

阅读这篇文章的必要性:
无论是作为行业内的从业者还是一个组织,在开始深度学习应用之前,都需要掌握两件事:
1. 知其然:掌握一个基础概念,知道深度学习的最新发展可以实现什么。
2. 知其所以然:训练一个新模型或在生产环境下运行一个已有模型的技术能力
得益于开源社区的优势,我们获得“知其所以然”能力的途径越来越多。网上有大量优质的教程,讲解如何训练、使用深度学习模型的技术细节,例如借助TensorFlow这样的开源软件库来实现。TensorFlow中的许多数据科学资讯每周都在更新相关信息。
这意味着,当你有了“如何使用深度学习”的初步想法,实施这一计划绝非易事,通常都伴随着标准的“开发”工作:
让你跟随下文提到的链接教程学习,修改模型以实现具体目的,或为特定的数据服务、阅读StackOverflow帖子来排查问题,诸如此类的指南。这类工作并不要求你,例如,雇佣一位拥有博士学位的“顶尖人才”,他可以从头开始编写原始的神经网络架构,而且是一名经验丰富的软件工程师。
这一系列的文章旨在填补第一部分能力的空缺。一方面,此文宏观地覆盖了基础概念,讲述深度学习能胜任哪些事;同时,为那些希望更全面、深入地学习并理解代码从而掌握第二部分的读者们提供资源。
我会在下文展开更详细的描述:
1. 基于开源框架、数据集的深度学习,其最新成就有哪些?
2. 促进以上成就的关键框架或其他洞察力是什么?.
3. 可以从哪些优质资源入手,将相似的技术应用在自己的项目上?
这些重大突破有何共同点?
尽管这些突破涉及到很多新的框架和理念,却都是通过机器学习领域很常规的"监督式学习"过程实现的。
具体执行步骤如下:
1. 收集大量的、合适的训练数据
2. 设立一个神经网络架构——由算式组成的复杂系统、在脑中简单的建立一个模型-其中有数百万参数被称作"权重"
3. 通过神经网络反复地输入数据;在每次迭代中,对神经网络的预测结果与正确结果进行对比,然后基于对比结果的偏差量、方向,调整神经网络的每一项权重。
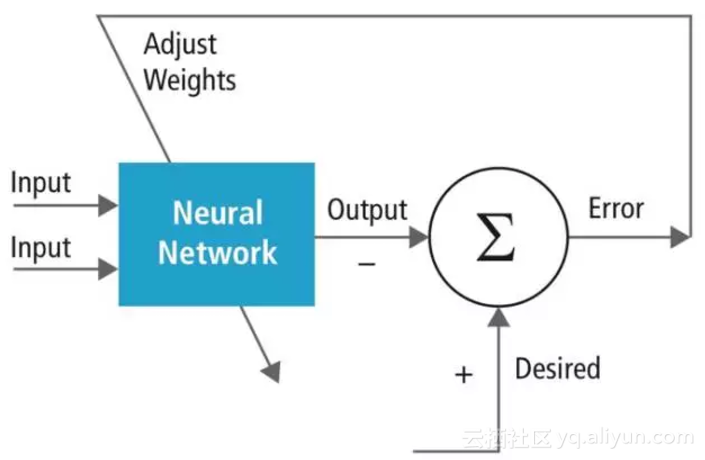
上图展示了神经网络的训练过程:这一流程被反复执行无数次。
(更多信息:https://www.embedded-vision.com/platinum-members/cadence/embedded-vision-training/documents/pages/neuralnetworksimagerecognition)
这一过程被应用于许多不同领域,最后我们得到的是已经有所习得的神经网络。
在每一领域,我们将涵盖以下部分内容:
1. 训练模型所需的数据
2. 所使用的模型框架
3. 运行结果
一. 图片归类
神经网络可被训练于识别一张图片上所包含的一个或多个物体。
所需的数据
要训练一个图像分类器,你需要有标签分类的图片集,其中每一张图片归属于一系列限定类当中的一个。举个例子,CIFAR 10数据是一种用于训练图像分类器的标准化的数据集
(传送门:https://www.cs.toronto.edu/~kriz/cifar.html)
它将图片数据划分为10类:如下图,从左至右-左侧为类名,右侧一行显示该类下的图片元素,从上至下-飞机、汽车、鸟、猫、鹿、青蛙、马、船、卡车这十大类。

关于CIFAR-10 数据中的图片的解释
(更多信息:https://becominghuman.ai/training-mxnet-part-2-cifar-10-c7b0b729c33c%27)
深度学习框架
我们将覆盖到的所有神经网络框架都是受"人们是如何学习解决问题"这一想法而驱动的。那么对于图片识别是怎么做的呢?当人类判断一幅图片里有什么的时候,我们首先寻找概要层次的一些特征,例如说分支啊,鼻子,或者轮椅。然而,为了更好的观察这些概要特性,你不得不关注底层的详细特征,比如颜色、线条、其它的形状。实际上,从原始像素一步步关注到更复杂的人类可辨识的特性,比方说眼睛,我们需要先察觉像素的特征,随后去看这些细分特征本身的特性,等等。
在深度学习之前,研究人员会手动尝试去提取这些特性,并用于预测分析。在深度学习刚开始出现不久前,研究者们开始使用一些技术手段(主要是SVMs)
(传送门:https://crypto.stanford.edu/~pgolle/papers/dogcat.pdf)
比方说,试图寻找这些手工筛选出的特征值与"这张图片上到底是一只猫还是狗"这两者之间的复杂的、非线性关系。

卷积神经网络在每一层抽取特征值
(更多信息:https://www.strong.io/blog/deep-neural-networks-go-to-the-movies)
目前,研究人员已经开发出了能够自主学习原始像素特征值的神经网络框架;具体来说,也就是深度卷积神经网络框架。这些网络能够抽取像素的特征,然后识别像素特征的附属特征,诸如此类,最终通过一层常规神经网络层(类似于逻辑回归),来进行最后的预测。

关于一个主流卷积神经网络预测的样本,分析对象是ImageNet数据集的图片
放心~我们会在未来的一篇文章中深入探讨关于卷积神经网络是如何用于图片分类的。现在继续来看刚才的话题。
成果
作为结果,在分配给这些框架的中心任务-图片分类,算法现在可以输出优于人工的结果了。在著名的ImageNet数据集中(最常被作为卷积神经网络框架的标杆),
(传送门:http://www.image-net.org/challenges/LSVRC/)
在图片分类这一任务上,经过训练的神经网络现在可以取得"优先于人类"的表现:
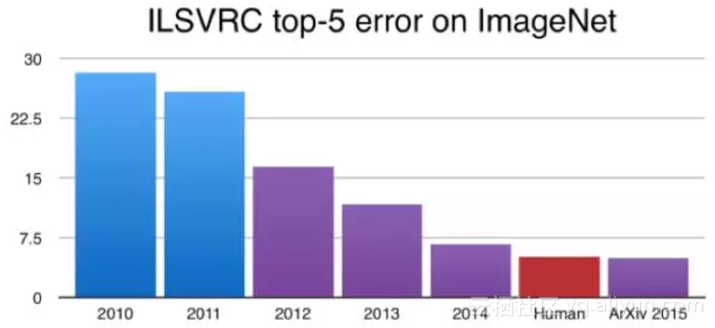
2015年,计算机可以被训练对图片中的目标物体进行分类, 并取得了比人类更好的表现
(更多信息:https://devblogs.nvidia.com/parallelforall/mocha-jl-deep-learning-julia/)
此外,研究人员找到了方法,将那些不能立即适用于当前图片类的图片定位,用一个矩形分隔出来,这一图片极有可能代表着某些特定类的目标物,通过卷积神经网络(CNN)来补给每一个矩形中的图片类数据,最后呈现的结果是每一张图片中的物体根据其所属的类的不同,被包围在一个个独立的矩形框里(这被称为"限位框")。

使用“Mark R-CNN”进行目标检测
(更多信息:https://arxiv.org/pdf/1703.06870.pdf)
这一整个多步骤的流程在技术上称作"目标检测",尽管它在最有挑战性的一步中使用了图像分类。
资源
理论:关于CNN为什么奏效的深入阅读,请移步Andrej Karpathy的斯坦福系列教程(传送门:http://cs231n.github.io/convolutional-networks/)。
如果要了解一个更偏重数理模型的版本,请在这查阅Chris Olah的卷积系列文章。
(传送门:http://cs231n.github.io/convolutional-networks/)
代码:准备开始构建一个图片分类器,请查看这个来自于TensorFlow文档的介绍性的例子
(传送门:https://www.tensorflow.org/tutorials/layers)
二. 文本生成
神经网络可以被训练以生成文本-模拟生成与给定类型相似的文本。
所需数据
直接输入某一特定类的文本,比方说,莎士比亚的所有作品。
深度学习框架
神经网络可以在一个系列的元素里去推断下一个元素是什么。它能参考之前输入的字符的顺序,根据给定的一串已经输出来的字符,来预测哪一个字符会在下一个出现。
用于该问题的这个框架与适用于图片分类器的框架是有差异的。由于框架不同,我们所要求网络学习的事情也不同。以前,我们是在要求它学习一张图片当中有哪些特征是重要特征。在这,我们则期望它注意到字符顺序,来预测未来字符出现的顺序。为了做到这一点,不像是图片分类器,这网络需要一种方式来记录它的"状态"。比方说,它看到的前一串字符是 “c-h-a-r-a-c-t-e”,这个网络应该有能力存储这一瞬时信息,预测到下一个字符应该是r。
一个循环神经网络框架(RNN)可以实现如下操作:在迭代过程中,它将每一个神经元的状态反馈回去神经网络给到下一次迭代作为输入,从而帮助该神经网络学习识别对象的排序顺序。
其实远不止这些内容,我们稍后再回到这个话题:)
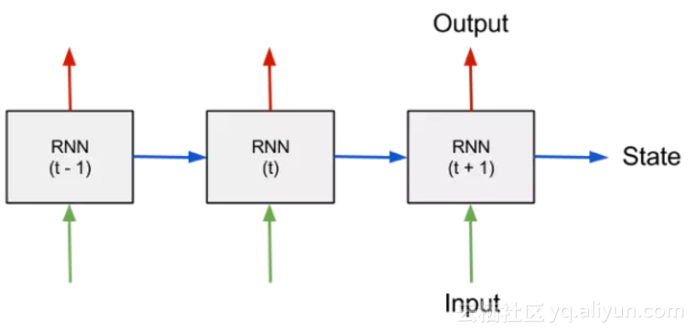
循环神经网络(RNN)架构图
(更多信息:https://medium.com/@erikhallstrm/hello-world-rnn-83cd7105b767)
但是,为了真正做好文本生成,除了具备上述能力外,RNN还必须能够决定在序列中向后反馈的长度。有时候,比如在单词中部,RNN只需查看最新几个的字母就可以确定下一个字母,而其他时候可能需要查看多个字母来确定,比如在句子末尾。
有一种特殊的单元类型,“LSTM”(长期短期记忆)单元,这一点上做得特别好。每个单元根据单元内的权重来决定是 “记住”还是“忘记”,权重根据RNN看到的每个新字母随时更新。
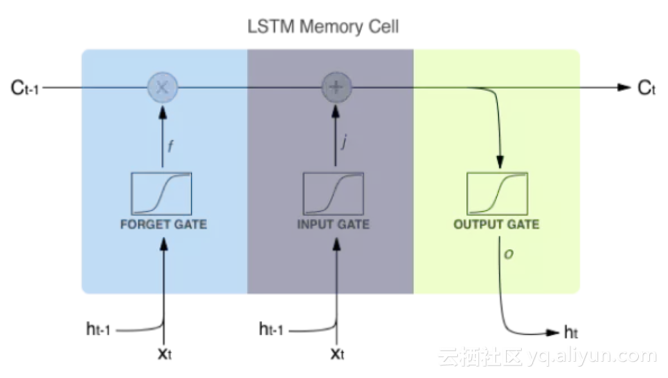
LSTM单元内部工作原理
(更多信息:https://medium.com/@erikhallstrm/hello-world-rnn-83cd7105b767)
成果
简而言之:我们可以生成文本,它有我们希望得到的文本所有的特质,同时减少拼写错误的单词、避免不像正常英语的错误。Andrej Karpathy的这篇文章提供了一些有趣的例子,从生成莎士比亚戏剧到Paul Graham散文。
(传送门:http://karpathy.github.io/2015/05/21/rnn-effectiveness/)
用同样的网络架构,通过顺序地生成x和y坐标,得到手写体,正如通过一个个字母生成语句一样。请查看这个演示。
(传送门:https://www.cs.toronto.edu/~graves/handwriting.cgi)

(更多信息:https://www.cs.toronto.edu/~graves/handwriting.cgi?text=Handwriting&style=&bias=0.15&samples=3)
神经网络的生成的手写字迹。可以称之为 “手”写吗?
我们会在后续文章中进一步讨论RNN和LSTMs的工作原理。
资源
理论:Chris Olah关于LSTMs的文章是经典,(传送门:http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
Andrej Karpathy关于RNN的文章也是经典,(传送门:http://karpathy.github.io/2015/05/21/rnn-effectiveness/)讲解了它们可以实现什么,它们是如何工作的。
代码:这是一个很好的演练,教你如何建立端到端的文本生成模型,包括数据预处理。然后这个GitHub repo是用预训练的RNN-LSTM模型生成手写体。
三.语言翻译
机器翻译 ——翻译语言的能力——是AI研究人员长久以来的梦想。深度学习使这一梦想更接近现实。
所需数据
不同语言同一意思的语句对。例如,“I am a student”和“je suis étudiant”可能出现在一个用于训练英语法语互译的神经网络的数据库里。
深度学习架构
与建立其他深度学习架构一样,研究人员先“假设”计算机可能的理想地学习翻译语言的过程,建立了一个模仿这一过程的架构。通过语言翻译,基本上,一个句子(编码成单词序列)应该被翻译成其本质上的“含义”。这个含义再被翻译成另一种语言的单词序列。
句子从单词“转化”成含义的过程应该是一个擅长处理序列的架构——就是上述的“循环神经网络”架构。

编码-解码架构图解
(更多信息:https://github.com/tensorflow/nmt/tree/tf-1.2)
2014年首次发现这一架构在语言翻译上效果不错,此后扩展到很多方向。
成果
这篇Google博客文章显示,这一架构圆满完成了它所要完成的任务,把其他语言翻译技术甩在后面。当然,也因为Google投入了大量的训练数据来完成这项任务!
(传送门:https://research.googleblog.com/2016/09/a-neural-network-for-machine.html)

Google序列到序列模型的表现
(更多信息:https://research.googleblog.com/2016/09/a-neural-network-for-machine.html)
资源
代码和理论:
Google发表了一个关于序列到序列架构的极好的教程。这一教程给出了序列到序列模型的目标和理论知识概述,还指导TensorFlow中的代码实现。教程还涉及“关注”,基本序列到序列架构的扩展,我会在详细讨论序列到序列模型时涉及它。
(传送门:https://github.com/tensorflow/nmt/tree/tf-1.2)
四.生成对抗网络
所需数据
特定类型的图像——比如,大量脸部的图像。
深度学习架构
GANs是一个惊喜而重要的成果——Yann LeCun。
全世界领先的AI研究者之一,说过“在我看来,GANs是过去十年机器学习领域最有趣的想法。”事实证明,我们可以生成看起来像一组训练图像,但实际上并不是这组训练集的图像:比如,看起来像脸部,但实际上不是真实脸部的图像。这是通过同时训练两个神经网络来完成的:一个产生看起来真实的虚假图像,一个检测这些图像是真是假。如果你训练这两个网络“以相同的速度”学习——这是构建GAN的难点 ——生成假图像的网络事实上能够生成看起来相当真实的图像。
说一点细节:我们想用GANs训练的主要网络称为生成器:学习接收一个随机噪声向量,并将其转换成逼真的图像。这个网络有来自卷积神经网络的“逆”结构,因此被贴切地称为“去卷积”架构。另一个鉴别真实和伪造图像的网络是卷积网络,就像用于图像分类的卷积网络一样,被称为“鉴别器”。
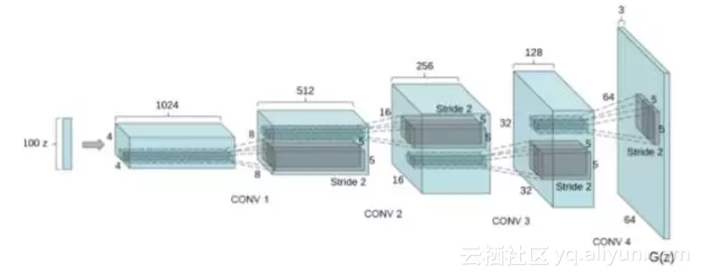
“生成器”的去卷积架构
(更多信息:https://medium.com/@awjuliani/generative-adversarial-networks-explained-with-a-classic-spongebob-squarepants-episode-54deab2fce39)
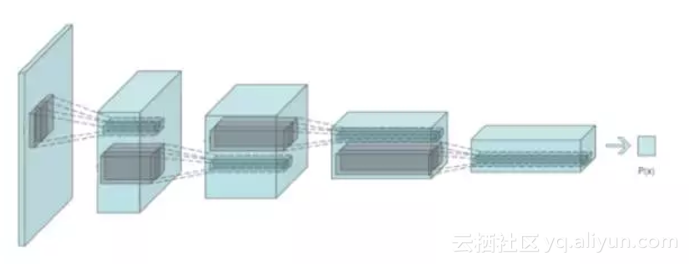
“鉴别器”的卷积架构
(更多信息:https://medium.com/@awjuliani/generative-adversarial-networks-explained-with-a-classic-spongebob-squarepants-episode-54deab2fce39)
GANs的两个神经网络都是卷积神经网络,因此这两个神经网络都特别擅长图像特征提取。
成果和资源

GAN基于名人脸部数据库生成的照片
(更多信息:https://medium.com/@awjuliani/generative-adversarial-networks-explained-with-a-classic-spongebob-squarepants-episode-54deab2fce39)
代码:这个GitHub repo是一个用TensorFlow训练GANs的好教程,还包含一些由GANs生成的惊人图像,比如上面的那个。
(传送门:https://github.com/carpedm20/DCGAN-tensorflow)
理论:Irmak Sirer的这个演讲是一个有趣的对GANs的介绍,同时涉及许多监督学习的概念,会帮助你理解上文的发现。
(传送门:https://github.com/carpedm20/DCGAN-tensorflow)
最后,优秀的Arthur Juliani还有一个有趣的,形象的GANs的详解,还有用TensorFlow实现的代码。
(传送门:https://medium.com/@awjuliani)
总结
本文对深度学习在过去五年取得的巨大突破做了高度总结。以上我们讨论的所有模型都有很多开源实例。这意味着你基本都能下载“预训练”模型,应用于你的数据——比如,你可以下载预训练图像分类器,给它输入自己的数据,用来对新图像分类,或是圈出图像中的物体。因为大部分的工作已经为你做好了,所以使用这项尖端科技的工作并不是“研究深度学习”本身——研究员们已经为你解决了绝大部分——而是做“发展”工作,让其他人建立的模型更好地用于你的问题。
希望你现在对深度学习模型的功能有了更深入的了解,离真正使用它们又更近了一步!
原文发布时间为:2017-12-21
本文作者:文摘菌
