

Nodejs是非阻塞的,源于它是基于事件循环的设计模式,该模式也称为Reactor模式。
Nodejs同时也是单线程的,这里的单线程指的是开发人员编写的代码运行在单线程上,而Nodejs的内部一些实现代码却是多线程的,如对于I/O 的处理(读取文件、网络请求等)。关于Event Loop在另一篇文章中有粗略提到,本文将详细阐述。
但对于I/O请求不也是开发人员编写的代码吗,不是说我们自己写的代码都是运行在单线程上的,怎么这里又可能变成多线程了? 这里就要讲到reactor模式了。在此之前,先简单了解下Blocking I/O与Non-blocking I/O。
Blocking I/O vs Non-blocking I/O
Blocking I/O
Blocking I/O是程序会等待I/O请求直到结果返回,相当于控制权一直在等待I/O这边,在等待的这段时间里程序不会去干其他事,就这么一直干等着。例子如:
data = socket.read();
// wait until the data fetch back
print(data)
对于web server来说,是必须要处理多个请求的。对于Blocking I/O情况,是无法处理多个请求,每个请求都会在上一个请求处理完才能处理。解决的方法是启用多线程处理,该处理场景如下图:
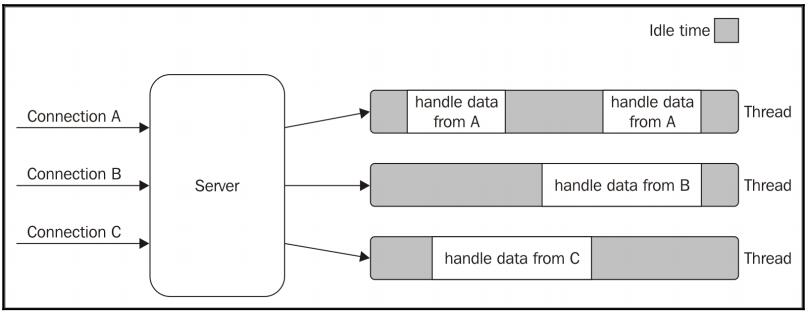
开启多个线程处理的代价有点高(内存占用,上下文切换),而且从图中看到每个线程都有很多空余时间在干等着,无法充分利用时间。
Non-blocking I/O
对于Non-blocking I/O, 一般是请求后直接返回,不用等待请求结果返回。如果没有数据可以返回的话,是直接返回一个预设好的常量标识当前还没数据可以返回。
这里首先举例一个最基本的实现方式,不断循环这些资源直到能读取到数据。
// 资源集合
resources = [socketA, socketB, pipeA];
// 只要还有资源没获取到数据,就一直循环操作
while(!resources.isEmpty()) {
for(i = 0; i < resources.length; i++) {
resource = resources[i];
// 直接返回non-blocking
// 若无数据则直接返回预设常量
let data = resource.read();
if(data === NO_DATA_AVAILABLE)
// 该资源还在等待中未准备好
continue;
if(data === RESOURCE_CLOSED)
// 该资源已经读取完毕,从集合中删除
resources.remove(i);
else
// 数据已经获取,处理数据
consumeData(data);
}
}
这样就可以做到单个线程中处理并发处理多个请求资源了。这种做法被称为busy-wait,该做法虽然使得单个线程可以处理多个并发请求,但CPU会一直消耗在轮询中,无法抽身去干其他事情。因此non-blocking I/O一般通过synchronous event demultiplexer来实现。
关于什么是 synchronous event demultiplexer,这里引用wikipedia中的一段话。
Uses an event loop to block on all resources. The demultiplexer sends the resource to the dispatcher when it is possible to start a synchronous operation on a resource without blocking
(Example: a synchronous call to read() will block if there is no data to read. The demultiplexer uses select() on the resource, which blocks until the resource is available for reading. In this case, a synchronous call to read() won't block, and the demultiplexer can send the resource to the dispatcher.)
简单来说就是,对于事件循环中的资源会通过该多路分发器(demultiplexer)下发给对应的程序去处理,处理好了则把对应事件保存到event queue中等待事件循环轮询运行。
如上述例子说的调用read()之后马上可以运行接下来的代码而不会产生阻塞,阻塞的事情交给了分发器去做了,具体怎么做每个系统有不同的实现,这就是更底层的事了。
简单例子如:
socketA, pipeB;
// 注册事件
watchedList.add(socketA, FOR_READ);
watchedList.add(pipeB, FOR_READ);
// demultiplexer blocking 等待事件完成(成功取回数据)
// events保存成功的事件
while(events = demultiplexer.watch(watchedList)) {
...
}
Reactor Pattern
Nodejs中的事件循环正是基于event demultiplexer和event queue,而这两块正是Reactor Pattern的核心。对于Nodejs的事件循环,首选要明确的一点是:
只有一个主线程执行JS代码,我们写的代码就是在该线程执行的,该线程也同是
event loop运行的线程。(并不是主线程运行JS代码,然后又有一个线程在同时运行event loop)。
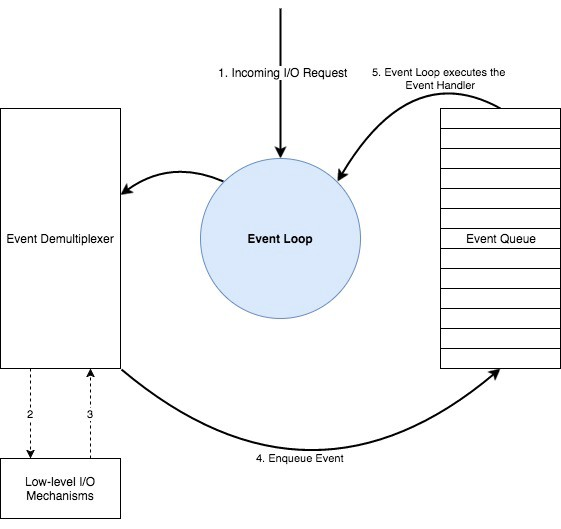
该模式执行过程大致如下图所示:
-
event demultiplexer接收到I/O请求然后下发给对应的底层去处理。 -
一旦I/O获取到了数据,
event demultiplexer会把注册的回调函数添加到event queue中等待event loop去执行。 -
event queue中的回调函数依次被event loop执行,直到event queue为空。 -
当
event queue中没数据了或者event demultiplexer没有再接受到请求,程序即event loop就会结束,意味着该应用就退出了,否则回到第一步。
Event Demultiplexer
之前已经初略讲过了Event Demultiplexer是什么了,这里详细讲下nodejs中的event demultiplexer。
event demultiplexer实际上是一个抽象的概念,不同的系统有不同的实现方式,如Linux的epoll,MacOS中的kqueue,Windows中的IOCP。nodejs则通过libuv屏蔽了对不同系统的实现支持跨平台,提供了针对多种不同I/O请求的具体处理方式的API(如File I/O,Network I/O,DNS处理等)。
可以认为libuv把这一堆复杂的东西都结合在一起形成了nodejs中的event demultiplexer。libuv结构如下图所示:
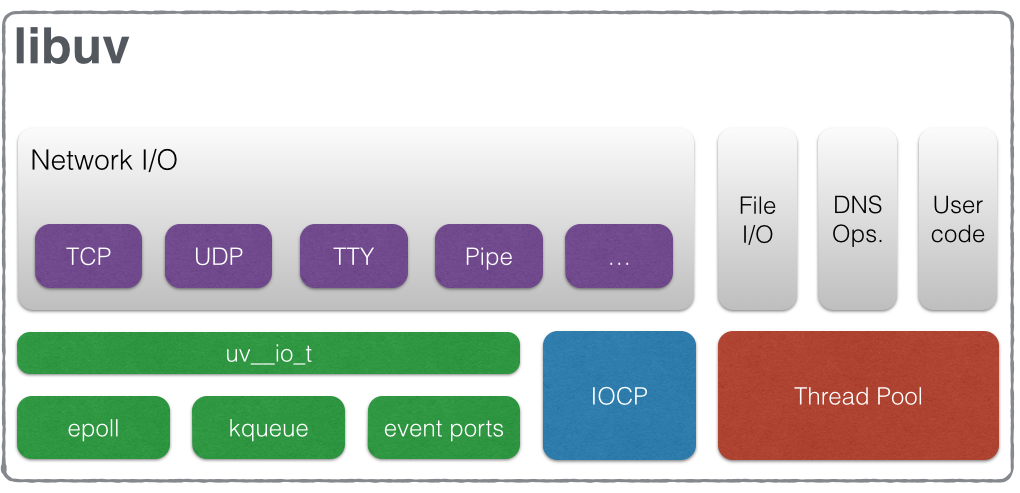
libuv中,对于一些I/O操作是直接利用系统层级I/O中的non-blocking和asynchronous特性(如提到的epoll等),但对于一些类型的I/O,由于复杂性的问题libuv则通过thread pool来处理。
所以就如同一开始说的,用户开发层面的代码是单线程的,但在I/O处理中是有可能出现多线程,但不会涉及到开发人员写的JS代码,因为thread pool是在libuv库里面的。
Event Queue
上面说到了event queue,是用来存储回调函数等待被event loop处理的。但实际上,不止一个event queue队列,事件循环要处理的主要有4个类型的队列。
- Timers and Intervals Queue: 保存
setTimeout和setInterval中的回调函数(实际上不是队列,数据结构是最小堆实现,这里就统一都叫队列了) - IO Event Queue: 保存已经完成的I/O回调函数。
- Immediates Queue: 保存
setImmediate中的回调函数。 - Close Handlers Queue: 其他所有
close事件的回调,如socket.on('close', ...)。
除了上述四个主要队列外,还有两个比较特殊的队列:
- Next Ticks Queue:保存
process.nextTick中的回调函数。 - Other Microtasks Queue:保存
Promise等microtask中的回调函数。
这里又再插一句,macrotask和microtask的区别。
那么这些队列是怎么被事件循环处理的呢?直接看图。
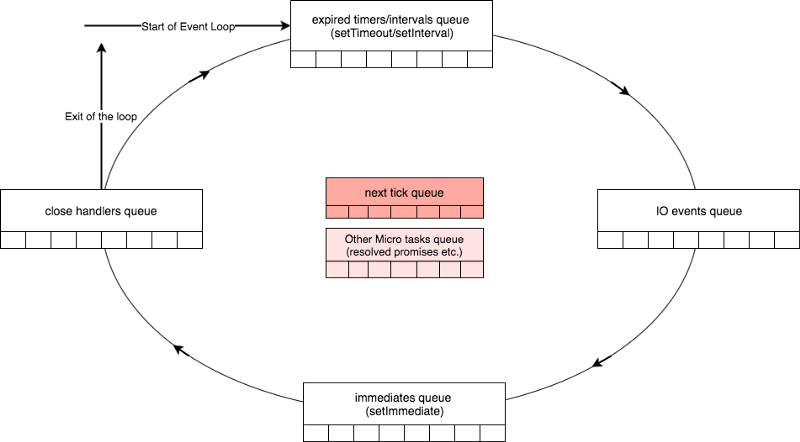
事件循环会依次处理timers and intervals queue,IO event queue,immediates queue,close handlers queue这四个队列,如果处理完close hanlers queue后,timers and intervals没有数据再进来,就退出事件循环。
处理其中一个队列的过程称为一个phase。一次事件循环就是处理这四个phase的过程。那另外两个特殊的队列是在什么时候运行的呢? 答案就是在每个 phase运行完后马上就检查这两个队列有无数据,有的话就马上执行这两个队列中的数据直至队列为空。当这两个队列都为空时,event loop 就会接着执行下一个phase。
这两个队列相比,Next Ticks Queue的权限要比Other Microtasks Queue的权限要高,因此Next Ticks Queue会先执行。
此外要注意的是,如果process.nextTick中出现递归调用没有停止条件的话,Next Ticks Queue将一直有数据进来一直都不会为空,则会阻塞event loop的执行。为了防止该情况,process.maxTickDepth定义了迭代的最大值,不过从NodeJS v0.12版本开始已经移除了。
参考
1.Event Loop and the Big Picture
2.What you should know to really understand the Node.js Event Loop
