

本文的叙事线索与代码示例均来自High Performance Redux,特此表示感谢。之所以感谢是因为最近一直想系统的整理在 React + Redux 技术栈下的性能优化方案,但苦于找不到切入点。在查阅资料的过程中,这份 Presentation 给了我很大的启发,它的很多观点一针见血,也与我的想法不谋而合。于是这篇文章也是参照它的讲解线索来依次展开我想表达的知识点
或许你已经听说过很多的第三方优化方案,比如immutable.js,reselect,react-virtualized等等,有关工具的故事下一篇再详谈。首先我们需要了解的是为什么会出现性能问题,以及解决性能问题的思路是什么。当你了解完这一切之后,你会发现其实很多性能问题不需要用第三方类库解决,只需要在编写代码中稍加注意,或者稍稍调整数据结构就能有很大的改观。
性能不是 patch,是 feature
每个人对性能都有自己的理解。其中有一种观点认为,在程序开发的初期不需要关心性能,当程序规模变大并且出现瓶颈之后再来做性能的优化。我不同意这种观点。性能不应该是后来居上的补丁,而应该是程序天生的一部分。从项目的第一天起,我们就应该考虑做一个10x project:即能够运行 10k 个任务并且拥有 10 年寿命
退一步说即使你在项目的后期发现了瓶颈问题,公司层面不一定会给你足够的排期解决这个问题,毕竟业务项目依然是优先的(还是要看这个性能问题有多“痛”);再退一步说,即使允许你展优化工作,经过长时间迭代开发后的项目已经和当初相比面目全非了:模块数量庞大,代码耦合严重,尤其是 Redux 项目牵一发而动全身,再想对代码进行优化的话会非常困难。从这个意义上来说,从一开始就将性能考虑进产品中去也是一种 future-proof 的体现,提高代码的可维护性
从另一个角度看,代码性能也是个人编程技艺的体现,一位优秀的程序员的代码性能应当是有保障的。
存在性能问题的列表
前端框架喜欢把实现 Todo List 作为给新手的教程。我们这里也拿一个 List 举例。假设你需要实现一个列表,用户点击有高亮效果仅此而已。特别的地方在于这个列表有 10k 的行,是的,你没看错 10k 行(上面不是说好我们要做 10x project 吗:p)
首先我们看一看基本款代码,由App组件和Item组件构成,关键代码如下:
function itemsReducer(state = initial_state, action) {
switch (action.type) {
case "MARK":
return state.map(
item =>
action.id === item.id ? { ...item, marked: !item.marked } : item
);
default:
return state;
}
}
class App extends Component {
render() {
const { items, markItem } = this.props;
return (
<div>
{items.map(({ id, marked }) => (
<Item key={id} id={id} marked={marked} onClick={markItem} />
))}
</div>
);
}
}
function mapStateToProps(state) {
return state;
}
const markItem = id => ({ type: "MARK", id });
export default connect(mapStateToProps, { markItem })(App);
这段关键的代码体现了几个关键的事实:
- 列表每一项(
item)的数据结构是{ id, marked } - 列表(
items)的数据结构是数组类型:[{id1, marked}, {id2, marked}, {id3, marked}] App渲染列表是通过遍历(map)列表数组items实现的- 当用户点击某一项时,把被点击项的
id传递给item的 reducer,reducer 通过遍历items,挨个对比id的方式找到需要被标记的项 - 重新标记完之后将新的数组返回
- 新的数组返回给
App,App再次进行渲染
如果你没法将以上代码片段和我叙述的事实拼凑在一起,可以在 github 上找到完整代码浏览或者运行。
对于这样的一个需求,相信绝大多数人的代码都是这么写的。
但是上述代码没有告诉你的事实时,这的性能很差。当你尝试点击某个选项时,选项的高亮会延迟至少半秒秒钟,用户会感觉到列表响应变慢了。
这样的延迟值并不是绝对:
- 这样的现象只有在列表项数目众多的情况下出现,比如说 10k。
- 在开发环境(
ENV === 'development')下运行的代码会比在生产环境(ENV === 'production')下运行较慢 - 我个人 PC 的 CPU 配置是 1700x,不同电脑配置的延迟会有所不同
诊断
那么问题出在哪里?我们通过 Chrome 开发者工具一探究竟(还有很多其他的 React 相关的性能工具同样也能洞察性能问题,比如 react-addons-perf, why-did-you-update,React Developer Tools 等等。但都存在或多或少的存在缺陷,使用 Chrome 开发者工具是最靠谱的)
- 本地启动项目, 打开 Chrome 浏览器,在地址栏以访问项目地址加上
react_perf后缀的方式访问项目页面,比如我的项目地址是: http://localhost:3000/ 的话,实际请访问 http://localhost:8080/?react_perf 。加上react_perf后缀的用意是启用 React 中的性能埋点,这些埋点用于统计 React 中某些操作的耗时,使用User Timing API实现 - 打开 Chrome 开发者工具,切换到 performance 面板
- 点击 performance 面板左上角的“录制”按钮,开始录制性能信息
- 点击列表中的任意一项
- 等被点击项进入高亮状态时,点击“stop”按钮停止录制性能信息
- 接下来你就能看到点击阶段的性能大盘信息:
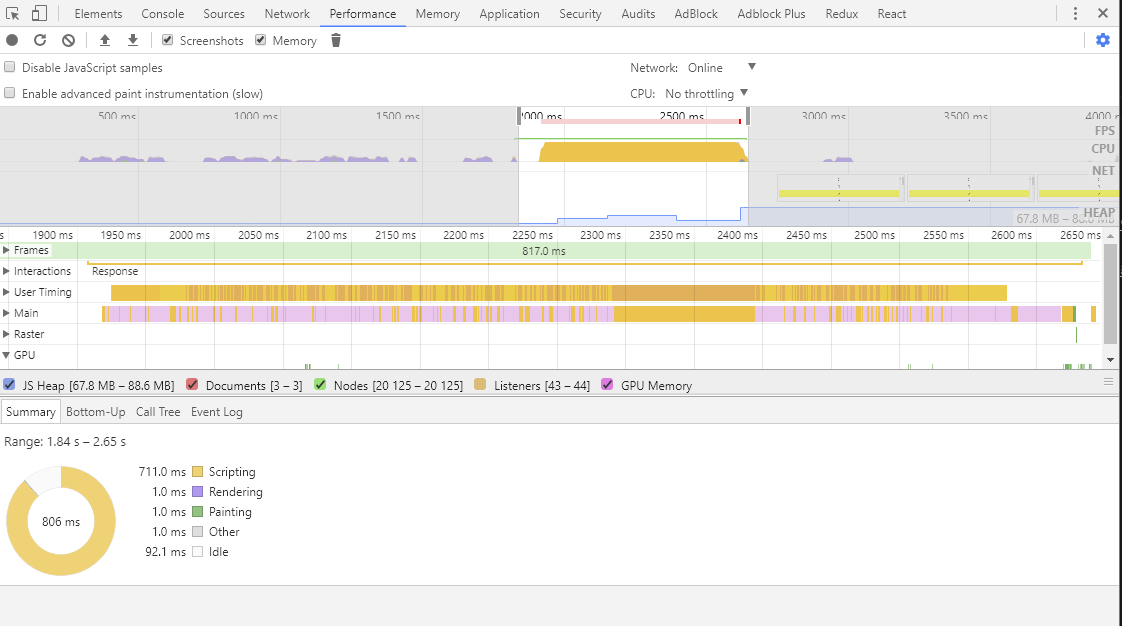
我们把目光聚焦到 CPU 活动最剧烈的那段时间内,
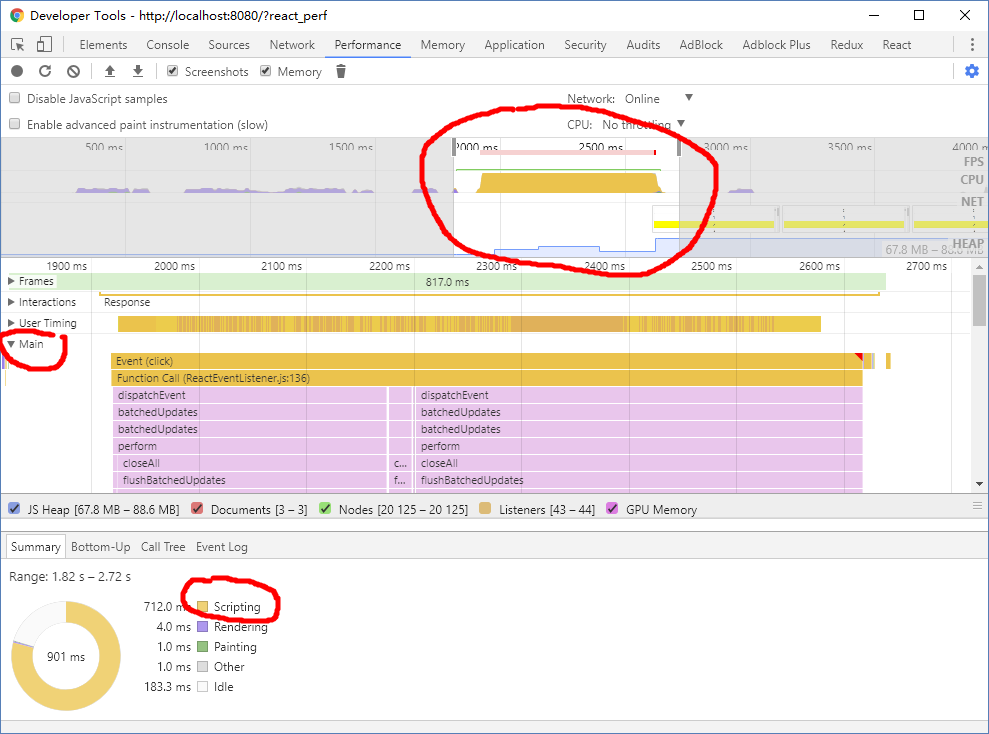
从图表中可以看出,这部分的时间(712ms)消耗基本是由脚本引起的,准确来说是由点击事件执行的脚本引起的,并且从函数的调用栈以及从时间排序中可以看出,时间基本上花费在updateComponent函数中。
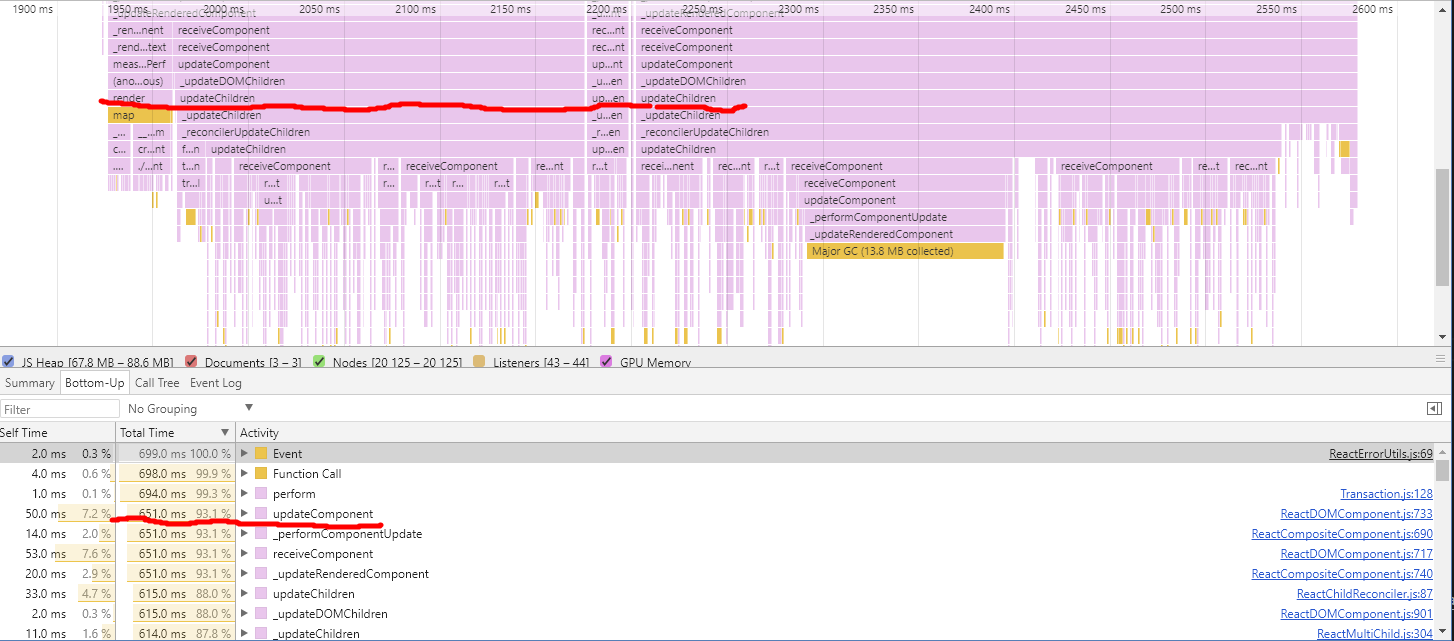
这已经能猜出一二,如果你还不确定这个函数究竟干了什么,不如展开User Timing一栏看看更“通俗”的时间消耗
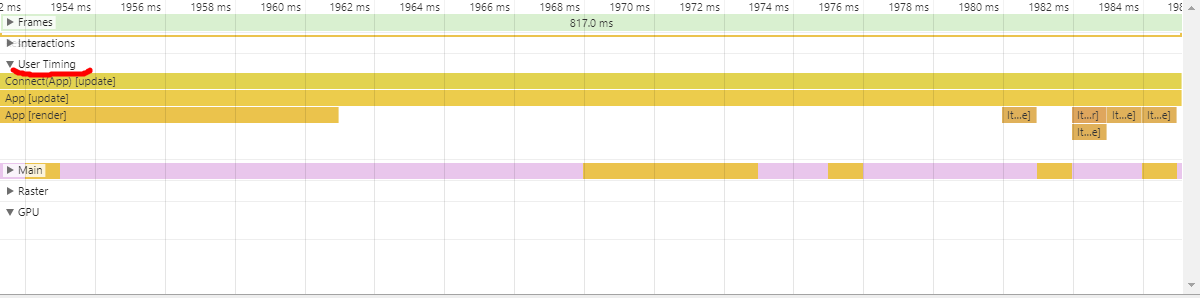
原来时间都花费在App组件的更新上,每一次App组件的更新,意味着每一个Item组件也都要更新,意味着每一个Item都要被重新渲染(执行render函数)
如果你依然觉得对以上说法表示怀疑,或者说难以想象,可以直接在App组件的render函数和Item组件的render函数加上console.log。那么每次点击时,你会看到App里的console和Item里的console都调用了 10k 次。注意此时页面会响应的更慢了,因为在控制台输出 10k 次console.log也是需要代价的
更重要的知识点在于,只要组件的状态(props或者state)发生了更改,那么组件就会默认执行render函数重新进行渲染(你也可以通过重写shouldComponentUpdate手动阻止这件事的发生,这是后面会提到的优化点)。同时要注意的事情是,执行render函数并不意味着浏览器中的真实 DOM 树需要修改。浏览器中的真实 DOM 是否需要发生修改,是由 React 最后比较 Virtual Tree 决定的。 我们都知道修改浏览器中的真实 DOM 是非常耗费性能的一件事,于是 React 为我们做出了优化。但是执行render的代价仍然需要我们自己承担
所以在这个例子中,每一次点击列表项时,都会引起 store 中items状态的更改,并且返回的items状态总是新的数组,也就造成了每次点击过后传递给App组件的属性都是新的
反击
请记住下面这个公式
UI = f(state)
你在页面上所见的,都是对状态的映射。反过来说,只要组件状态或者传递给组件的属性没有发生改变,那么组件也不会重新进行渲染。我们可以利用这一点阻止App的渲染,只要保证转递给App组件的属性不会发生改变即可。毕竟只修改一条列表项的数据却结果造成了其他 9999 条数据的重新渲染是不合理的。
但是应该如何做才能保证修改数据的同时传递给App的数据不发生变化?
通过更改数据结构
原本所有的items信息都存在数组结构里,数组结构的一个重要特性是保证了访问数据的顺序一致性。现在我们把数据拆分为两部分
- 数组结构
ids:只保留 id 用于记录数据顺序,比如:[id1, id2, id3] - 字典(对象)结构
items:以key-value的形式记录每个数据项的具体信息:{id1: {marked: false}, id2: {marked: false}}
关键代码如下:
function ids(state = [], action) {
return state;
}
function items(state = {}, action) {
switch (action.type) {
case "MARK":
const item = state[action.id];
return {
...state,
[action.id]: { ...item, marked: !item.marked }
};
default:
return state;
}
}
function itemsReducer(state = {}, action) {
return {
ids: ids(state.ids, action),
items: items(state.items, action)
};
}
const store = createStore(itemsReducer);
class App extends Component {
render() {
const { ids } = this.props;
return (
<div>
{ids.map(id => {
return <Item key={id} id={id} />;
})}
</div>
);
}
}
// App.js:
function mapStateToProps(state) {
return { ids: state.ids };
}
// Item.js
function mapStateToProps(state, props) {
const { id } = props;
const { items } = state;
return {
item: items[id]
};
}
const markItem = id => ({ type: "MARK", id });
export default connect(mapStateToProps, { markItem })(Item);
在这种思维模式下,Item组件直接与 Store 相连,每次点击时通过 id 直接找到items状态字典中的信息进行修改。因为App只关心ids状态,而在这个需求中不涉及增删改,所以ids状态永远不会发生改变,在Mounted之后,App再也不会更新了。所以现在无论你如何点击列表项,只有被点击的列表项会更新。
很多年前我写过一篇文章:《在 Node.js 中搭建缓存管理模块》,里面提到过相同的解决思路,有更详细的叙述
在这一小节的结尾我要告诉大家一个坏消息:虽然我们可以精心设计状态的数据结构,但在实际工作中用来展示数据的控件,比如表格或者列表,都有各自独立的数据结构的要求,所以最终的优化效果并非是理想状态
阻止渲染的发生
让我们回到最初发生事故的代码,它的问题在于每次在渲染需要高亮的代码时,无需高亮的代码也被渲染了一遍。如果能避免这些无辜代码的渲染,那么同样也是一种性能上的提升。
你肯定已经知道在 React 组件生命周期就存在这样一个函数 shoudlComponentUpdate 可以决定是否继续渲染,默认情况下它返回true,即始终要重新渲染,你也可以重写它让它返回false,阻止渲染。
利用这个生命周期函数,我们限定只允许marked属性发生前后发生变更的组件进行重新渲染:
class Item extends Component {
constructor() {
//...
}
shouldComponentUpdate(nextProps) {
if (this.props["marked"] === nextProps["marked"]) {
return false;
}
return true;
}
虽然每次点击时App组件仍然会重新渲染,但是成功阻止了其他 9999 个Item组件的渲染
事实上 React 已经为我们实现了类似的机制。你可以不重写shouldComponentUpdate, 而是选择继承React.PureComponent:
class Item extends React.PureComponent
PureComponent与Component不同在于它已经为你实现了shouldComponentUpdate生命周期函数,并且在函数对改变前后的 props 和 state 做了“浅对比”(shallow comparison),这里的“浅”和“浅拷贝”里的浅是同一个概念,即比较引用,而不比较嵌套对象里更深层次的值。话说回来 React 也无法为你比较嵌套更深的值,一方面这也耗时的操作,违背了shouldComponentUpdate的初衷,另一方面复杂的状态下决定是否重新渲染组件也会有复杂的规则,简单的比较是否发生了更改并不妥当
反面教材(anti-pattern)
残酷的现实是,即使你理解了以上的知识点,你可能仍然对日常代码中的性能陷阱浑然不知,
比如设置缺省值的时候:
<RadioGroup options={this.props.options || []} />
如果每次 this.props.options 值都是 null 的话,意味着每次传递给<RadioGroup />都是字面量数组[],但字面量数组和new Array()效果是一样的,始终生成新的实例,所以表面上看虽然每次传递给组件的都是相同的空数组,其实对组件来说每次都是新的属性,都会引起渲染。所以正确的方式应该将一些常用值以变量的形式保存下来:
const DEFAULT_OPTIONS = []
<RadioGroup options={this.props.options || DEFAULT_OPTIONS} />
又比如给事件绑定函数的时候
<Button onClick={this.update.bind(this)} />
或者
<Button
onClick={() => {
console.log("Click");
}}
/>
在这两种情况下,对于组件来说每次绑定的都是新的函数,所以也会造成重新渲染。关于如何在eslint中加入对.bind方法和箭头函数的检测,以及解决之道请参考No .bind() or Arrow Functions in JSX Props (react/jsx-no-bind)
结尾
下一篇我们学习如何借助第三方类库,比如immutablejs和reselect对项目进行优化
这篇文章同时也发表在我的 知乎前端专栏,欢迎大家关注
