

前言
最近笔者读了《深入剖析tomcat》这本书(原作:《how tomcat works》),发现该书简单易读,每个
章节循序渐进的讲解了tomcat的原理,在接下来的章节中,tomcat都是基于上一章新增功能并完善,
到最后形成一个简易版tomcat的完成品。所以有兴趣的同学请按顺序阅读,本文为记录第三章的知识点
以及源码实现(造轮子)。
内容回顾
跟我一起动手实现Tomcat(二):实现简单的Servlet容器
上一章我们实现了一个简单的Servlet容器,能够调用并执行用户自定义实现Servlet接口的类。
本章内容
- 模块模仿tomcat,实现Connector(连接器)、Bootstrap(启动器)和核心模块。
- 能够执行继承HttpServlet类的自定义Servlet(上一章是实现了Servlet接口)
- 能够解析用户请求参数(Parameters)/Cookie/请求头(Header)
开始之前
简单介绍Connector(连接器)
对Tomcat比较熟悉的朋友对这个词应该不陌生,后面的篇幅会继续比较详细介绍,在这里不熟悉的朋友可以理解为:连接器只是负责接收请求,然后将请求丢给Container(容器)去执行相应的请求。
javax.servlet.http.HttpServlet类
上一章我们自定义的Servlet是实现了Servlet接口,实例化Servlet的时候我们是将解析的Request/Response(分别实现了ServletRequest/ServletResponse接口)传入对应的service()方法中完成执行。
那我们来回顾一下刚学Servlet开发的时候,大部分教程都按顺序讲解实现Servlet接口、继承GenericServlet类、继承HttpServlet类这三种方式去写自己的Servlet,那么后面推荐的仍然是最后一种,重写其中的doGet()/doPost()方法即可,那么我们来看看上一章我们的tomcat能不能支持继承HttpServlet类的Servlet呢:
//HttpServlet源代码片段
public abstract class HttpServlet extends GenericServlet {
...
public void service(ServletRequest req, ServletResponse res)
throws ServletException, IOException{
HttpServletRequest request;
HttpServletResponse response;
//如果传进来的request/response对象不是Http类型的则抛异常
if (!(req instanceof HttpServletRequest &&
res instanceof HttpServletResponse)) {
throw new ServletException("non-HTTP request or response");
}
request = (HttpServletRequest) req;
response = (HttpServletResponse) res;
service(request, response);
}
...
}
如上所示源码,再来看看我们上一章的ServletProcess调用Servlet源码:
servlet.service(new RequestFacade(request), new ResponseFacade(response));
很明显上一章的request/response在HttpServlet时会抛出异常,所以本章我们会将Request/Response以及它们的外观类都实现HttpServletRequest/HttpServletResponse接口。
代码实现
在代码实现前我们看看整体模块以及流程执行图(看不清可以点击放大):

1. Bootstrap模块
启动模块目前我们没有多大工作,只是启动HttpConnector:
public final class Bootstrap {
public static void main(String[] args){
new HttpConnector().start();
}
}
2. HttpConnector模块(连接器)
连接器模块和下面的核心模块的前身其实就是上一章的HttpServer类,我们把它按功能拆分成了
等待和建立连接(HttpConnector)/处理连接(HttpProcess)2个模块。
连接器功能是等待请求并将请求丢给相应执行器去执行:
public class HttpConnector implements Runnable {
public void start(){
new Thread(this).start();
}
@Override
public void run() {
ServerSocket serverSocket = new ServerSocket(8080, 1, InetAddress.getByName("127.0.0.1"));
while (true) {
Socket accept = serverSocket.accept();
HttpProcess process = new HttpProcess(this);
process.process(accept);
}
serverSocket.close();
}
}
3. 核心模块(执行器)
上面也有说到,执行器也是上一章HttpServer类的前身,只不过这章我们修改了解析请求信息的方式。
- 主要代码
public class HttpProcess {
private HttpRequest request;
private HttpResponse response;
public void process(Socket socket) {
InputStream input = socket.getInputStream();
OutputStream output = socket.getOutputStream();
//初始化request以及response
request = new HttpRequest(input);
response = new HttpResponse(output, request);
//解析request请求行和请求头
this.parseRequestLine(input);
this.parseHeaders(input);
//调用对应的处理器处理
if (request.getRequestURI().startsWith(SERVLET_URI_START_WITH)) {
new ServletProcess().process(request, response);
} else {
new StaticResourceProcess().process(request, response);
}
}
}
看了上面的实现可能很多人对有些对象有点陌生,下面一一介绍:
1. HttpRequest/HttpResponse变量就是上一章的Request/Response对象,因为实现了
HttpServletReuqest/HttpServletResponse也就顺便改了个名,将会在下面介绍;
2. 每一个请求都对应了一个HttpProcess对象,所以这里request/response是成员变量;
3. 解析请求行和解析请求头的方法也在下面介绍。

parseRequestLine、parseHeaders方法
让我们先看看一个原始的HTTP请求字符串,看看如何去解析请求行和请求头:
GET /index.html?utm_source=aaa HTTP/1.1\r\n
Host: www.baidu.com\r\n
Connection: keep-alive\r\n
Pragma: no-cache\r\n
Cache-Control: no-cache\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36\r\n
Accept: text/html\r\n
Accept-Encoding: gzip, deflate, sdch, br\r\n
Accept-Language: zh-CN,zh;q=0.8\r\n
Cookie: BAIDUID=462A9AC35EE6158AA7DFCD27AF:FG=1; BIDUPSID=462A9AC35EE6158AA7DF027AF; PSTM=1506310304; BD_CK_SAM=1; PSINO=7; BD_HOME=1; H_PS_PSSID=1459_24885_21115_25436; BD_UPN=12314353; sug=3; sugstore=0; ORIGIN=2; bdime=0\r\n大家可以发现,其实我们使用socket读取HTTP请求时候,发现每一行都会有'\r\n'这个回车换行符,只不过在我们浏览器按F12时被浏览器自动解析成了换行而已,我们分析上面的这个请求信息得出以下规律:
- 每一行结尾字符都是\r\n
- 请求行(第一行)的HTTP请求方法、URI、请求协议中间都有个空格
- 第二行开始(请求头)key和value的内容都是以':'和一个' '字符隔开
- Cookie的键值对是以'='分割,以';'和' '区分前后键值对接下来我们分别去解析以下ISO-8859-1编码情况下上面字符对应的值,并建立一个常量类:
public class HttpConstant {
/* 回车 \r */
public static final byte CARRIAGE_RETURN = 13;
/* 换行 \n */
public static final byte LINE_FEED = 10;
/* 空格 */
public static final byte SPACE = 32;
/* 冒号 : */
public static final byte COLON = 58;
}1.parseRequestLine方法
根据上面的思路,我们就可以轻松地解析请求行的数据:
StringBuilder temp = new StringBuilder();
int cache;
while ((cache = requestStream.read()) != -1) {
//读取到第一个\r\n时则说明读取请求行完毕
if (HttpConstant.CARRIAGE_RETURN == cache && HttpConstant.LINE_FEED == requestStream.read()) {
break;
}
temp.append((char)cache);
}
String[] requestLineArray = temp.toString().split(" ");最后分割空格使用数组装着请求行(如果你有更好的方案也可以在评论区说一说哈)
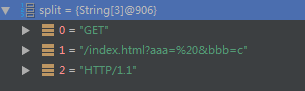
接下来判断URI有没有使用"?"传递参数,如果有就截取并丢到HttpRequest的QueryString变量中,
最后截取URI即可。
String uri = requestLineArray[1];
int question = uri.indexOf("?");
if (question >= 0) {
request.setQueryString(uri.substring(question+1,uri.length()));
uri = uri.substring(0,question);
}
判断是不是从?传递jsessionid过来,如果是就赋值到request对象中
String match = ";jsessionid=";
int semicolon = uri.indexOf(match);
if (semicolon >= 0) {
String rest = uri.substring(semicolon + match.length());
int semicolon2 = rest.indexOf(';');
if (semicolon2 >= 0) {
request.setRequestedSessionId(rest.substring(0, semicolon2));
rest = rest.substring(semicolon2);
} else {
request.setRequestedSessionId(rest);
rest = "";
}
request.setRequestedSessionURL(true);
uri = uri.substring(0, semicolon) + rest;
} else {
request.setRequestedSessionId(null);
request.setRequestedSessionURL(false);
}
这里调用了一个校验URI合法性的方法,如果URI不合法(例如包含'.//'之类跳转目录的危险字符)
则抛异常,否则就将上面解析到的内容丢到request中去。
String normalizedUri = this.normalize(uri);
if (normalizedUri == null) {
throw new ServletException("Invalid URI: " + uri + "'");
}
request.setRequestURI(normalizedUri);
request.setMethod(requestLineArray[0]);
request.setProtocol(requestLineArray[2]);
就这样,请求行的信息就被我们读取完毕,那我们再来看看读取请求头的代码:
parseHeaders方法
这里有个坑:Socket的read()方法读取完毕时最后一个字节不是-1,而是阻塞等待Socket客户端发送-1过来结束读取,但是我们的Socket客户端是浏览器,浏览器不会发送-1以表示结束发送,所以我们结合InputStream#available()方法(返回实际还可以读取的字节数)来判断是否读取完毕即可。
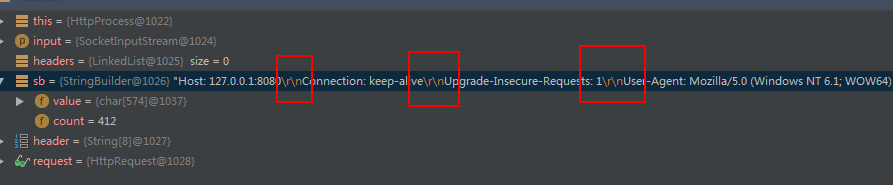
public void parseHeader() {
StringBuilder sb = new StringBuilder();
int cache;
while (input.available() > 0 && (cache = input.read()) > -1) {
sb.append((char)cache);
}
....看下文
}
读取完毕效果如图:
如果是POST请求,那么表单参数会在空行后面:
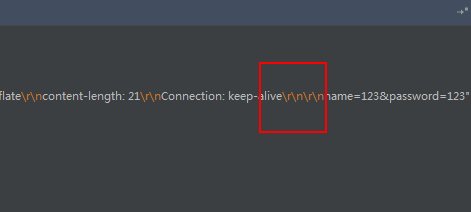
也很有规律,请求头都用\r\n隔开,并且如果是POST请求提交表单,那么表单参数会在一个空行后面(两个\r\n)
//使用\r\n分割请求头
Queue<String> headers = Stream.of(sb.toString().split("\r\n")).collect(toCollection(LinkedList::new));
while (!headers.isEmpty()) {
//获取一个请求头
String headerString = headers.poll();
//读取到空行则说明请求头已读取完毕
if (StringUtil.isBlank(headerString)) {
break;
}
//分割请求头的key和value
String[] headerKeyValue = headerString.split(": ");
request.addHeader(headerKeyValue[0], headerKeyValue[1]);
}
//如果在读取到空行后还有数据,说明是POST请求的表单参数
if(!headers.isEmpty()){
request.setPostParams(headers.poll());
}
大致流程:
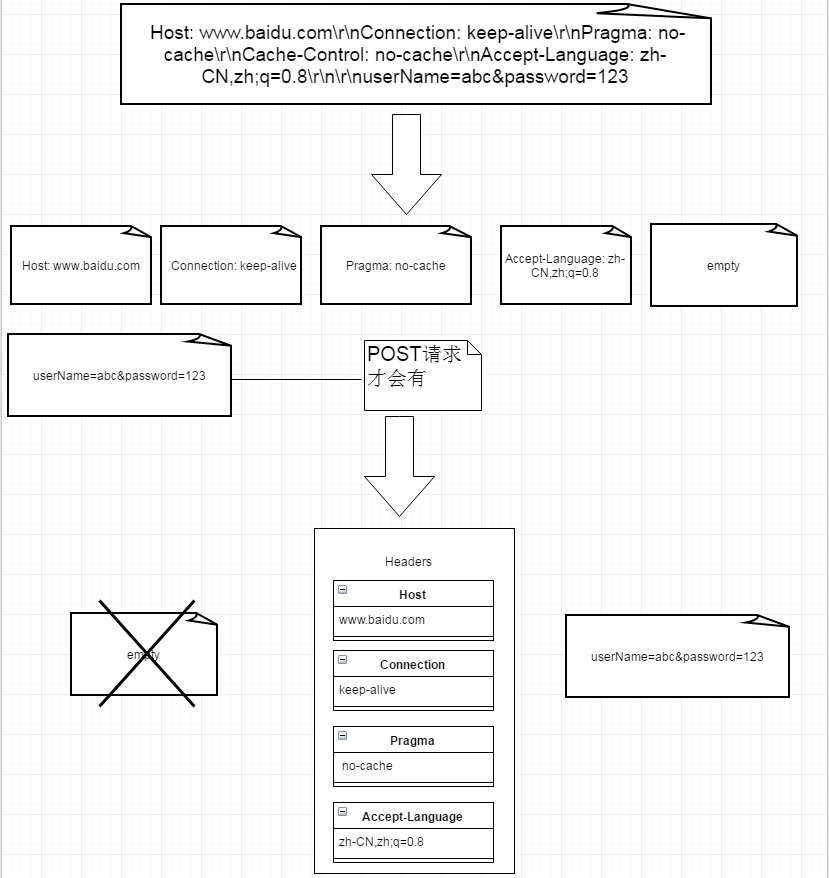
最后我们对一些特殊的请求头信息设置到Request对象中(cookie、content-type、content-length);
String contentLength = request.getHeader("content-length");
if(contentLength!=null){
request.setContentLength(Integer.parseInt(contentLength));
}
request.setContentType(request.getHeader("content-type"));
Cookie[] cookies = parseCookieHeader( request.getHeader("cookie"));
Stream.of(cookies).forEach(cookie -> request.addCookie(cookie));
//如果sessionid不是从cookie中获取的,则优先使用cookie中的sessionid
if (!request.isRequestedSessionIdFromCookie()) {
Stream.of(cookies)
.filter(cookie -> "jsessionid".equals(cookie.getName()))
.findFirst().
ifPresent(cookie -> {
//设置cookie的值
request.setRequestedSessionId(cookie.getValue());
request.setRequestedSessionCookie(true);
request.setRequestedSessionURL(false);
});
}
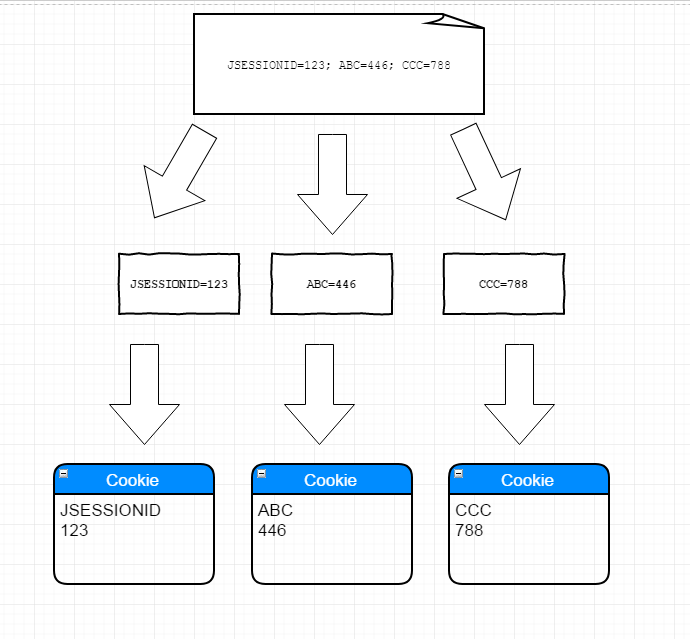
读取cookie的方法也很简单:
private Cookie[] parseCookieHeader(String cookieListString) {
return Stream.of(cookieListString.split("; "))
.map(cookieStr -> {
String[] cookieArray = cookieStr.split("=");
return new Cookie(cookieArray[0], cookieArray[1]);
}).toArray(Cookie[]::new);
}
不熟悉JDK8语法的小伙伴们可能看不太懂干了什么,没关系来张图解释一下上面那段代码内容:
到这里,HttpProcess处理请求的逻辑就搞定啦,(是不是觉得代码有点多),细心的客官们一定发现了,request怎么可以设置那么多属性呢?上一章的request好像没有那么多功能吧?是的,我们这一章也对request/response做了手脚,请看下文分析:

HttpRequest(上一章的Request对象)
没错,在文章的开头我们已经说了要把Request升级一下,那么怎么升级呢?也就是实现HttpServletRequest接口啦:
public class HttpRequest implements HttpServletRequest {
private String contentType;
private int contentLength;
private InputStream input;
private String method;
private String protocol;
private String queryString;
private String postParams;
private String requestURI;
private boolean requestedSessionCookie;
private String requestedSessionId;
private boolean requestedSessionURL;
protected ArrayList<Cookie> cookies = new ArrayList<>();
protected HashMap<String, ArrayList<String>> headers = new HashMap<>();
protected ParameterMap parameters;
...
}哈哈没有看错,多了一堆参数,但是细心的客官们应该可以看到,这些参数都是非常眼熟,而且上面已经对大部分参数设值过了,眼生的可能就是下面的那个ParameterMap,那么等下我们慢慢分析:(那些get、set方法就不分析了)
请求头(header)操作:
public void addHeader(String name, String value) {
name = name.toLowerCase();
//如果key对应的value不存在则new一个ArrayList
ArrayList<String> values = headers.computeIfAbsent(name, k -> new ArrayList<>());
values.add(value);
}
public ArrayList getHeaders(String name) {
name = name.toLowerCase();
return headers.get(name);
}
public String getHeader(String name) {
name = name.toLowerCase();
ArrayList<String> values = headers.get(name);
if (values != null) {
return values.get(0);
} else {
return null;
}
}
public ArrayList getHeaderNames() {
return new ArrayList(headers.keySet());
}大家可以看到请求头是是个Map,key是请求头的名字,value则是请求头的内容数组(一个请求头可以有多个内容),所以也就是对这个Map做操作而已~
Cookie操作:
public Cookie[] getCookies() {
return cookies.toArray(new Cookie[cookies.size()]);
}
public void addCookie(Cookie cookie) {
cookies.add(cookie);
}好像也没什么好说的,对List\做常规操作。
Parameters操作:
这是我们最常用的一个操作啦,那么ParameterMap是个什么东西呢,我们先来看看:public final class ParameterMap extends HashMap<String,String[]> {
private boolean locked = false;
public boolean isLocked() {
return locked;
}
public void setLocked(boolean locked) {
this.locked = locked;
}
public String[] put(String key, String[] value) {
if (locked) {
throw new IllegalStateException("error");
}
return (super.put(key, value));
}
...
}好吧其实它就是在HashMap基础上加了一个locked对象(如果已经解析参数完毕了则将这个对象设置为true禁止更改),key是参数名,value是参数值数组(可有多个)
例如:127.0.0.1:8080/servlet/QueryServlet?name=geoffrey&name=yip那么我们来看看对parameter这个map的操作有:
public String getParameter(String name) {
parseParameters();
String[] values = parameters.get(name);
return Optional.ofNullable(values).map(arr -> arr[0]).orElse(null);
}
public Map getParameterMap() {
parseParameters();
return this.parameters;
}
public ArrayList<String> getParameterNames() {
parseParameters();
return new ArrayList<>(parameters.keySet());
}
public String[] getParameterValues(String name) {
parseParameters();
return parameters.get(name);
}代码都很简单,但是这个parseParameters()是什么呢,对,它是去解析请求的参数了(懒加载),因为我们不知道用户使用Servlet会不会用到请求参数这个功能,而且解析它的开销比解析其他数据大,所以我们会在用户真正使用参数的时候才会去解析,提高整体的响应速度,大概的代码如下:
protected void parseParameters() {
if (parsed) {
//已经解析过则停止解析
return;
}
ParameterMap results = parameters;
if (results == null) {
results = new ParameterMap();
}
results.setLocked(false);
String encoding = getCharacterEncoding();
if (encoding == null) {
encoding = StringUtil.ISO_8859_1;
}
// 解析URI携带的请求参数
String queryString = getQueryString();
this.parseParameters(results, queryString, encoding);
// 初始化Content-Type的值
String contentType = getContentType();
if (contentType == null) {
contentType = "";
}
int semicolon = contentType.indexOf(';');
if (semicolon >= 0) {
contentType = contentType.substring(0, semicolon).trim();
} else {
contentType = contentType.trim();
}
//解析POST请求的表单参数
if (HTTPMethodEnum.POST.name().equals(getMethod()) && getContentLength() > 0
&& "application/x-www-form-urlencoded".equals(contentType)) {
this.parseParameters(results, getPostParams(), encoding);
}
//解析完毕就锁定
results.setLocked(true);
parsed = true;
parameters = results;
}
/**
* 解析请求参数
* @param map Request对象中的参数map
* @param params 解析前的参数
* @param encoding 编码
*/
public void parseParameters(ParameterMap map, String params, String encoding) {
String[] paramArray = params.split("&");
Stream.of(paramArray).forEach(param -> {
String[] splitParam = param.split("=");
String name = splitParam[0];
String value = splitParam[1];
//此处是将key和value使用URLDecode解码并添加进map中
putMapEntry(map, urlDecode(name, encoding), urlDecode(value, encoding));
});
}大概内容就是根据之前HttpProcess解析请求行的queryString参数以及如果是POST请求的表单数据放入ParameterMap中,并且锁定Map。
HttpResponse(上一章的Response对象)
HttpResponse对象也跟随者实现了HttpServletResponse接口,但是本章没有实现具体的内容,所以此处略过。
public class HttpResponse implements HttpServletResponse {
...
}ServletProcess
ServletProcess具体只需要将request和response的外观类跟着升级实现对应的接口即可:
public void process(HttpRequest request, HttpResponse response) throws IOException {
...
servlet.service(new HttpRequestFacade(request), new HttpResponseFacade(response));
...
}
public class HttpRequestFacade implements HttpServletRequest {
private HttpRequest request;
...
}
public class HttpResponseFacade implements HttpServletResponse {
private HttpResponse response;
...
}
实验
我们先编写一个Servlet:
/**
* 测试注册Servlet
*/
public class RegisterServlet extends HttpServlet {
@Override
public void doGet(HttpServletRequest req, HttpServletResponse resp) {
//打印表单参数
String name = req.getParameter("name");
String password = req.getParameter("password");
if (StringUtil.isBlank(name) || StringUtil.isBlank(password)) {
try {
resp.getWriter().println("账号/密码不能为空!");
} finally {
return;
}
}
//打印请求行
System.out.println("Parse user register method:" + req.getMethod());
//打印Cookie
System.out.println("Parse user register cookies:");
Optional.ofNullable(req.getCookies())
.ifPresent(cookies ->
Stream.of(cookies)
.forEach(cookie ->System.out.println(cookie.getName() + ":" + cookie.getValue()
)));
//打印请求头
System.out.println("Parse http headers:");
Enumeration<String> headerNames = req.getHeaderNames();
while (headerNames.hasMoreElements()) {
String headerName = headerNames.nextElement();
System.out.println(headerName + ":" + req.getHeader(headerName));
}
System.out.println("Parse User register name :" + name);
System.out.println("Parse User register password :" + password);
try {
resp.getWriter().println("注册成功!");
} finally {
return;
}
}
@Override
public void doPost(HttpServletRequest req, HttpServletResponse resp) {
this.doGet(req, resp);
}
}
编写一个HTML:
<html>
<head>
<title>注册</title>
</head>
<body>
<form method="post" action="/servlet/RegisterServlet">
账号:<input type="text" name="name"><br>
密码:<input type="password" name="password"><br>
<input type="submit" value="提交">
</form>
</body>
</html>
打开浏览器测试:


控制台输出:
到这里,咱们的Tomcat 3.0 web服务器就已经开发完成啦(滑稽脸),已经可以实现简单的自定义Servlet调用,以及请求行/请求头/请求参数/cookie等信息的解析,待完善的地方还有很多:
- HTTPProcess一次性只能处理一个请求,其他请求只能堵塞,不具备服务器使用性。
- 每一次请求就new一次Servlet,Servlet应该在初始化项目时就应该初始化,是单例的。
- 并未遵循Servlet规范实现相应的生命周期,例如init()/destory()方法我们均未调用。
- HttpServletRequest/HttpServletResponse接口的大部分方法我们仍未实现
- 架构/包结构和tomcat相差太多
- 其他未实现的功能
PS:本章源码已上传github: SimpleTomcat
