

我的要求不高,只是一个变量而已
故事从一个变量讲起。比如初学编程的时候,我们都是从这样的代码学起的。
a = 1
print(a+1)
这能有多难?变量就是一个原子的容器,里面“之前”放了什么,“之后”取出来就是什么。映射到内存上就是一个内存地址而已。
但是这其实是很难的事情。我们这些被惯坏了程序员是无法理解的。比如,你有这样的SQL
UPDATE order SET order_status="arrived" WHERE order_id=10234
执行完了之后,订单状态应该就是arrived了的。
SELECT order_status FROM order WHERE order_id=10234
如果没有其他的写入操作。之后执行SELECT语句,取出来的订单状态就应该是arrived。当底层的数据库不是这样的行为的时候,我们会愤怒,我们会抓狂。比如我下一个接口取到的订单的时候会“校验”一下这个订单的当前状态是不是对的。读不到之前写入的订单状态,这个校验就过不去。
另外一个对变量的理所当然的假设是,它应该支持我去做带前提条件的更新。比如
if (amount >= 4) {
amount = amount - 4
return SUCCESS
} else {
return FAILED
}
这个例子,我是要给账户余额扣掉4块钱。如果能够保证扣完了之后账户的余额不为负数,也就是当前余额不小于4块,就扣掉。如果不能保证,就返回失败。这是一个理所当然应该支持的所谓compare and swap操作嘛,也就是read modify write的操作嘛。
对应成 SQL,我们的期望其实非常低。也不要求什么多行记录的事务。要求仅仅是操作一行的时候,这个操作能是原子的。比如这样的SQL
UPDATE account SET amount = amount - 4 WHERE amount >= 4
对数据库有这样的要求高么?一点都不高对不对。这个事情难不难?非常难!但是如果底层的数据不能提供这样的基本保障,我们这些写业务代码的程序员会愤怒,会抓狂。
抽象一下问题
剥离掉具体的业务需求。我们来看本质。第一个需求是要求写入和读取要能按照墙上时间进行排序。所有在读取之前发生的(happens before)写入都要能够在之后被读取到。这个是对读操作的线性一致性的保证。
第二个需求是要求之前的写入在CAS操作的时候都可见,而且要求写入的时候要保证这个时候变量的值仍然是读取到的那个。这个对写操作的线性一致性的保证。
总结来说,前面我们给数据库提的需求就是,我们需要的是linearizable的需求。这个需求过分不过分。参见:Strong consistency models
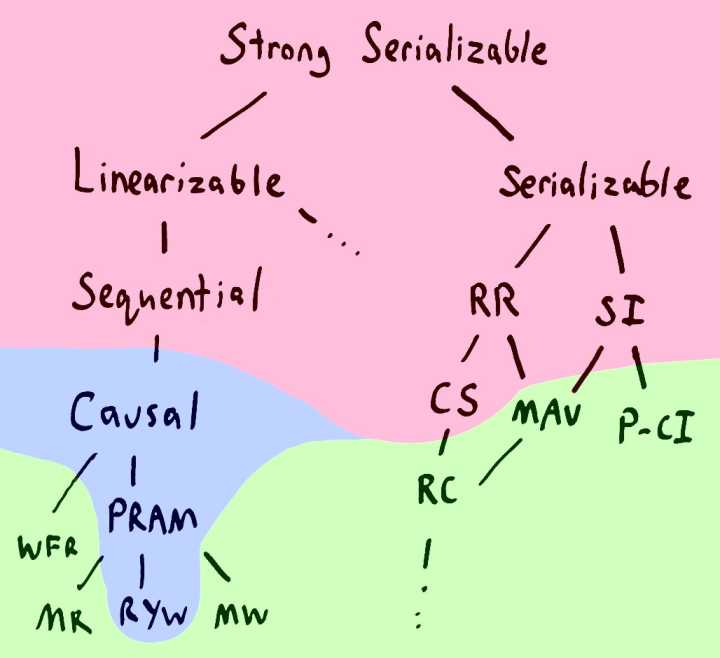
这个图的右边,是讲多个变量的问题的,左边是单变量的问题。Linearizable的读写,是我们能给一个“变量”提的最高级别的一致性要求了。你说过分不过分。
我读书少,你不要骗我
Wait a minute。做为一个变量这么一点基本的操守都没有么。比如我做为一个 Java 程序员都知道
volatile int a;
a = 1; // thread 1
System.out.println(a+1); // thread 2
什么Linearizability,名词一套套的。把我都说蒙圈了。你们这些基础架构的高T们,是不是就会写PPT啊。
这难道不是java面试题么。通过设置 volatile,可以保证在 thread 1 写入了 a,在这个时间之后,从任意其他线程去读 a 都可以读到之前写入的值。
而且这个volatile也不是什么复杂的东西嘛。据说就是把volatile变量的写入之后加了一条sfence的汇编指令。在读取之前加了mfence的汇编指令(参见:mechanical-sympathy.blogspot.com/2011/07/mem…)。有什么难的嘛,两条CPU指令而已。
至于 CAS,不就是 java.util.concurrent.atomics.AtomicInteger.compareAndSet 么。所有的条件写入都可以化简为调用这个函数啊。
据说底层调用的是 lock cmpxchg 这条汇编指令。有什么难的嘛,一条CPU指令而已。
但是……CPU指令又是如何实现 sfence,mfence 和 lock cmpxchg 的呢?
Welcome to the rabbit hole
带着这个疑问,我google了半天。找到了两篇讲得比较清楚的介绍:
- Memory Barriers: a Hardware View for Software Hackers(下载:www.rdrop.com/~paulmck/sc…)
- Computer Science Handbook, 2nd Ed 第19章,Bus
Holy shit。我们做业务逻辑开发的程序员真是太naive了。a = 1,然后 print(a+1) 真的不是那么容易实现的事情。
首先来看一段最简单的业务逻辑代码
doX() {
a = 1
a = a + 1
b = 2
b = b + 1
}
很简单吧。这个就是没有任何分支和循环的最简单的串行逻辑。我们称这样的串行的业务逻辑为非concurrent的。
但是业务逻辑落到具体的机制上进行执行,这个执行的过程未必就是“串行”的。也可能是parallel的。也就是 "not concurrent" != "not parallel"。
为什么?因为CPU的日子也不好过啊。你这要求它做1做2做3做4的,还要求人家特别快,确实很难。CPU找到的讨巧的办法是把 not concurrent 的业务逻辑,parallel 的执行。怎么做?
a = 1
a = a + 1
这一串,和下面的
b = 2
b = b + 1
貌似没有什么联系嘛。一个CPU核内部有多个可以parallel运算的单元。那么就独立去算好了。这个就是所谓的CPU乱序执行。
另外再来看一段代码
a = 0
doX() {
if (a == 0) {
a = a + 1
}
}
doY() {
if (a == 0) {
a = a + 2;
}
}
这段代码是concurrent的,因为doX和doY是两个独立的运算流程,或者叫两段独立的业务逻辑。但是 "concurrent" != "parallel"。(参见 blog.golang.org/concurrency…)concurrency是业务逻辑上的并行。但是具体到实际的执行过程,未必是并行的。比如这样的一个执行顺序
a = 0
doX() {
if (a == 0) { // 第一步
a = a + 1 // 第三步
}
}
doY() {
if (a == 0) { // 第二步
a = a + 2; // 第四步
}
}
按照上面的这样一个执行顺序,即便只有一个CPU核,也可以“同时”执行两段业务逻辑。但是第一步执行完doX的第一行之后,为什么能够跳到doY这个函数里去呢。难道一个函数不是“独占”一个cpu核的么?
独占cpu核,用parallel去实现concurrent是一种执行方案,但不是唯一的执行方案。编程语言完全可以再doX的第一行执行完之后把状态保存起来,然后切换到doY执行,然后再切换回来,直接跳到doX的第二行去继续执行。也就是所谓的“协程”。
按照刚才的执行顺序,虽然只有一个CPU核在用非parallel的方式去运算。但是语义上是同时concurrent地跑着两段业务逻辑。这种concurrency就引起了concurrent object的问题。因为a的状态同时被doX和doY进行了读写。按照给定的执行顺序,计算出来的结果是3,既不是1也不是2。也就是所谓的代码出了并发的bug。
concurrent object 问题不是多核 cpu“搞出来的问题”。根本上是有两段独立的业务逻辑共享了状态引起的。concurrent object 问题本质上是业务逻辑是否完备的问题。即便是单核cpu串行去执行,只要有协程存在,就仍然会有出bug的可能。对于 concurrent object,安全写入的办法就是做 CAS。所有写入带上一个前提条件,而不是无条件的write。因为concurrency是由多段独立的业务逻辑引起的,CAS是做为协调手段,本身也是业务逻辑。不用CAS,只有在写入方只有一个的时候,才是安全的。
对于存粹的 parallelism,比如CPU乱序执行。Intel x86 的 CPU是非常负责任的。基本上你可以认为你的一段串行的业务逻辑,真的就是一行接着一行执行的。大部分情况下做为写业务代码的同学,完全不用在意CPU背后搞的这些小动作。但是 arm 之类的 CPU 就没有那么负责任,会因为追求parallel执行,破坏掉单个变量的 linearizability 和多个变量的 serializability。
Concurrent Object 的线性一致性读
既然CPU可以聪明到用乱序执行,自作主张的引入parallelism。然后还可以保证乱序执行不会引起内存可见性方面的问题。既然已经这么牛b了,为什么不“顺手”把多核执行concurrent的业务逻辑,这种parallelism引起的内存可见性问题也解决了?让所有的变量都能够线性一致性读呢?
a = 0
doX() {
a = 1;
}
doY() {
print(a);
}
对于doX和doY这两个concurrent的执行流程,只要保证doX“真的”把1写入到了a的内存地址,doY的时候“真的”从a的内存地址去读取了值。“线性一致的读取”不就实现了么?
sfence 和 mfence 干的事情就是这个。但是为什么不把所有的内存读写都加上 sfence 和 mfence?
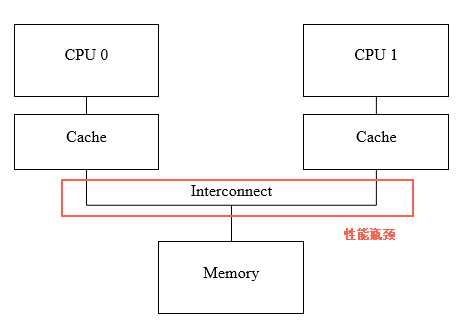
原因很简单。因为多个CPU核去读写内存的时候,共享的总线是很慢的。如果所有的写入都要立即回写到内存里,所有的读取都要真的从内存里走总线调上来,这个速度是很慢的。所以每个CPU核都引入了自己的本地缓存来加速内存的读写。
假设每个cpu都有自己的缓存了。那么我们如何保证读操作的线性一致性?就是一个变量被更新了之后,所有其他的cpu再去读这个变量都要读到新的值。最简单的实现就是要求更新操作去刷新所有其他CPU的缓存。等所有的CPU缓存都刷新完了之后,才结束这次写操作。开始执行下一条指令。
按照使用数据库的经验,这个实现问题很大啊:
- 可用性:所有的CPU都写入成功。要是有一个CPU挂了,不是就写不成功了么。
- 延迟:等所有的CPU更新完自己的缓存。这写一个变量该多慢啊。sfence的代价也太高了吧。
好在是CPU,而不是数据库。可用性不是问题。一个CPU挂了,整台机器就异常了是可以接受的。延迟是真正的大问题。如果sfence的延迟这么高,可能把所有的并发节省下来的时间都浪费掉了。
要降低这个写操作的延迟,需要知道延迟产生在哪里:
- 本地cpu cache的争抢:cache太忙了,导致来不及更新,需要等cache
- 其他cpu cache的争抢:别的cpu的cache太忙了,不能立即更新,需要等待
就像一个餐馆生意太好了,需要叫号是一样的。

CPU的设计者是怎么解决cache太忙了,不能及时更新的问题的呢?排队吧
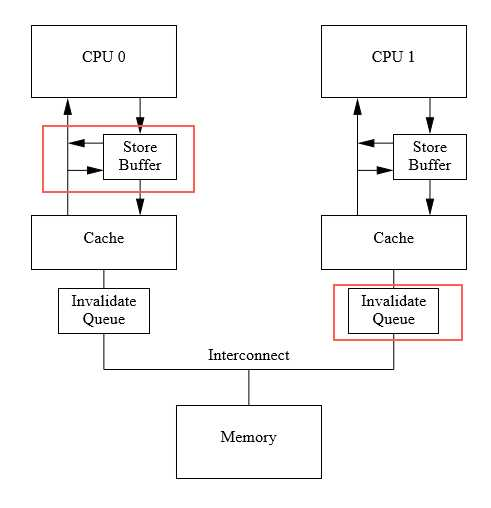
CPU0发起的一个写入。需要排两个队,一个是在本地的store buffer里,一个是在其他cpu的invalidate queue里。排队的好处是不需要等cache真的更新了。只要排上了,就可以认为已经写入了。读取的时候,cpu会去查这个队列,以及cache本身,综合决定值是什么。也就是把成本部分分摊到了读取的时候去做。
表面上 a =1,print(a+1) 这样的简单内存地址的写入的读取,其实在多核cpu层面是用消息传递,所有参与者遵守同样的MESI协议(和你的http handler其实没啥区别,就是一个响应消息的业务逻辑代码),来保证内存的一致性。你可以理解为多核CPU之间架了一个RPC网络,给你提供了一个内存地址可以线性读取的抽象。
Concurrent Object 的线性一致性写
sfence和mfence听起来也不是那么糟糕。就是拿缓存做了点同步的工作而已嘛。lock cmpxchg指令又是如何工作的呢?CAS做为线性一致写入的基石,这个是如何实现的?
根据 Computer Science Handbook, 2nd Ed 第19章,Bus。这个过程其实是这样的。
最简单的实现办法是把lock cmpxchg做为一个原子来执行。因为system bus保证了只有一个cpu核可以同时拿到执行权。cpu核可以把整个system bus锁上,然后执行lock cmpxchg,然后再解锁。可以说就是用一个非常大粒度的悲观锁来实现的。但是这样会造成system bus长时间无法服务于其他的任务。
既然锁粒度太大,那么就把锁的粒度搞小一点。把CAS操作分解为 read & lock,以及 write & unlock 两个步骤来执行。在system bus上实现address 级别的细粒度的悲观锁。
按顺序来说,就需要这么几个消息往来
- 对 system bus进行 address lock
- 对每个其他cpu进行invalidate,等ack,得到最新的值
- 比对是否等于预期的值,如果符合预期,则做更新
- 做写入操作,同时写入到所有cpu的cache,等ack
- 对system bus进行 address unlock
所以有意思的地方是linux操作系统提供的悲观锁,实际上底层是由乐观锁实现的(CAS保护的processor当前排在runqueue里的线程)。而CPU的乐观锁,最终还是由system bus的address级别的锁实现的。
基于这样的实现,多核CPU就提供了线性一致的写操作的能力。
扩展到分布式的 Concurrent Object
通过前面的 going down rabbit hole的过程,我们了解了在单机多核非持久化的情况下,实现线性一致的读取(sfence/mfence),核线性一致的写入(CAS),是非常不容易的。
那么把问题扩展到分布式场景下。如果有一个变量,可以多机并发的读写,要保证线性一致的读写就更困难了。最简单的一个想法,直接把多核CPU的那一套拿过来不就行了么?有几个问题:
- 可用性:要求全体都在线,导致总体的可用性是个体的可用性的乘积
- 延迟:延迟取决于最慢的那一次复制交互。
- 持久化:CPU的内存一致性模式不用考虑内存挂了,再恢复的问题。而分布式存储的要求是不把鸡蛋放在一个篮子里。
- 没有System Bus:CAS指令最终是依赖总线实现的Address Lock的。分布式系统下没有这样一个共享的硬件来做这个事情。
前三点都好说。无非就是把CPU的内存一致性算法里的要求所有的CPU都Ack,改成要求多数派应答就可以了。无论是延迟,还是可用性,还是持久化通过拷贝多份,都可以通过这个多数派来解决。而且CPU的内存一致性算法随着CPU核数的变多,也开始有了一些变化,比如:people.csail.mit.edu/yxy/pubs/ta… 。在核数越来越多的背景下,降低一致性引起的延迟也变成了有收益的事情。
Paxos和CPU一致性算法在实现线性一致性读的区别在于,CPU要求全体ack,而Paxos不要求。这个决定背后的隐藏约束是,CPU的环境下,高可用不是问题,而且读取的低延迟非常重要。而Paxos的环境下,需要对硬件故障进行容错,但是读取的延迟是可以放松(如果要求读到最新的版本,要读多个节点)。两者只是根据自己的硬件基础,做了一些取舍而已。
真正要命的挑战是第四点。没有共享的System Bus来实现Address Lock,这个CAS操做如何实现呢?没有CAS,压根就没有办法对Concurrent Object实现安全的写入(安全的好意是符合业务逻辑的意思)。回忆一下CPU的CAS的实现,它实际是拆分成两步来实现的:
- 先读出来当前是否是有值的,并且同时上锁
- 如果没有值,则写入值,同时释放锁
而号称唯一正确的分布式共识算法Paxos,恰好也是两步(这不是意外):
- Prepare & Promise:就是把值出来,同时上锁
- Propose & Accept:写入值
但是没有System Bus硬件实现的Address Lock,软件的共识算法如何保证Prepare和Accept中间没有人插入进行执行呢?
State is illusion, Log is reality
我发现最好的理解分布式共识算法的视角是建立一个正确的世界观。那就是,state is illusion,log is reality。
给你一个变量a。这个变量a只是一个抽象,所谓a有状态只是一个幻觉。a背后的变更日志才是事实。

这样的一个日志,有两个变更的记录。这个时候a的值就是2。
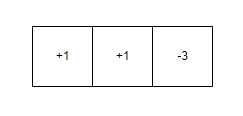
在2的基础上,再-3。那么a的值就变成了-1。
有了这样的一个日志,背后就相当于我们有了一个逻辑上的时间的概念。也就是log的每个entry的offset。

有了这样的一个世界观之后。那么就拥有了一个绝对的时间的概念。我们知道,a这个变量的状态就是从左往右,一个个apply新的变更得到的。offset越小,代表逻辑时间越小。offset越大代表逻辑时间越大。
回到我们的问题。CAS要实现的两个目标:
- Read & Lock:读到一个确定性,静止的历史。
- Write:在这个历史的基础上,写入我的值。这个写入要获得足够的节点的支持才算成功。
这个要求,落到日志的模型上。就是去争抢一个offset。比如
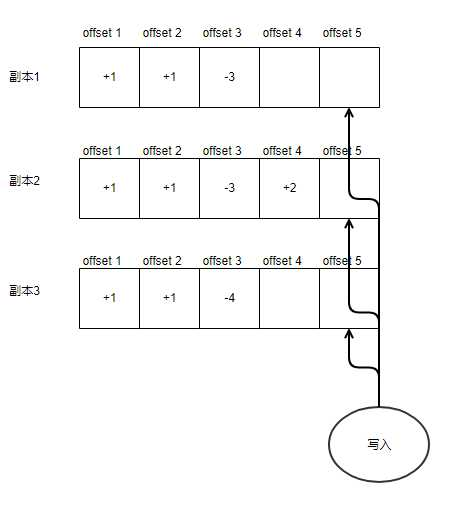
假设你要去写offset5。这个时候是没法写入的。因为副本1和副本3在offset4这个位置上还是空洞。也就是你的历史还是处在变化中的。在offset5这个位置的值,取决于这两个洞填上什么值。怎样才能让offset5获得一个静止的历史,从而拿到所谓的读锁(当你的历史都确定了,相当于上锁了):
- 等一段时间,等别的写入者把offset4都给写完
- 一直等下去也不是办法,我把offset4填上一个“作废”的标签吧。
当offset5之前的offset的所有副本的空洞都填上了。那么可以确保offset5可以放心的去读取历史,根据历史做判断,然后写入offset5这个位置的改动。
其实把“所有副本的空洞”都填上是一个过强的要求了。一个更形象的说法是”把offset5之前的offset的写入都给搅和黄”,让这些offset都写不成功就行。如何才能让这些offset写不成功?
- 每个副本的每个offset代表一个洞,这个位置只能写一次
- 假设总共10个副本,写入3个就算成功的话
- 那么把一个offset搅和黄,永远写不成功。就是要把8个副本的对应offset的洞填上作废。这样就永远不会有3个洞填上值了。3+8=11 大于10
所以一次安全的CAS写入过程是:
- 假设总共N份副本
- 要写入offset I,把I之前所有offset的位置 [0, I-1],填上R份的作废。确保过去的历史呈静止状。
- 读取过去的历史日志。判断当前的offset应该写什么值进去。
- 把当前offset I的值,写入W份副本,才算写入成功,返回给调用方。
- 要求 R + W > N
这个过程就是 corfu 的连续offset模型。而paxos的区别在于,proposal number(相当于这里的日志offset)不一定是连续的。所以paxos实现了一个更有效率的标记”作废“的过程。就是每个副本有一个当前最大offset的标记。小于这个标记的offset都做为”作废“来处理。
希望把 Paxos 讲清楚了。
总结
如果要求数据100%不丢。要实现线性一致性读取(SQL提交了,接下来用SQL查询就可以查到),要实现线性一致性写入(当行SQL既读又写),是非常困难和苛刻的要求的。因为要永远不lost update,数据库必须用multi-paxos或者raft,才能实现单行数据的线性一致性(且不说多行数据变更的ACID问题)。
但是如果不要求100%不丢,允许lost update,这个问题就变得非常容易了。只要把写入都发给一个master,让master异步复制日志就好了。一旦master挂掉,复制过程中的日志对应的写入就丢失了。
绝大多数业务都不要求数据100%不丢,单行数据,或者说单个变量的线性一致性读和写都是可以做到的,也不是很难。
