个指令执行)
有了上面的基本介绍,我们就进入本次的主题,go中的锁,是如何设计的~
02. golang锁概括
golang的锁在源码的sync包中,该包中包含了各种多任务的同步方式。
从上面的目录结构中,可以看出go中用于同步的方式有很多种,常见的有:
- 原子操作
- 互斥锁
- 读写锁
- waitgroup
这是我们今天主要讲的几种方式,互斥锁,读写锁,waitgroup在golang中的实现都依赖于 原子操作 & 信号量,go中的信号量是在runtime包中实现的,下面我们一个一个来看。
03. runtime / sema (信号量)
runtime中的sema.go实现了sync包以及internal/poll包中的信号量处理。这里主要关注sync包的信号量实现,包括信号量获取&信号量释放。
//go:linkname sync_runtime_Semacquire sync.runtime_Semacquire
func sync_runtime_Semacquire(addr *uint32) {
semacquire1(addr, false, semaBlockProfile)
}
//go:linkname sync_runtime_Semrelease sync.runtime_Semrelease
func sync_runtime_Semrelease(addr *uint32, handoff bool) {
semrelease1(addr, handoff)
}
Golang中的信号量,提供了goroutine的阻塞和唤醒机制,因为go中的任务就是goroutine,信号量的同步功能是作用于goroutine的。再看看sema.go中的一段注释:
// That is, don't think of these as semaphores.
// Think of them as a way to implement sleep and wakeup
它的主要数据结构如下:
type semaRoot struct {
lock mutex
head *sudog
tail *sudog
nwait uint32 // Number of waiters. Read w/o the lock.
}
// 主要结构就是一个sudog的链表和一个nwait。
// 链表用于存储等待的goroutine,nwait表示在该信号量上等待的goroutine数目。
// lock一个互斥量,是在多线程环境中保护链表的。(但是这个mutex不是sync中的mutex,是sema.go
// 内部使用的一个私有版本)
另外,golang设置了可操作信号量个数的最大值为251,这些信号量的对应semaRoot结构被保存在semtable这个大小为251的数组里,数组下标是根据传入addr地址经过运算取模得到的。
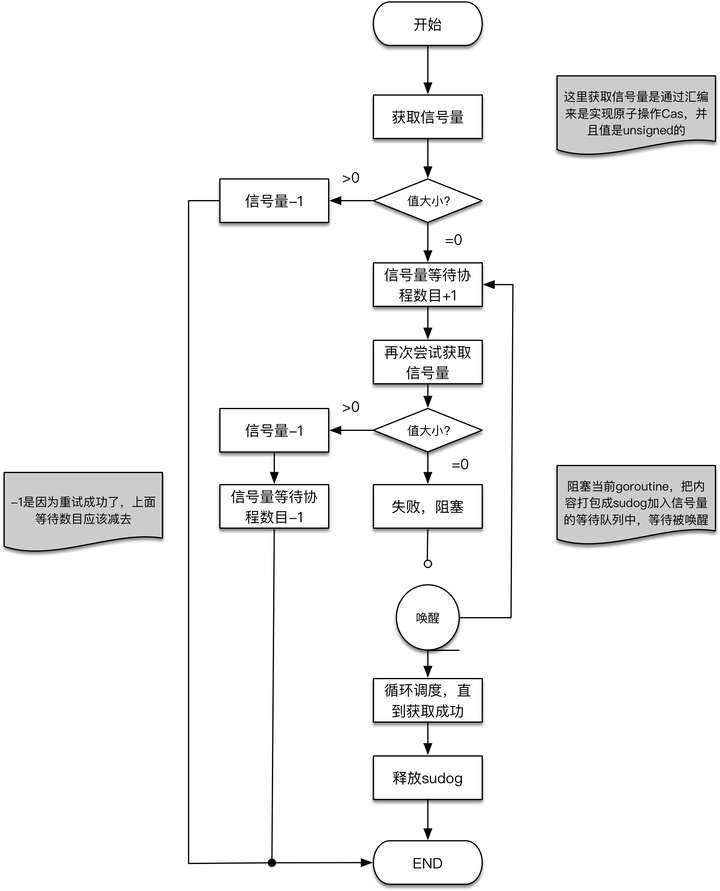
- 信号量获取
semacquire1(addr *uint32, lifo bool, profile semaProfileFlags)
简单来说:semacquire1会先检查信号量addr对应地址的值(unsigned),若 > 0,让信号量-1,结束;若 = 0,就把当前goroutine加入此信号量对应的goroutine waitinglist,并调用gopark阻塞当期goroutine。
执行流程图:
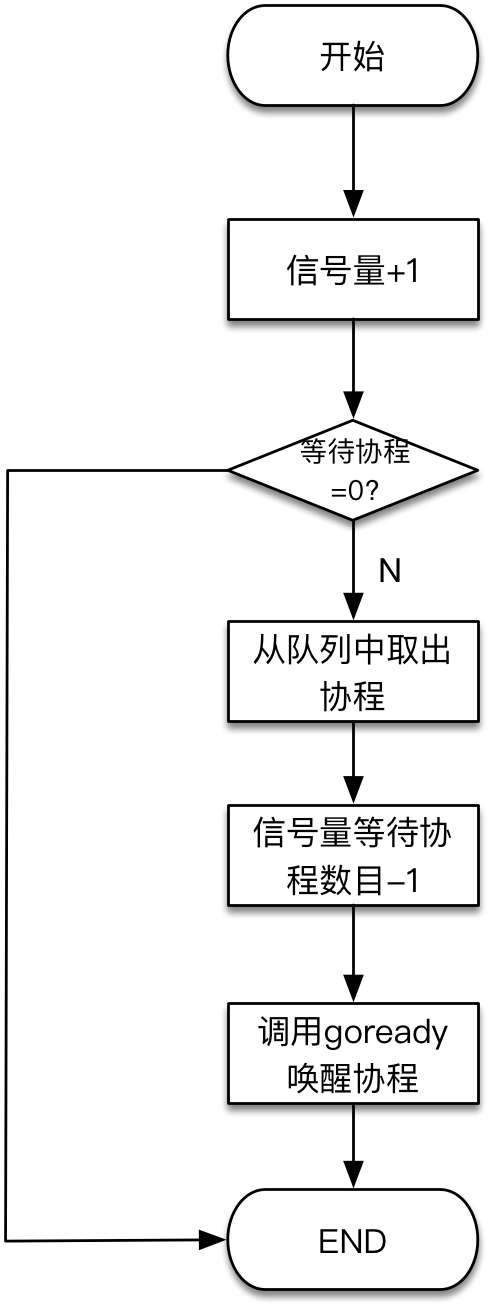
- 信号量释放
semrelease1(addr *uint32, handoff bool)
简单来说:semrelease1会先让信号量+1,然后看信号量关联的goroutine waitinglist是否有goroutine,如果没有,结束;如果有,调用goready唤醒其中一个goroutine。
执行流程图:
至于这里的信号量具体怎么使用,后续的sync/mutex和sync/rwmutex中会涉及~(本质上还是用于goroutine之间的同步嘛)
04. sync / atomic (原子操作)
这里原子操作,是保证多个cpu(协程)对同一块内存区域的操作是原子的。
具体实现为在各个CPU架构上实现的汇编程序,大概如下:
我们挑x86的64位架构的asm_amd64.s来看吧,由于代码比较多,我们举例来看。
在sync/mutex.go中,我们使用原子操作代码片段如下:
// 互斥量加锁操作
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
......
这里调用了 atomic.CompareAndSwapInt32(addr *int32, old, new int32),这是一个CAS操作,为了保证原子性,golang是通过汇编指令来实现的。对应的汇编代码如下:
// Golang的汇编是基于Plan9汇编器,看着有点操蛋(非AT&T or Intel汇编)
// 基本介绍:
// TEXT: 定义函数的
// SB: SB伪寄存器可以想象成内存的地址,所以符号foo(SB)是一个由foo这个名字代表的内存地址。这种形式一般用来命名全局函数和数据。
// FP:Frame Pointer,帧指针。64位机器下,0(FP) 表示函数的第一个参数;8(FP)表示第二个参数等;
// AX:一般的,函数返回值保存在 EAX 寄存器中(Plan9 中叫 AX)
// NOSPLIT: 有NOSPLIT,不必提供参数大小
// 跳转到·CompareAndSwapUint32中执行
TEXT ·CompareAndSwapInt32(SB),NOSPLIT,$0-17
JMP ·CompareAndSwapUint32(SB)
TEXT ·CompareAndSwapUint32(SB),NOSPLIT,$0-17
MOVQ addr+0(FP), BP // 第一个参数命名为addr,放入BP(MOVQ,完成8个字节的复制)
MOVL old+8(FP), AX // 第二个参数命名为old,放入AX
MOVL new+12(FP), CX // 第三个参数命名为new,放入CX
LOCK // 锁内存总线操作,防止其它CPU干扰(这里没有UNLOCK,我想是CPU执行完操作会自动UNLOCK吧,上面的硬件层面原子操作有提及)
CMPXCHGL CX, 0(BP) // CMPXCHGL,该指令会把AX中的内容和第二个操作数中的内容比较,如果相等,那么把第一个操作数内容赋值给第二个操作数
// 即:if(*addr == old); then *addr = new
SETEQ swapped+16(FP)
RET
这是golang中原子操作汇编实现的基本套路,其他指令就不重复了,可以分为以下几类操作:
- CAS操作。比互斥锁乐观,Compare-And-Swap,可能有不成功的时候。
- Swap操作。和上面不同,直接交换。
- 增减操作。原子地对一个数值进行加减
- 读写操作。防止读取一个正在写入的变量,我们的读写操作也需要做到原子。
05. sync / mutex (互斥锁)
互斥锁的作用就不介绍了。golang互斥锁的代码在 sync/mutex.go中。
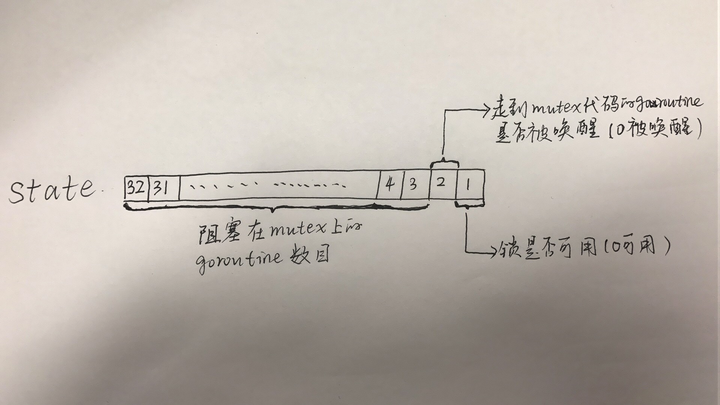
Mutex的相关数据结构:
// A Mutex must not be copied after first use.
type Mutex struct {
state int32 // 一个int32整数,用其中的位来表示
sema uint32
}
//iota,特殊常量,可以认为是一个可以被编译器修改的常量。
//在每一个const关键字出现时,被重置为0,然后再下一个const出现之前,每出现一次iota,其所代表的数字会自动增加1。
const (
mutexLocked = 1 << iota //值为1,表示在state中由低向高第1位,意义:锁是否可用,0可用,1不可用
mutexWoken // 值为2,表示在state中由低向高第2位,意义:mutex是否被唤醒
mutexWaiterShift = iota //值为2,表示state中统计阻塞在此mutex上goroutine的数目需要位移的偏移量
)
看了state是不是表示有点疑惑,上图:
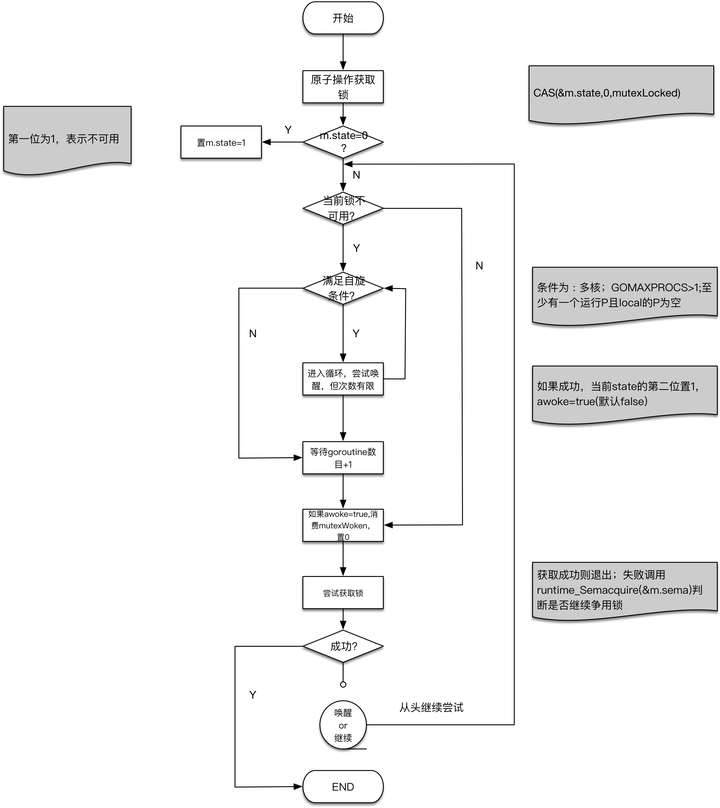
接下来是代码流程:
- func (m *Mutex) Lock() --加锁
简单来说,如果当前goroutine可以加锁,那么调用原子操作使得mutex中的flag设置成已占用达到互斥;如果当前goroutine发现锁已被占用,那么会有条件的循环尝试获取锁,这里是不用信号量去对goroutine进行sleep和wake操作的(尽可能避免开销),如果循环尝试失败,则最后调用原子操作争抢一次,获取不到则还是得调用runtime_Semacquire去判断阻塞goroutine还是继续争用锁。
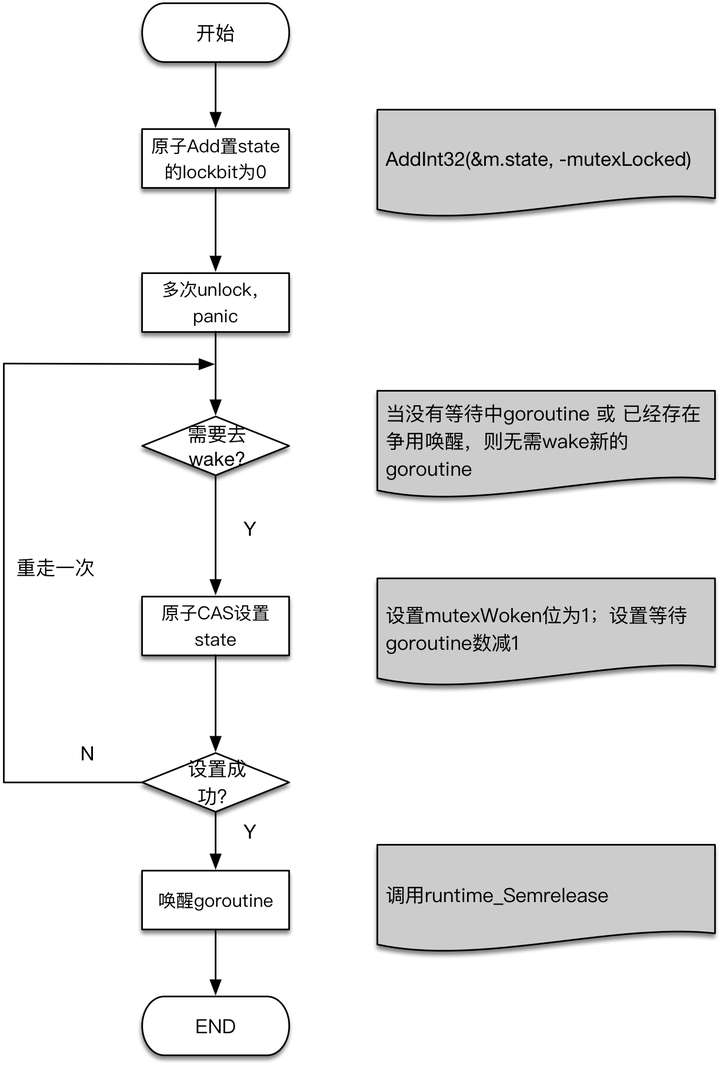
- func (m *Mutex) Unlock() --释放锁
简单来说,就是设置state中的锁标志为0,放开锁,然后根据情况释放阻塞住的goroutine去争抢锁。
06. sync / RWMutex (读写锁)
RWMutex是一个读写锁,该锁可以加多个读锁或者一个写锁,其经常用于读次数远远多于写次数的场景(如果读写相当,用Mutex没啥区别)。但加读锁时,只能继续加读锁;当有写锁时,无法加载其他任何锁。也就是说,只有读-读之间是共享的,其它为互斥的。
RWMutex对应的数据结构如下:
type RWMutex struct {
w Mutex // held if there are pending writers
writerSem uint32 // semaphore for writers to wait for completing readers
readerSem uint32 // semaphore for readers to wait for completing writers
readerCount int32 // number of pending readers
readerWait int32 // number of departing readers
}
看起来读写锁,是基于互斥量和信号量来实现的。
读写锁的代码,除去race检测代码之后,比较简单,直接上(暂时先不加注释,考考童鞋们)
- Rlock --读锁定
func (rw *RWMutex) RLock() {
// 为什么readerCount会小于0呢?往下看发现writer的Lock()会对readerCount做减法操作(原子操作),用来表示现在有writer。
// 所以这里调用信号量,对readerSem判断,如果 > 0, -1,无操作;= 0,阻塞当前加读锁的goroutine
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_Semacquire(&rw.readerSem)
}
}
- RUnlock --读释放
func (rw *RWMutex) RUnlock() {
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// A writer is pending.
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
runtime_Semrelease(&rw.writerSem, false)
}
}
}
- Lock --写锁定
func (rw *RWMutex) Lock() {
// First, resolve competition with other writers.
rw.w.Lock()
// Announce to readers there is a pending writer.
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_Semacquire(&rw.writerSem)
}
}
- Unlock --写释放
func (rw *RWMutex) Unlock() {
// Announce to readers there is no active writer.
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false)
}
// Allow other writers to proceed.
rw.w.Unlock()
}
07. 后记
通过自下而上学习了Golang中锁的实现,能够对锁和多任务同步的理解更加深刻。如果有什么不足的地方,望大家斧正,后续我也会在本文加上新的理解~
题外话,上一张图,这就是我艰苦的学习环境。。。

