

背景
用 Python 做过爬虫的小伙伴可能接触过 Scrapy,GitHub:github.com/scrapy/scra…。Scrapy 的确是一个非常强大的爬虫框架,爬取效率高,扩展性好,基本上是使用 Python 开发爬虫的必备利器。如果使用 Scrapy 做爬虫,那么在爬取时,我们当然完全可以使用自己的主机来完成爬取,但当爬取量非常大的时候,我们肯定不能在自己的机器上来运行爬虫了,一个好的方法就是将 Scrapy 部署到远程服务器上来执行。
所以,这时候就出现了另一个库 Scrapyd,GitHub:github.com/scrapy/scra…,有了它我们只需要在远程服务器上安装一个 Scrapyd,启动这个服务,就可以将我们写的 Scrapy 项目部署到远程主机上了,Scrapyd 还提供了各种操作 API,可以自由地控制 Scrapy 项目的运行,API 文档:scrapyd.readthedocs.io/en/stable/a…,例如我们将 Scrapyd 安装在 IP 为 88.88.88.88 的服务器上,然后将 Scrapy 项目部署上去,这时候我们通过请求 API 就可以来控制 Scrapy 项目的运行了,命令如下:
curl http://88.88.88.88:6800/schedule.json -d project=myproject -d spider=somespider
这样就相当于启动了 myproject 项目的 somespider 爬虫,而不用我们再用命令行方式去启动爬虫,同时 Scrapyd 还提供了查看爬虫状态、取消爬虫任务、添加爬虫版本、删除爬虫版本等等的一系列 API,所以说,有了 Scrapyd,我们可以通过 API 来控制爬虫的运行,摆脱了命令行的依赖。
另外爬虫部署还是个麻烦事,因为我们需要将爬虫代码上传到远程服务器上,这个过程涉及到打包和上传两个过程,在 Scrapyd 中其实提供了这个部署的 API,叫做 addversion,但是它接受的内容是 egg 包文件,所以说要用这个接口,我们必须要把我们的 Scrapy 项目打包成 egg 文件,然后再利用文件上传的方式请求这个 addversion 接口才可以完成上传,这个过程又比较繁琐了,所以又出现了一个工具叫做 Scrapyd-Client,GitHub: github.com/scrapy/scra…,利用它的 scrapyd-deploy 命令我们便可以完成打包和上传的两个功能,可谓是又方便了一步。
这样我们就已经解决了部署的问题,回过头来,如果我们要想实时查看服务器上 Scrapy 的运行状态,那该怎么办呢?像刚才说的,当然是请求 Scrapyd 的 API 了,如果我们想用 Python 程序来控制一下呢?我们还要用 requests 库一次次地请求这些 API ?这就太麻烦了吧,所以为了解决这个需求,Scrapyd-API 又出现了,GitHub:github.com/djm/python-…,有了它我们可以只用简单的 Python 代码就可以实现 Scrapy 项目的监控和运行:
from scrapyd_api import ScrapydAPI
scrapyd = ScrapydAPI('http://88.888.88.88:6800')
scrapyd.list_jobs('project_name')
这样它的返回结果就是各个 Scrapy 项目的运行情况。
例如:
{
'pending': [
],
'running': [
{
'id': u'14a65...b27ce',
'spider': u'spider_name',
'start_time': u'2018-01-17 22:45:31.975358'
},
],
'finished': [
{
'id': '34c23...b21ba',
'spider': 'spider_name',
'start_time': '2018-01-11 22:45:31.975358',
'end_time': '2018-01-17 14:01:18.209680'
}
]
}
这样我们就可以看到 Scrapy 爬虫的运行状态了。
所以,有了它们,我们可以完成的是:
- 通过 Scrapyd 完成 Scrapy 项目的部署
- 通过 Scrapyd 提供的 API 来控制 Scrapy 项目的启动及状态监控
- 通过 Scrapyd-Client 来简化 Scrapy 项目的部署
- 通过 Scrapyd-API 来通过 Python 控制 Scrapy 项目
是不是方便多了?
可是?真的达到最方便了吗?肯定没有!如果这一切的一切,从 Scrapy 的部署、启动到监控、日志查看,我们只需要鼠标键盘点几下就可以完成,那岂不是美滋滋?更或者说,连 Scrapy 代码都可以帮你自动生成,那岂不是爽爆了?
有需求就有动力,没错,Gerapy 就是为此而生的,GitHub:github.com/Gerapy/Gera…。
本节我们就来简单了解一下 Gerapy 分布式爬虫管理框架的使用方法。
安装
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
- 更方便地控制爬虫运行
- 更直观地查看爬虫状态
- 更实时地查看爬取结果
- 更简单地实现项目部署
- 更统一地实现主机管理
- 更轻松地编写爬虫代码
安装非常简单,只需要运行 pip3 命令即可:
$ pip3 install gerapy
安装完成之后我们就可以使用 gerapy 命令了,输入 gerapy 便可以获取它的基本使用方法:
$ gerapy
Usage:
gerapy init [--folder=<folder>]
gerapy migrate
gerapy createsuperuser
gerapy runserver [<host:port>]
gerapy makemigrations
如果出现上述结果,就证明 Gerapy 安装成功了。
初始化
接下来我们来开始使用 Gerapy,首先利用如下命令进行一下初始化,在任意路径下均可执行如下命令:
$ gerapy init
执行完毕之后,本地便会生成一个名字为 gerapy 的文件夹,接着进入该文件夹,可以看到有一个 projects 文件夹,我们后面会用到。
紧接着执行数据库初始化命令:
cd gerapy
gerapy migrate
这样它就会在 gerapy 目录下生成一个 SQLite 数据库,同时建立数据库表。
接着我们只需要再运行命令启动服务就好了:
gerapy runserver
这样我们就可以看到 Gerapy 已经在 8000 端口上运行了。
全部的操作流程截图如下:
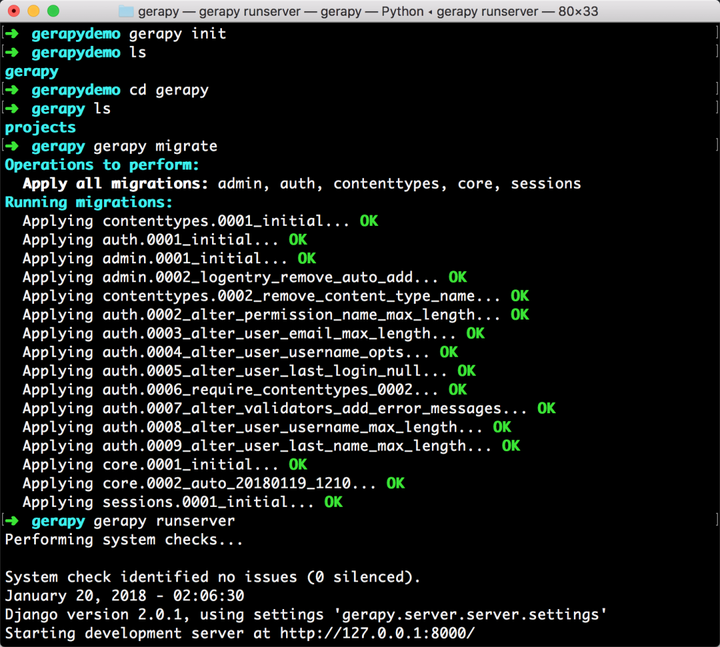
接下来我们在浏览器中打开 http://localhost:8000/,就可以看到 Gerapy 的主界面了:
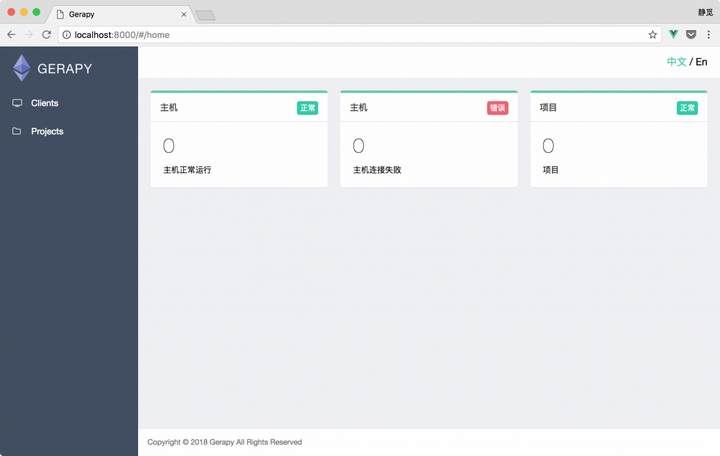
这里显示了主机、项目的状态,当然由于我们没有添加主机,所以所有的数目都是 0。
如果我们可以正常访问这个页面,那就证明 Gerapy 初始化都成功了。
主机管理
接下来我们可以点击左侧 Clients 选项卡,即主机管理页面,添加我们的 Scrapyd 远程服务,点击右上角的创建按钮即可添加我们需要管理的 Scrapyd 服务:
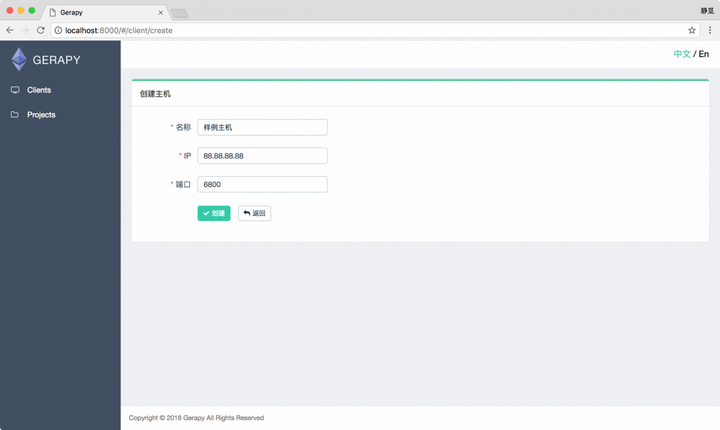
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表,样例如下所示:
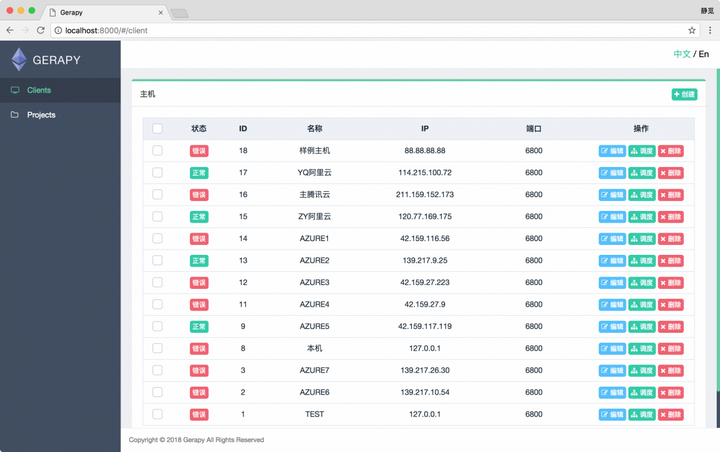
这样我们可以在状态一栏看到各个 Scrapyd 服务是否可用,同时可以一目了然当前所有 Scrapyd 服务列表,另外我们还可以自由地进行编辑和删除。
项目管理
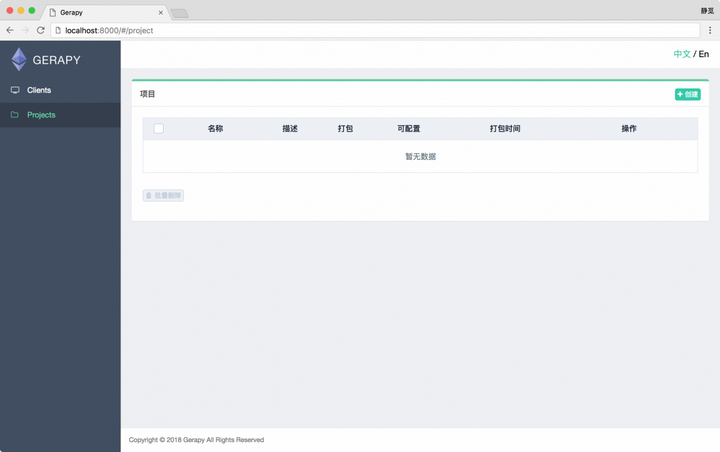
Gerapy 的核心功能当然是项目管理,在这里我们可以自由地配置、编辑、部署我们的 Scrapy 项目,点击左侧的 Projects ,即项目管理选项,我们可以看到如下空白的页面:
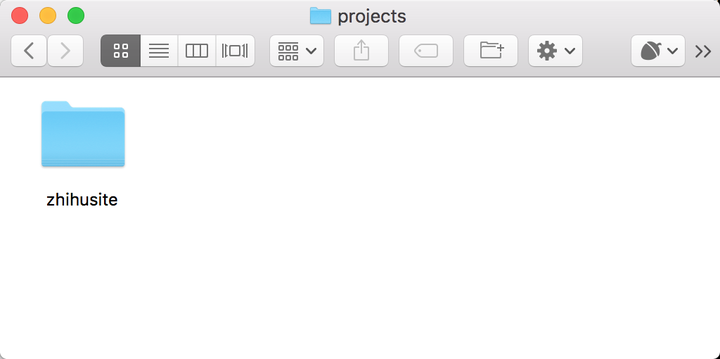
假设现在我们有一个 Scrapy 项目,如果我们想要进行管理和部署,还记得初始化过程中提到的 projects 文件夹吗?这时我们只需要将项目拖动到刚才 gerapy 运行目录的 projects 文件夹下,例如我这里写好了一个 Scrapy 项目,名字叫做 zhihusite,这时把它拖动到 projects 文件夹下:
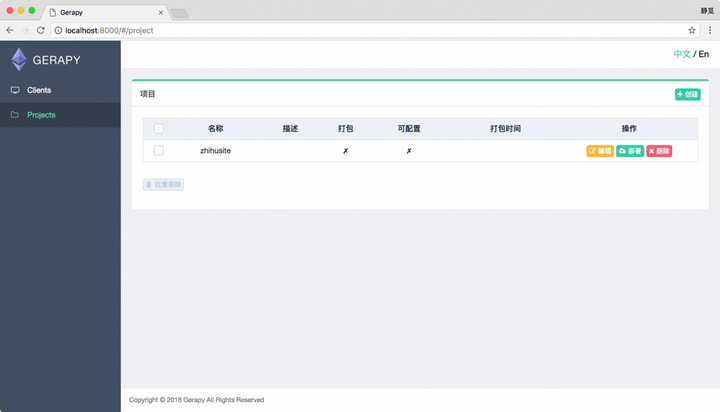
这时刷新页面,我们便可以看到 Gerapy 检测到了这个项目,同时它是不可配置、没有打包的:
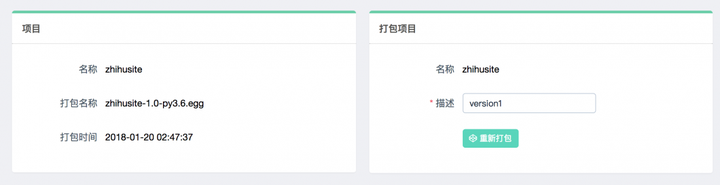
这时我们可以点击部署按钮进行打包和部署,在右下角我们可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称:
打包成功之后,我们便可以进行部署了,我们可以选择需要部署的主机,点击后方的部署按钮进行部署,同时也可以批量选择主机进行部署,示例如下:
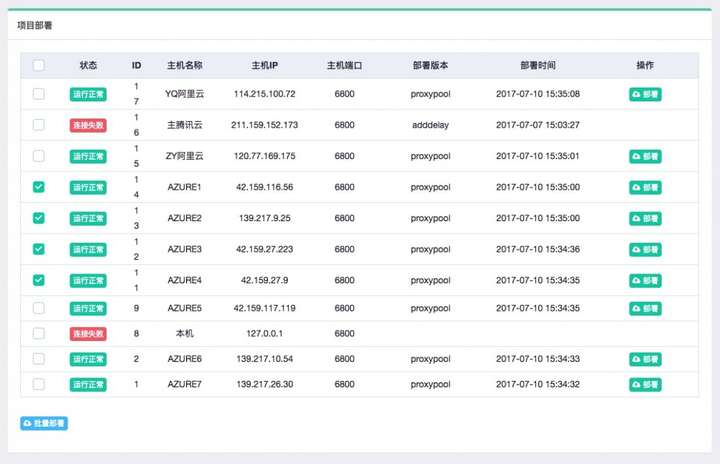
可以发现此方法相比 Scrapyd-Client 的命令行式部署,简直不能方便更多。
监控任务
部署完毕之后就可以回到主机管理页面进行任务调度了,任选一台主机,点击调度按钮即可进入任务管理页面,此页面可以查看当前 Scrapyd 服务的所有项目、所有爬虫及运行状态:
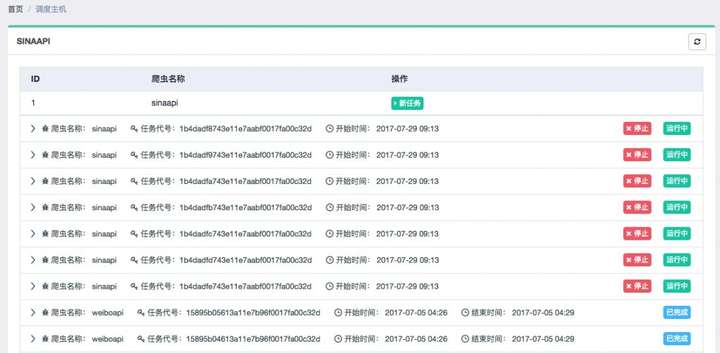
我们可以通过点击新任务、停止等按钮来实现任务的启动和停止等操作,同时也可以通过展开任务条目查看日志详情:
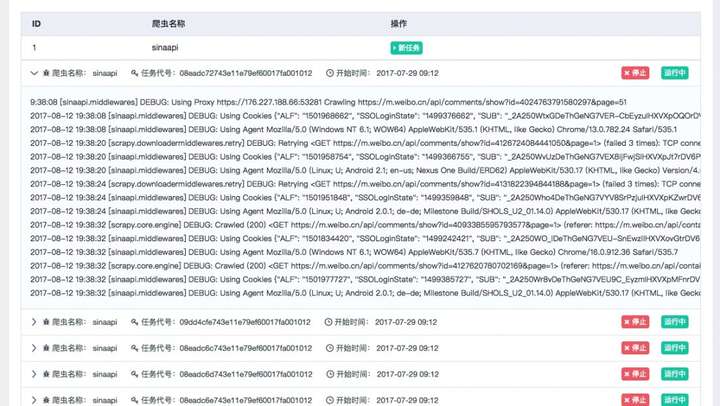
另外我们还可以随时点击停止按钮来取消 Scrapy 任务的运行。
这样我们就可以在此页面方便地管理每个 Scrapyd 服务上的 每个 Scrapy 项目的运行了。
项目编辑
同时 Gerapy 还支持项目编辑功能,有了它我们不再需要 IDE 即可完成项目的编写,我们点击项目的编辑按钮即可进入到编辑页面,如图所示:
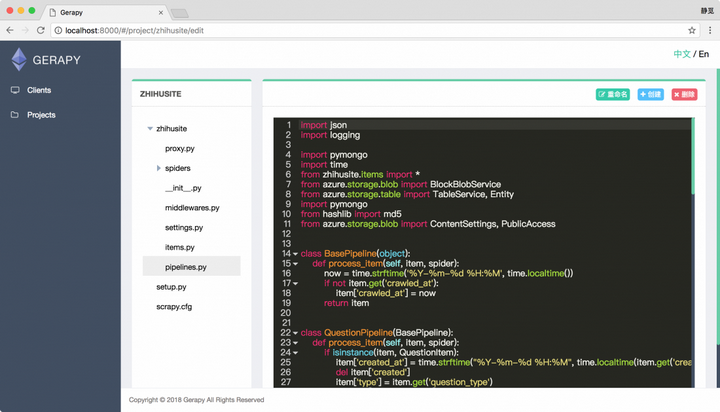
这样即使 Gerapy 部署在远程的服务器上,我们不方便用 IDE 打开,也不喜欢用 Vim 等编辑软件,我们可以借助于本功能方便地完成代码的编写。
代码生成
上述的项目主要针对的是我们已经写好的 Scrapy 项目,我们可以借助于 Gerapy 方便地完成编辑、部署、控制、监测等功能,而且这些项目的一些逻辑、配置都是已经写死在代码里面的,如果要修改的话,需要直接修改代码,即这些项目都是不可配置的。
在 Scrapy 中,其实提供了一个可配置化的爬虫 CrawlSpider,它可以利用一些规则来完成爬取规则和解析规则的配置,这样可配置化程度就非常高,这样我们只需要维护爬取规则、提取逻辑就可以了。如果要新增一个爬虫,我们只需要写好对应的规则即可,这类爬虫就叫做可配置化爬虫。
Gerapy 可以做到:我们写好爬虫规则,它帮我们自动生成 Scrapy 项目代码。
我们可以点击项目页面的右上角的创建按钮,增加一个可配置化爬虫,接着我们便可以在此处添加提取实体、爬取规则、抽取规则了,例如这里的解析器,我们可以配置解析成为哪个实体,每个字段使用怎样的解析方式,如 XPath 或 CSS 解析器、直接获取属性、直接添加值等多重方式,另外还可以指定处理器进行数据清洗,或直接指定正则表达式进行解析等等,通过这些流程我们可以做到任何字段的解析。
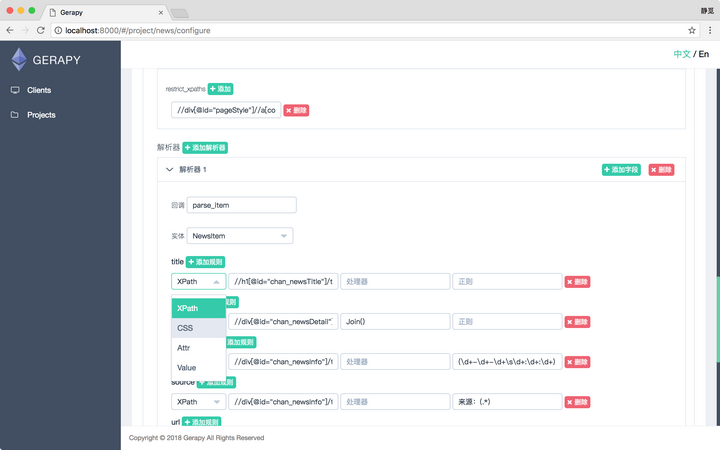
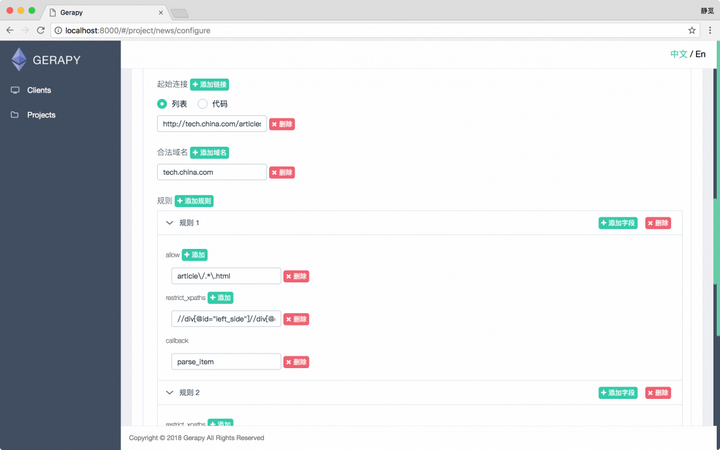
再比如爬取规则,我们可以指定从哪个链接开始爬取,允许爬取的域名是什么,该链接提取哪些跟进的链接,用什么解析方法来处理等等配置。通过这些配置,我们可以完成爬取规则的设置。
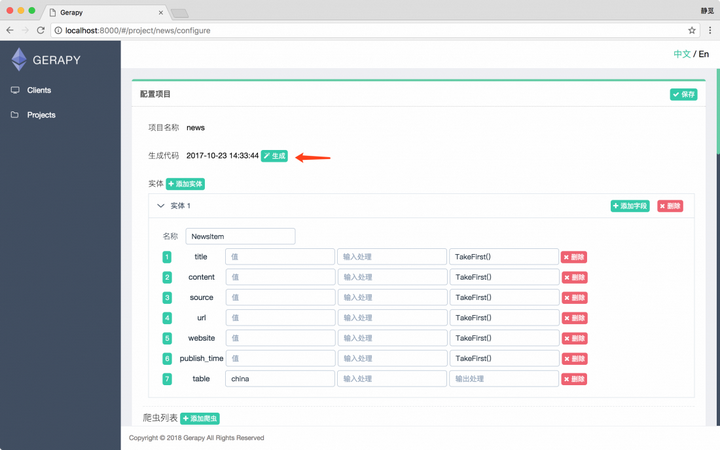
最后点击生成按钮即可完成代码的生成。
生成的代码示例结果如图所示,可见其结构和 Scrapy 代码是完全一致的。
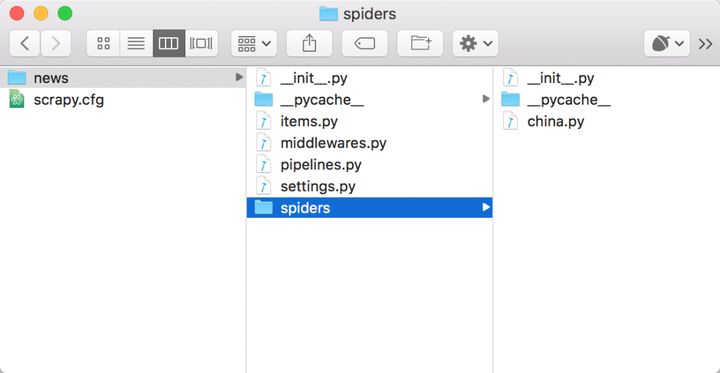
生成代码之后,我们只需要像上述流程一样,把项目进行部署、启动就好了,不需要我们写任何一行代码,即可完成爬虫的编写、部署、控制、监测。
结语
以上便是 Gerapy 分布式爬虫管理框架的基本用法,如需了解更多,可以访问其 GitHub:github.com/Gerapy/Gera…。
如果觉得此框架有不足的地方,欢迎提 Issue,也欢迎发 Pull Request 来贡献代码,如果觉得 Gerapy 有所帮助,还望赐予一个 Star!非常感谢!
如想了解更多爬虫相关技术,可以访问我的博客:静觅丨崔庆才的个人博客
