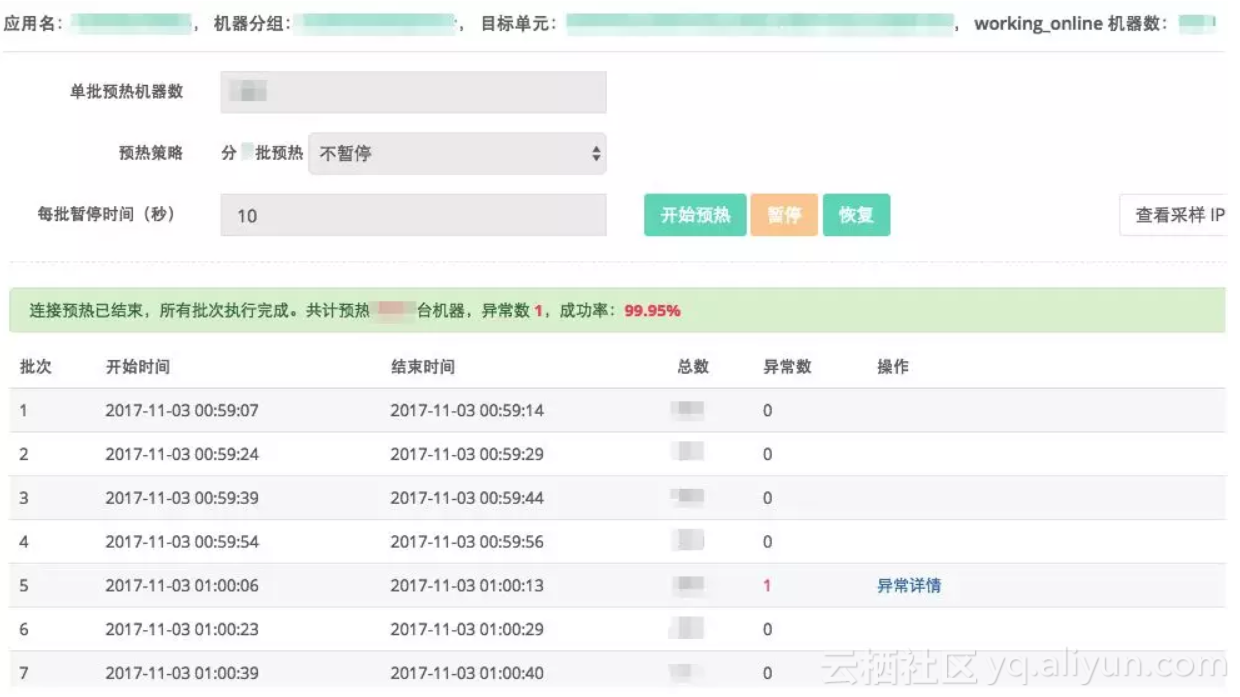
阿里妹导读:2017年的双十一圆满结束了,1682亿的成交额再一次刷新了记录,而HSF(High Speed Framework,分布式服务框架)当天调用量也突破了3.5万亿次,调用量是2016年双十一的三倍多。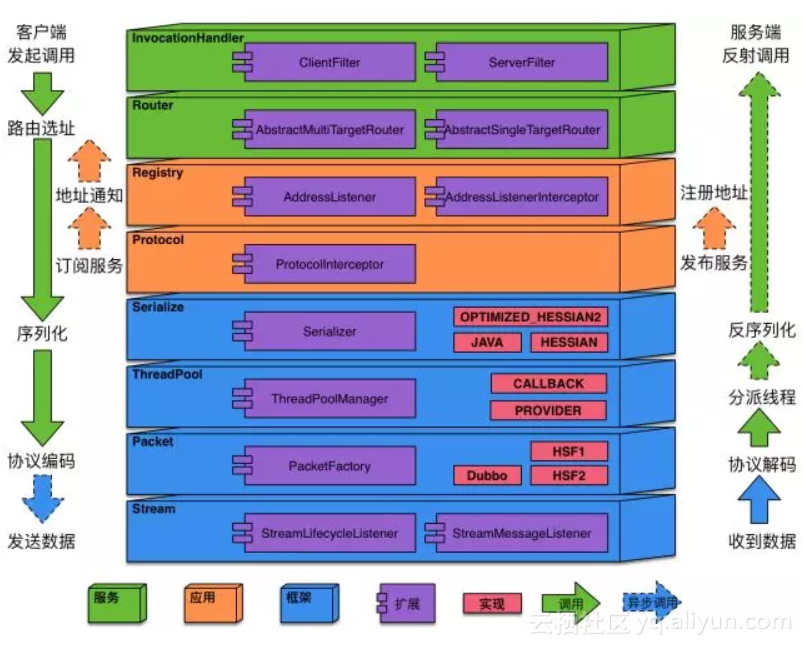
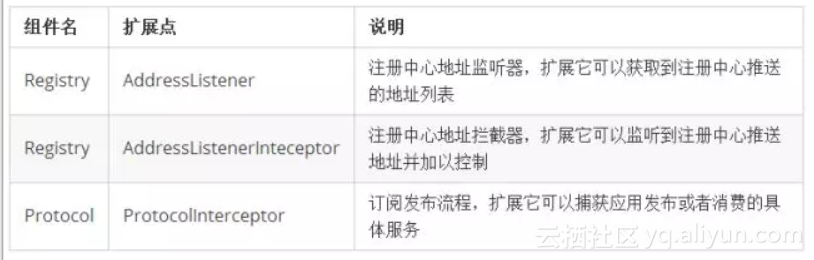
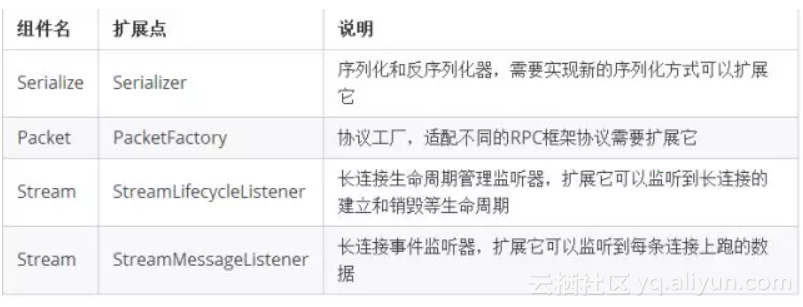

- 序列化过程中类型对应的Class结构不能改变
- 元数据引用只能在“同一个序列化上下文”,这里的“上下文”就是指同一个HessianOutput和HessianInput。因为元数据的id分配和缓存分别是在HessianOutput和HessianInput里进行的
- 修改hessian代码,将元数据id分配和缓存的数据结构从HessianOutput和HessianInput剥离出来。
- 修改HSF代码,将上述剥离出来的数据结构作为连接级别的上下文保存起来。
- 每次构造HessianOutput和HessianInput时将其作为参数传入。这样就达了跨请求复用元数据的目的。
1 byte format: 0xxxxxxx
2 byte format: 110xxxxx 10xxxxxx
3 byte format: 1110xxxx 10xxxxxx 10xxxxxx- key类型由String改为自定义的AttributeKey,AttributeKey会在初始化阶段就去AttributeNamespace申请一个固定id
- map类型由HashMap改为自定义的DefaultAttributeMap,DefaultAttributeMap 内部使用数组存放数据
- 操作DefaultAttributeMap直接使用AttributeKey里存放的id作为index访问数组即可,避免了hash计算等一系列操作。核心就是将之前的字符串key和一个固定的id对应起来,作为访问数组的index