

场景:现在需要开发一个前后端分离的应用,后端采用 RESTful API 最为方便,但是如果这个后端服务会在一天中的某些时候有高并发的情况,使用什么样的架构最为简单呢?
刚思考这个问题的时候我想到的解决方案可能有以下几种:
-
使用CDN内容分发网络,减少主服务器的压力
-
使用LVS服务器负载均衡
-
使用缓存
-
硬件层 提高带宽,使用SSD 硬盘,使用更好的服务器
-
代码层,优化代码(使用性能更好的语言等
但以上的几个方法都需要关注服务器的存储和计算资源,以便随时调整以满足更高的性能,并且高并发的请求也是分时段的,配置了更高性能的服务器在访问量变低的时候也是资源浪费。
这个时候可以使用 FaaS(Functions as a Service) 架构,跟传统架构不同在于,他们运行于无状态的容器中,可以由事件触发,短暂的,完全被第三方管理,功能上FaaS就是不需要关心后台服务器或者应用服务,只需关心自己的代码即可。其中AWS Lambda是目前最佳的FaaS实现之一。
AWS Lambda
AWS Lambda 是一项计算服务,使用时无需预配置或管理服务器即可运行代码。AWS Lambda 只在需要时执行代码并自动缩放。借助 AWS Lambda,几乎可以为任何类型的应用程序或后端服务运行代码,而且无需执行任何管理。现在 AWS Lambda 支持 Node.js、Java、C# 和 Python。
使用场景
Lambda 常见的应用场景有以下几种:
- 将Lambda 作为事件源用于 AWS 服务(比如音频上传到 s3后,触发 Lambda 音频转码服务,转码音频文件
- 通过 HTTPS (Amazon API Gateway) 实现的按需 Lambda 函数调用(配合 API Gateway创建简单的微服务
- 按需 Lambda 函数调用(使用自定义应用程序构建您自己的事件源)
- 计划的事件(比如每天晚上12点生成报表发送到指定邮箱
下图是将Lambda 作为事件源用于 AWS 服务案例的一个执行流程图:
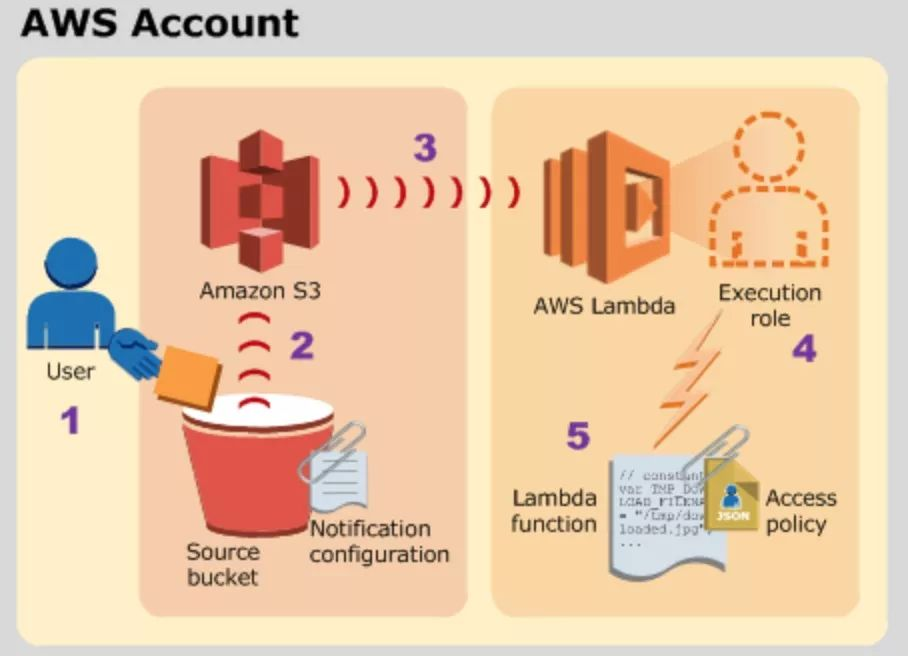
- 用户将对象上传到 S3 存储桶(对象创建事件)。
- Amazon S3 检测到对象创建事件。
- Amazon S3 调用在存储桶通知配置中指定的 Lambda 函数。
- AWS Lambda 通过代入您在创建 Lambda 函数时指定的执行角色来执行 Lambda 函数。
- Lambda 函数执行。
这篇文章主要介绍 将 Lambda 作为事件源用于 AWS 服务 和 配合 API Gateway 创建简单的微服务。
如何使用 Lambda
接下来将使用一个案例介绍如何使用 Lambda。
将 AWS Lambda 与 Amazon API Gateway 结合使用(按需并通过 HTTPS)
步骤 1:设置 AWS 账户和 AWS CLI
步骤 2:创建 HelloWorld Lambda 函数和探索控制台
创建 Hello World Lambda 函数
- 登录 AWS 管理控制台并打开 AWS Lambda 控制台。
- 选择 Get Started Now。(仅当未创建任何 Lambda 函数时,控制台才显示 Get Started Now 页面。如果您已创建函数,则会看到 Lambda > Functions 页面。在该列表页面上,选择 Create a Lambda function 转到 Lambda > New function 页面。下图是这种情况
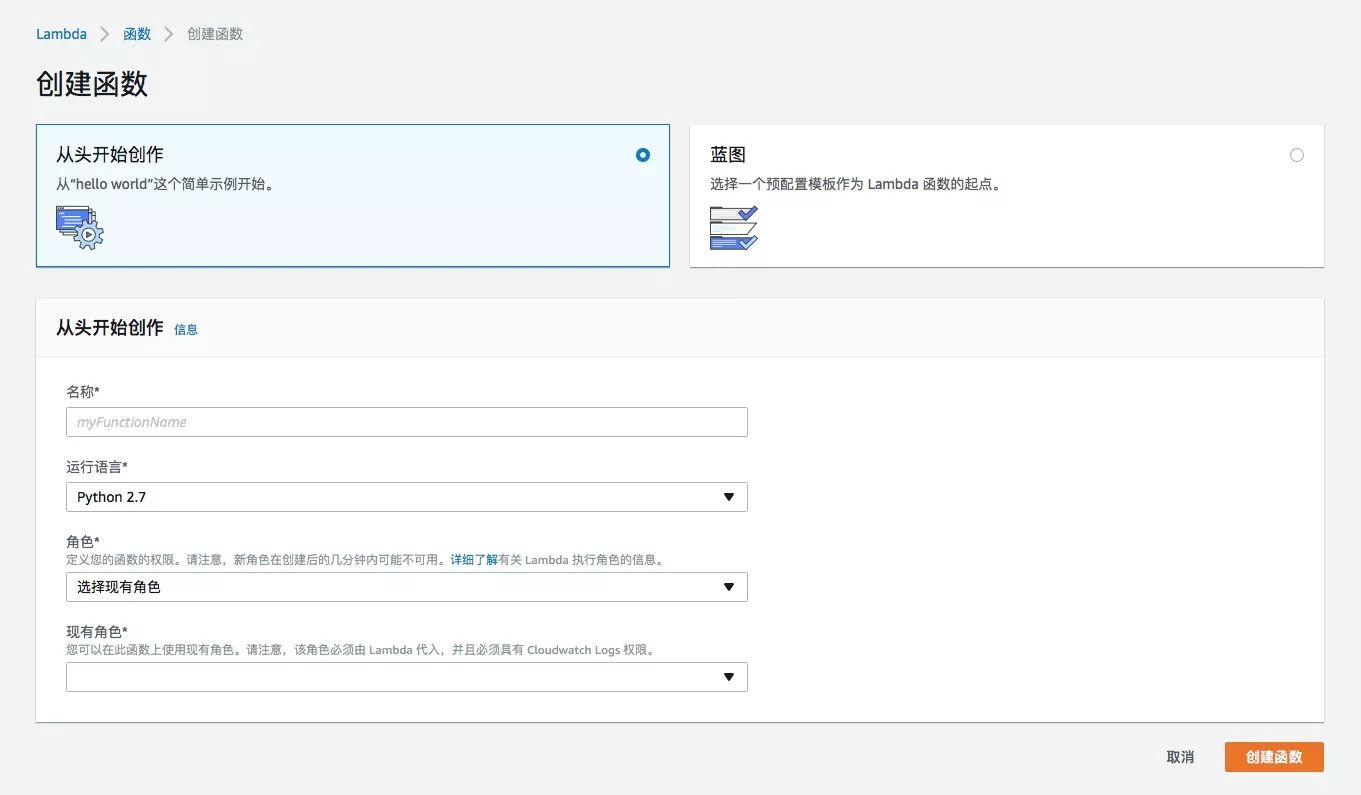
- 这里选择从头开始创作,填写函数名、选择角色,点击创建函数
- 配置创建好的Lambda函数
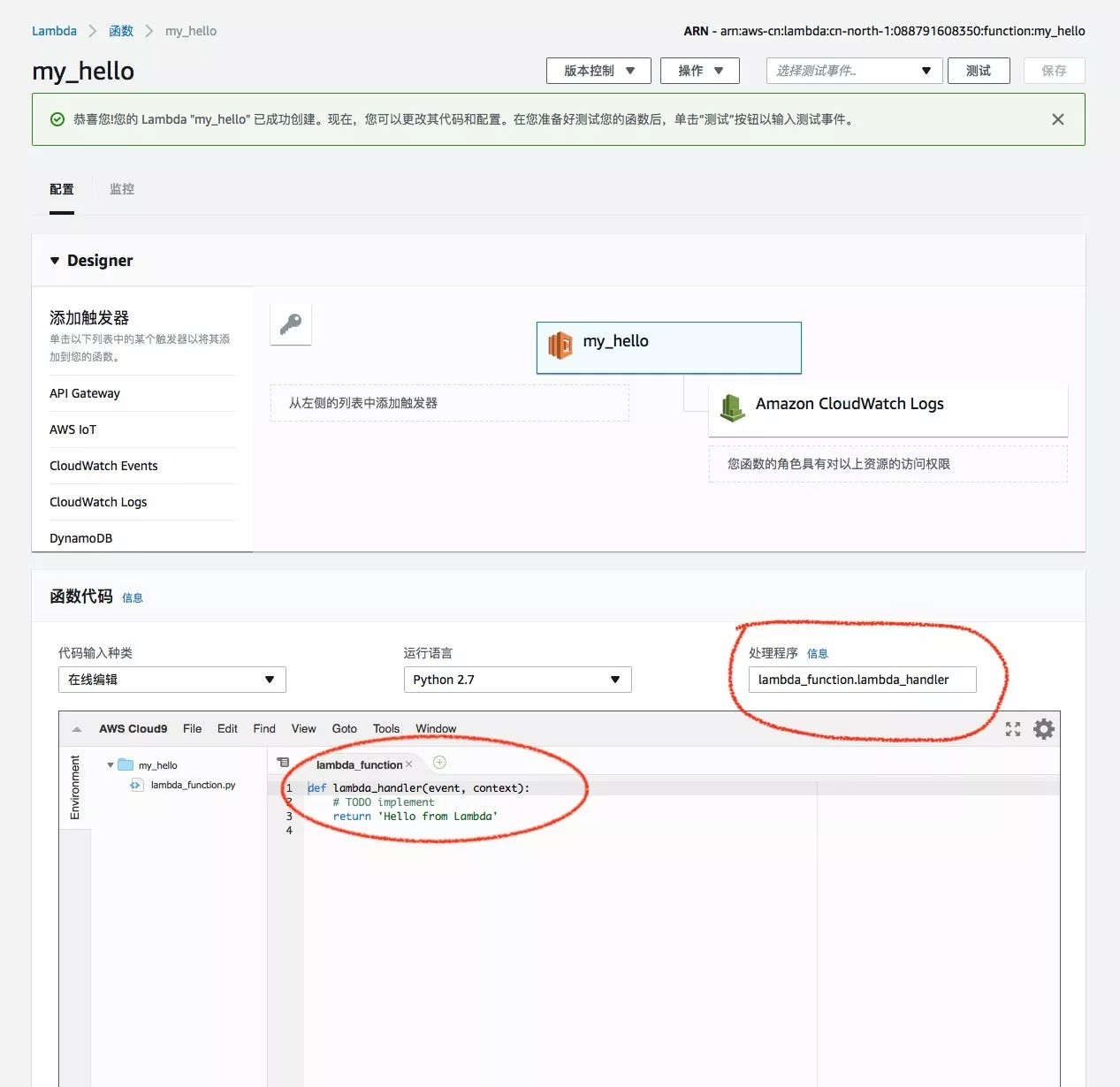
需要注意的是:处理程序填写部分为 代码文件名+文件中函数名,这里我们文件名lambda_function, 函数名是 lambda_handler,处理程序部分填写为 lambda_function.lambda_handler。
- 添加触发器,这里我们选择API Gateway ,在配置部分选择之前配置好的 API,点击添加。然后保存函数
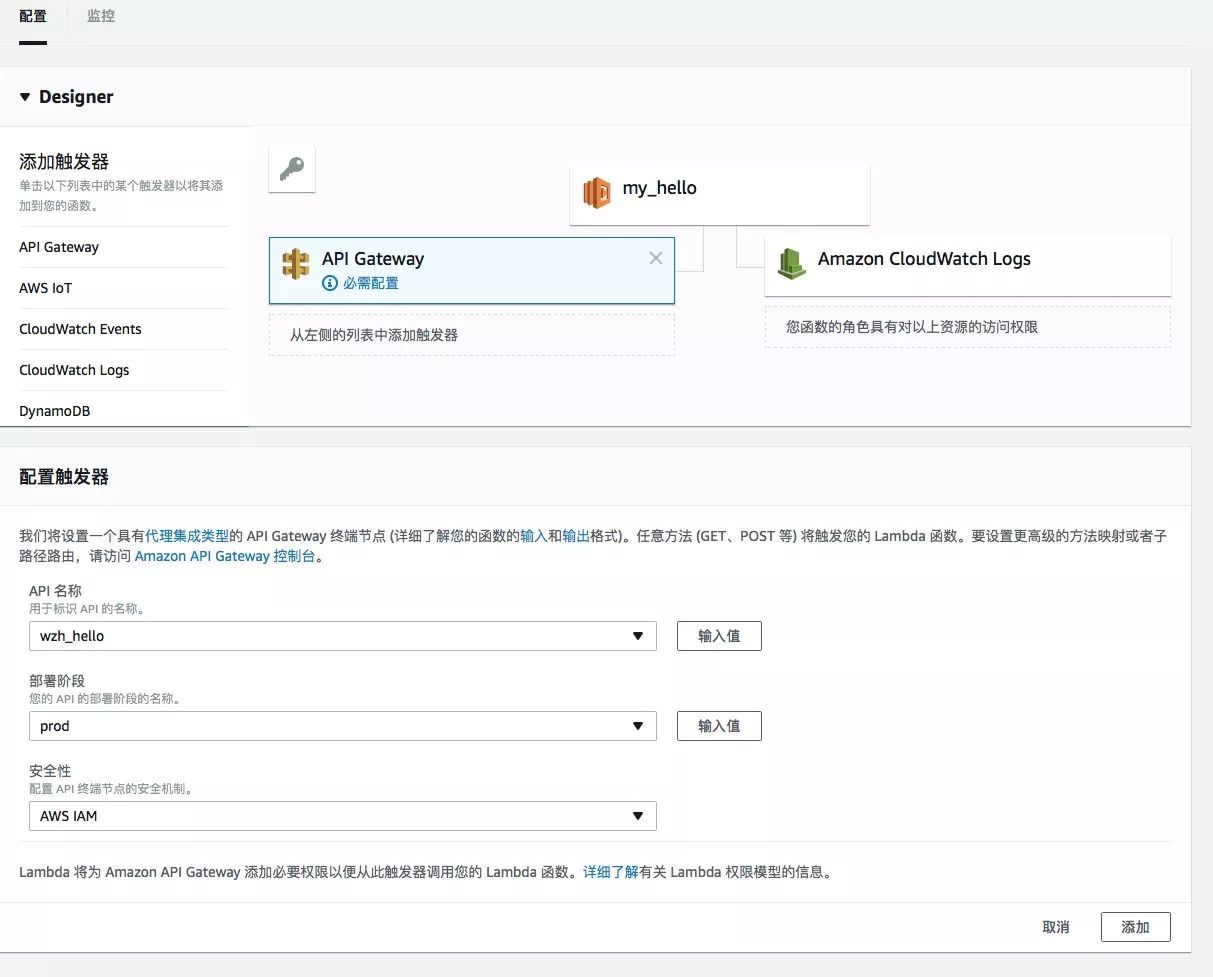
测试AWS Lambda + Amazon API Gateway
登录 aws 控制台,打开 API Gateway,选择我们刚刚选用的 API,点击测试,我们将会看到以下输出
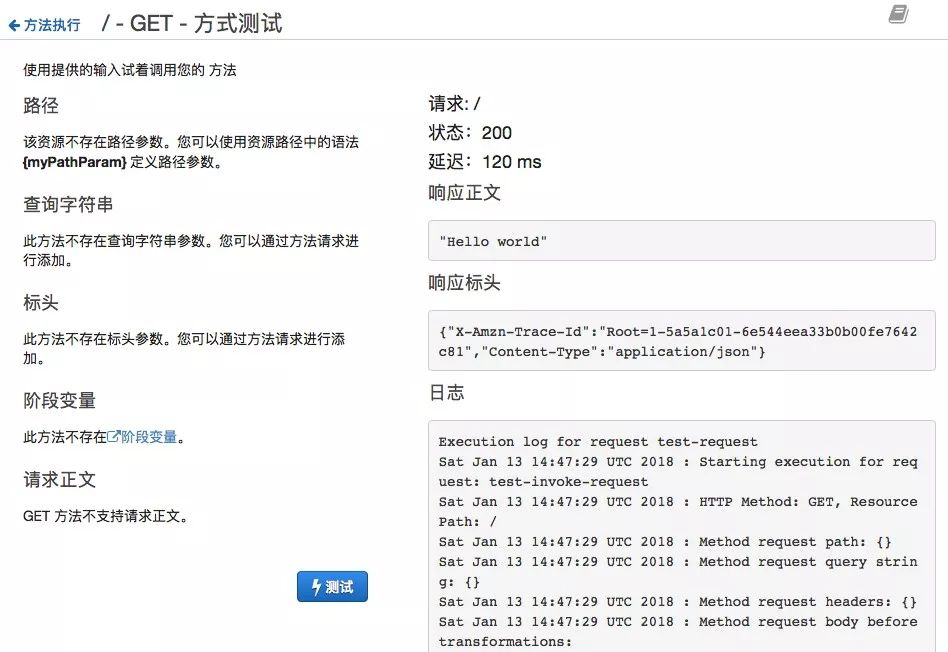
详细信息可以参考 官方文档(https://docs.aws.amazon.com/zh_cn/lambda/latest/dg/getting-started.html)
通过上面的步骤,我们了解了如何使用一个 Lambda 函数,现在我们看下如何构建 Lambda 函数。
如何构建Lambda
创建 Lambda 函数
在创建 Lambda 函数时,需要指定一个处理程序(此处理程序是代码中的函数),AWS Lambda 可在服务执行代码时调用它。在 Python 中创建处理程序函数时,使用以下一般语法结构。
def handler_name(event, context):
...
return some_value
在该语法中,需要注意以下方面:
-
event- AWS Lambda 使用此参数将事件数据传递到处理程序。此参数通常是 Pythondict类型。它也可以是list、str、int、float或NoneType类型。 -
context- AWS Lambda 使用此参数向处理程序提供运行时信息。此参数为LambdaContext类型。 -
(可选)处理程序可返回值。返回的值所发生的状况取决于调用 Lambda 函数时使用的调用类型:
-
如果使用
RequestResponse调用类型(同步执行),AWS Lambda 会将 Python 函数调用的结果返回到调用 Lambda 函数的客户端(在对调用请求的 HTTP 响应中,序列化为 JSON)。例如,AWS Lambda 控制台使用RequestResponse调用类型,因此当您使用控制台调用函数时,控制台将显示返回的值。如果处理程序返回
NONE,AWS Lambda 将返回 null。 -
如果使用
Event调用类型(异步执行),则丢弃该值。
-
context对象
在执行 Lambda 函数时,它可以与 AWS Lambda 服务进行交互以获取有用的运行时信息,例如:
- AWS Lambda 终止您的 Lambda 函数之前的剩余时间量(超时是 Lambda 函数配置属性之一)。
- 与正在执行的 Lambda 函数关联的 CloudWatch 日志组和日志流。
- 返回到调用了 Lambda 函数的客户端的 AWS 请求 ID。可以使用此请求 ID 向 AWS Support 进行任何跟进查询。
- 如果通过 AWS 移动软件开发工具包调用 Lambda 函数,则可了解有关调用 Lambda 函数的移动应用程序的更多信息。
Context 对象方法 (Python)
context 对象提供了以下方法:
get_remaining_time_in_millis()
返回在 AWS Lambda 终止函数前剩余的执行时间(以毫秒为单位)。
Context 对象属性 (Python)
context 对象提供了以下属性:
function_name
正在执行的 Lambda 函数的名称。
function_version
正在执行的 Lambda 函数版本。如果别名用于调用函数,function_version 将为别名指向的版本。
invoked_function_arn
ARN 用于调用此函数。它可以是函数 ARN 或别名 ARN。非限定的 ARN 执行 $LATEST 版本,别名执行它指向的函数版本。
memory_limit_in_mb
为 Lambda 函数配置的内存限制(以 MB 为单位)。您在创建 Lambda 函数时设置内存限制,并且随后可更改此限制。
aws_request_id
与请求关联的 AWS 请求 ID。这是返回到调用了 invoke 方法的客户端的 ID。 注意如果 AWS Lambda 重试调用(例如,在处理 Kinesis 记录的 Lambda 函数引发异常的情况下)时,请求 ID 保持不变。
log_group_name
CloudWatch 日志组的名称,可从该日志组中查找由 Lambda 函数写入的日志。
log_stream_name
CloudWatch 日志流的名称,可从该日志流中查找由 Lambda 函数写入的日志。每次调用 Lambda 函数时,日志流可能会更改,也可能不更改。如果 Lambda 函数无法创建日志流,则该值为空。当向 Lambda 函数授予必要权限的执行角色未包括针对 CloudWatch Logs 操作的权限时,可能会发生这种情况。
identity
通过 AWS 移动软件开发工具包进行调用时的 Amazon Cognito 身份提供商的相关信息。它可以为空。identity.cognito_identity_ididentity.cognito_identity_pool_id
client_context
通过 AWS 移动软件开发工具包进行调用时的客户端应用程序和设备的相关信息。它可以为空。client_context.client.installation_idclient_context.client.app_titleclient_context.client.app_version_nameclient_context.client.app_version_codeclient_context.client.app_package_nameclient_context.custom由移动客户端应用程序设置的自定义值的 dict。client_context.env由 AWS 移动软件开发工具包提供的环境信息的 dict。
示例
查看以下 Python 示例。它有一个函数,此函数也是处理程序。处理程序通过作为参数传递的 context 对象接收运行时信息。
from __future__ import print_function
import time
def get_my_log_stream(event, context):
print("Log stream name:", context.log_stream_name)
print("Log group name:", context.log_group_name)
print("Request ID:",context.aws_request_id)
print("Mem. limits(MB):", context.memory_limit_in_mb)
# Code will execute quickly, so we add a 1 second intentional delay so you can see that in time remaining value.
time.sleep(1)
print("Time remaining (MS):", context.get_remaining_time_in_millis())
此示例中的处理程序代码只打印部分运行时信息。每个打印语句均在 CloudWatch 中创建一个日志条目。如果您使用 Lambda 控制台调用函数,则控制台会显示日志。
日志记录
您的 Lambda 函数可包含日志记录语句。AWS Lambda 将这些日志写入 CloudWatch。如果您使用 Lambda 控制台调用 Lambda 函数,控制台将显示相同的日志。
以下 Python 语句生成日志条目:
print语句。logging模块中的Logger函数(例如,logging.Logger.info和logging.Logger.error)。
print 和 logging.* 函数将日志写入 CloudWatch Logs 中,而 logging.* 函数将额外信息写入每个日志条目中,例如时间戳和日志级别。
查找日志
可查找 Lambda 函数写入的日志,如下所示:
-
在 AWS Lambda 控制台中 - AWS Lambda 控制台中的 ** Log output** 部分显示这些日志。
-
在响应标头中,当您以编程方式调用 Lambda 函数时 - 如果您以编程方式调用 Lambda 函数,则可添加
LogType参数以检索已写入 CloudWatch 日志的最后 4 KB 的日志数据。AWS Lambda 在响应的x-amz-log-results标头中返回该日志信息。有关更多信息,请参阅Invoke。如果您使用 AWS CLI 调用该函数,则可指定带有值
Tail的--log-type parameter来检索相同信息。 -
在 CloudWatch 日志中 - 要在 CloudWatch 中查找您的日志,您需要知道日志组名称和日志流名称。可以使用代码中的
context.logGroupName和context.logStreamName属性来获取此信息。在运行 Lambda 函数时,控制台或 CLI 中生成的日志将会向您显示日志组名称和日志流名称。
函数错误
如果 Lambda 函数引发异常,AWS Lambda 会识别失败,将异常信息序列化为 JSON 并将其返回。考虑以下示例:
def always_failed_handler(event, context):
raise Exception('I failed!')
在调用此 Lambda 函数时,它将引发异常,并且 AWS Lambda 返回以下错误消息:
{
"errorMessage": "I failed!",
"stackTrace": [
[
"/var/task/lambda_function.py",
3,
"my_always_fails_handler",
"raise Exception('I failed!')"
]
],
"errorType": "Exception"
}
详细信息参考官方文档:https://docs.aws.amazon.com/zh_cn/lambda/latest/dg/lambda-app.html
注意事项
AWS Lambda 限制
AWS Lambda 在使用中会强加一些限制,例如,程序包的大小或 Lambda 函数在每次调用中分得的内存量。
每个调用的 AWS Lambda 资源限制
| 资源 | 限制 |
|---|---|
| 内存分配范围 | 最小值 = 128 MB/最大值 = 1536 MB (增量为 64 MB). 如果超过最大内存使用量,则函数调用将会终止。 |
| 临时磁盘容量(“/tmp”空间) | 512MB |
| 文件描述符数 | 1024 |
| 过程和线程数(合并总数量) | 1024 |
| 每个请求的最大执行时长 | 300 秒 |
| Invoke 请求正文有效负载大小 (RequestResponse/同步调用) | 6MB |
| Invoke 请求正文有效负载大小 (Event/异步调用) | 128 K |
每个区域的 AWS Lambda 账户限制
| 资源 | 默认限制 |
|---|---|
| 并发执行数 | 1000 |
并发执行是指在任意指定时间对您的函数代码的执行数量。您可以估计并发执行计数,但是,根据 Lambda 函数是否处理来自基于流的事件源的事件,并发执行计数会有所不同。
-
基于流的事件源 - 如果您创建 Lambda 函数处理来自基于流的服务(Amazon Kinesis Data Streams 或 DynamoDB 流)的事件,则每个流的分区数量是并发度单元。如果您的流有 100 个活动分区,则最多会有 100 个 Lambda 函数调用并发运行。然后,每个 Lambda 函数按照分区到达的顺序处理事件。
-
并非基于流的事件源 - 如果您创建 Lambda 函数处理来自并非基于流的事件源(例如,Amazon S3 或 API 网关)的事件,则每个发布的事件是一个工作单元。因此,这些事件源发布的事件数(或请求数)影响并发度。
您可以使用以下公式来估算并发 Lambda 函数调用数。
events (or requests) per second * function duration例如,考虑一个处理 API Gateway 的 Lambda 函数。假定 Lambda 函数平均用时 0.3 秒,API Gateway 每秒请求 1000 次。因此,Lambda 函数有 300 个并发执行。
具体信息参考Lambda 函数并行执行
**AWS Lambda 部署限制 **
| 项目 | 默认限制 |
|---|---|
| Lambda 函数部署程序包大小 (压缩的 .zip/.jar 文件) | 50 MB |
| 每个区域可以上传的所有部署程序包的总大小 | 75GB |
可压缩到部署程序包中的代码/依赖项的大小 (未压缩的 .zip/.jar 大小).注意每个 Lambda 函数都会在其的 /tmp 目录中接收到额外的 500 MB 的非持久性磁盘空间。该 /tmp 目录可用于在函数初始化期间加载额外的资源,如依赖关系库或数据集。 |
250MB |
| 环境变量集的总大小 | 4 KB |
本文内容主要参考 AWS Lambda 官方文档,详细信息请访问 https://docs.aws.amazon.com/zh_cn/lambda/latest/dg/welcome.html
参考链接
最后,感谢女朋友支持。
| 欢迎关注(April_Louisa) | 请我喝芬达 |
|---|---|
 |
 |
