

1.安装jdk1.8
ftp上传至/opt 目录下
tar -zxvf /opt/jdk-8u121-linux-x64.tar.gz -C /usr/local/
解压至user/local
配置环境
修改profile
chmod +x /etc/profile #增加执行权限
source /etc/profile #使其生效
2安装hadoop
ftp上传
解压至、usr/local
mv hadoop-2.7.3 hadoop 修改文件夹名称
配置Hadoop环境变量
最终配置文件
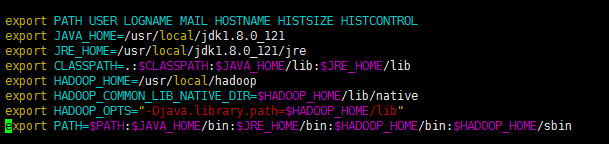
出现如下图即为配置成功

# vim /etc/hostname
192.168.0.101
改为
${yourname}
编辑/etc/hosts文件,设置主机名称与IP映射关系
# vi /etc/hosts
192.168.0.101 ${yourname}配置本机免密码登录
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
这个命令会产生一个公钥(~/.ssh/id_rsa.pub)和密钥(~/.ssh/id_rsa),
-t dsa:表示使用密钥的加密类型,可以为'rsa'和'dsa'
-P '':表示不需要密码登录
-f ~/.ssh/id_dsa:表示密钥存放的路径为${USER}/.ssh/id_dsa
命令2:$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
将本机的公钥添加进authorized_keys中,这样允许本机通过ssh的形式免密码登录
注意使用>>,而不是>,因为如果其它主机(如A)也采用免登陆的形式登录,也可以把主机A的公钥添加到authorized_keys文件中。这样主机A就可以免登陆ssh到本机了。
1.修改hadoop-env.sh
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
这个文件主要是修改java_home的位置,修改JAVA_HOME的路径为以下路径
exportJAVA_HOME=/usr/local/jdk1.8.0_1212.修改core-site.xml
加入
<property>
<!-- 指定namenode的地址 -->
<name>fs.defaultFS</name>
<value>hdfs://jinkai:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mysoft/hadoop/tmp</value>
</property>
3.修改hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>4.修改mapred-site.xml
指定mr运行在yarn上
需要注意的是,并没有mapred-site.xml文件的,但是有mapred-site.xml.template
所以我们只需要将这个mapred-site.xml.template更名为mapred-site.xml即可
mv mapred-site.xml.template mapred-site.xml
5.修改yarn-site.xml
指定yarn(ResourceManager)运行的地址,以及reducer获取数据的方式
<property>
<name>yarn.resourcemanager.hostname</name>
<value>jinkai</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>6.关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
7.reboot 重启服务器
格式化 hdfs
hdfs namenode -format

出现如图即为成功
8.启动我们的dfs和yarn
运行命令:start-dfs.sh

如图即为启动成功
输入命令 jps可以查看我们运行了那些程序

接下来可以测试一下
上传一份txt文件 内容 data mining on data warehouse 至 /opt
在hdfs创建一个目录
hadoop dfs -mkdir /input

glibc库的版本,而hadoop期望是的版本不一致,所以打印警告信息 可以不管
blog.csdn.net/l1028386804… 参考这篇博客可以解决
将文本文件上传至刚创建的hdfs目录

查看文件系统中文件目录

进入jar文件目录,执行下面的指令。
hadoop jar hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce- examples-2.7.3.jar wordcount /input /output

查看结果:hadoop fs -cat /output/part-r-00000
hadoop fs -rmr /output 删除存在在文件夹
