

书接上一篇ArrayList源码解析,这一节继续分析LinkedList在Java8中的实现,它同样实现了List接口,不过由名字就可以知道,内部实现是基于链表的,而且是双向链表,所以Linked List在执行像插入或者删除这样的操作,效率是极高的,相对地,在随机访问方面就弱了很多。 本文基于JDK1.8中LinkedList源码分析 ####类定义

public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
由上图以及类定义片段可知,LinkedList继承了AbstractSequentialList并且实现List,Deque,Cloneable, Serializable接口。
其中,AbstractSequentialList相较于AbstractList(ArrayList的父类),只支持次序访问,而不支持随机访问,因为它的
get(int index) ,set(int index, E element), add(int index, E element), remove(int index) 都是基于迭代器实现的。所以在LinkedList使用迭代器遍历更快,而ArrayList使用get (i)更快。
接口方面,LinkedList多继承了一个Deque接口,所以实现了双端队列的一系列方法。
####基本数据结构
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
LinkedList中主要定义了头节点指针,尾节点指针,以及size用于计数链表中节点个数。那么每一个Node的结构如何呢?
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element; //当前节点值
this.next = next; //后继节点
this.prev = prev;//前驱节点
}
}
可以看出,这是一个典型的双向链表的节点。

- getFirst获取头节点
- getLast获取尾节点
- get(int index) 获取指定位置的节点
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
检查非空后,直接返回first节点的item
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
检查非空后,直接返回last节点的item
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
首先检查index范围,然后调用node(index)获取index处的节点,返回该节点的item值。 看看node(index)的实现,后面很多地方借助于这个小函数:
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { //判断index是在链表偏左侧还是偏右侧
Node<E> x = first;
for (int i = 0; i < index; i++) //从左边往右next
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--) //从右往左prev
x = x.prev;
return x;
}
}
由上面可以看出,在链表中找一个位置,只能通过不断遍历。
另外还有IndexOf,LastIndexOf操作,找出指定元素在LinkedList中的位置: 也是一个从前找,一个从后找,只分析下IndexOf操作:
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
主要也是不断遍历,找到值相等的节点,返回它的Index。
####更改节点的值 主要也就是一个set函数
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
根据index找到指定节点,更改它的值,并且会返回原有值。
####插入节点 LinkedList实现了Deque接口,支持在链表头部和尾部插入元素:
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}
这里我们可以看到内部实现的函数是linkFirst,linkLast,
链表头插入元素:
private void linkFirst(E e) {
final Node<E> f = first; //现将原有的first节点保存在f中
final Node<E> newNode = new Node<>(null, e, f); //将新增节点包装成一个Node节点,同时该节点的next指向之前的first
first = newNode; //将新增的节点设成first
if (f == null)
last = newNode; //如果原来的first就是空,那么新增的newNode同时也是last节点
else
f.prev = newNode; //如果不是空,则原来的first节点的前置节点就是现在新增的节点
size++; //插入元素后,节点个数加1
modCount++; //还记得上一篇讲述的快速失败吗?这边依然是这个作用
}
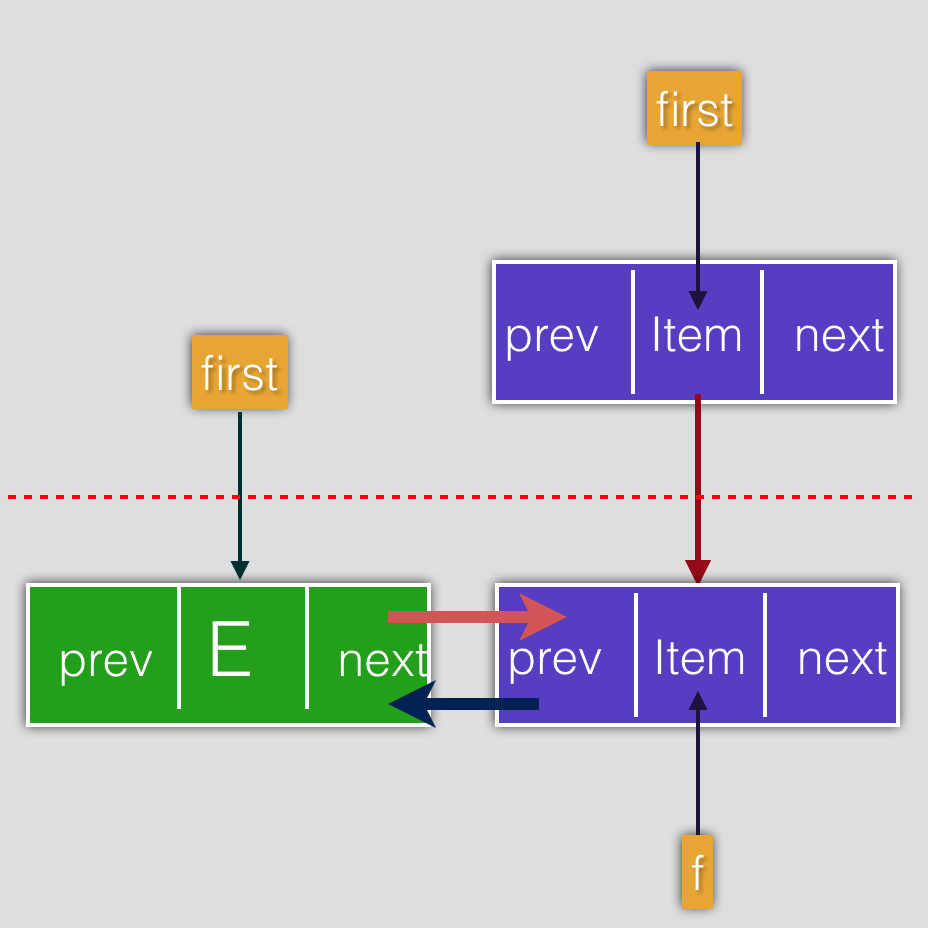
- 将原有头节点保存到f
- 将插入元素包装成新节点,并且该新节点的next指向原来的头节点,即f
- 如果原来的头节点f为空的话,那么新插的头节点也是last节点,否则,还要设置f的前置节点为NewNode,即NewNode现在是first节点了
- 记得增加size,记录修改次数modCount
链表尾插入元素
void linkLast(E e) {
final Node<E> l = last; //将尾节点保存到l中
final Node<E> newNode = new Node<>(l, e, null); //把e包装成Node节点,同时把该节点的前置节点设置为l
last = newNode; //把新插的节点设置为last节点
if (l == null)
first = newNode; //如果原来的last节点为空,那么新增的节点在意义上也是first节点
else
l.next = newNode; //否则的话还要将newNode设为原有last节点的后继节点,所以newNode现在是新的Last节点
size++;
modCount++;
}
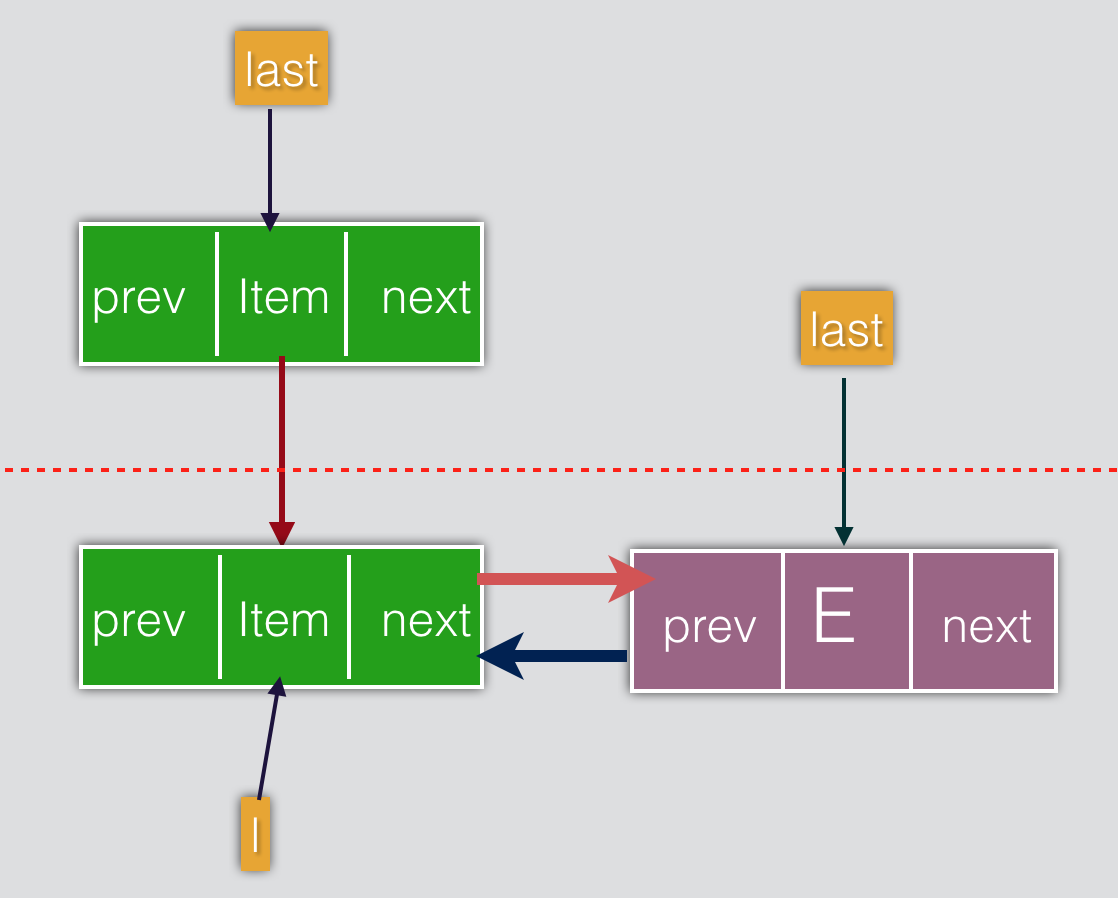
在指定index处插入元素
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
首先调用checkPositionIndex检查index值是否在范围内,如果index在最后的话,就调用在尾部插入的函数,否则调用LinkBefore,主要看LinkBefore如何实现的:
void linkBefore(E e, Node<E> succ) { //在succ节点前插入newNode
// assert succ != null;
final Node<E> pred = succ.prev; //将succ的前置节点记为pred
final Node<E> newNode = new Node<>(pred, e, succ); 以pred为前置节点,以succ为后继节点建立newNode
succ.prev = newNode; //将new Node设为succ的前置节点
if (pred == null)
first = newNode; //如果原有的succ的前置节点为空,那么新插入的newNode就是first节点
else
pred.next = newNode; // 否则,要把newNode设为原来pred节点的后置节点
size++;
modCount++;
}
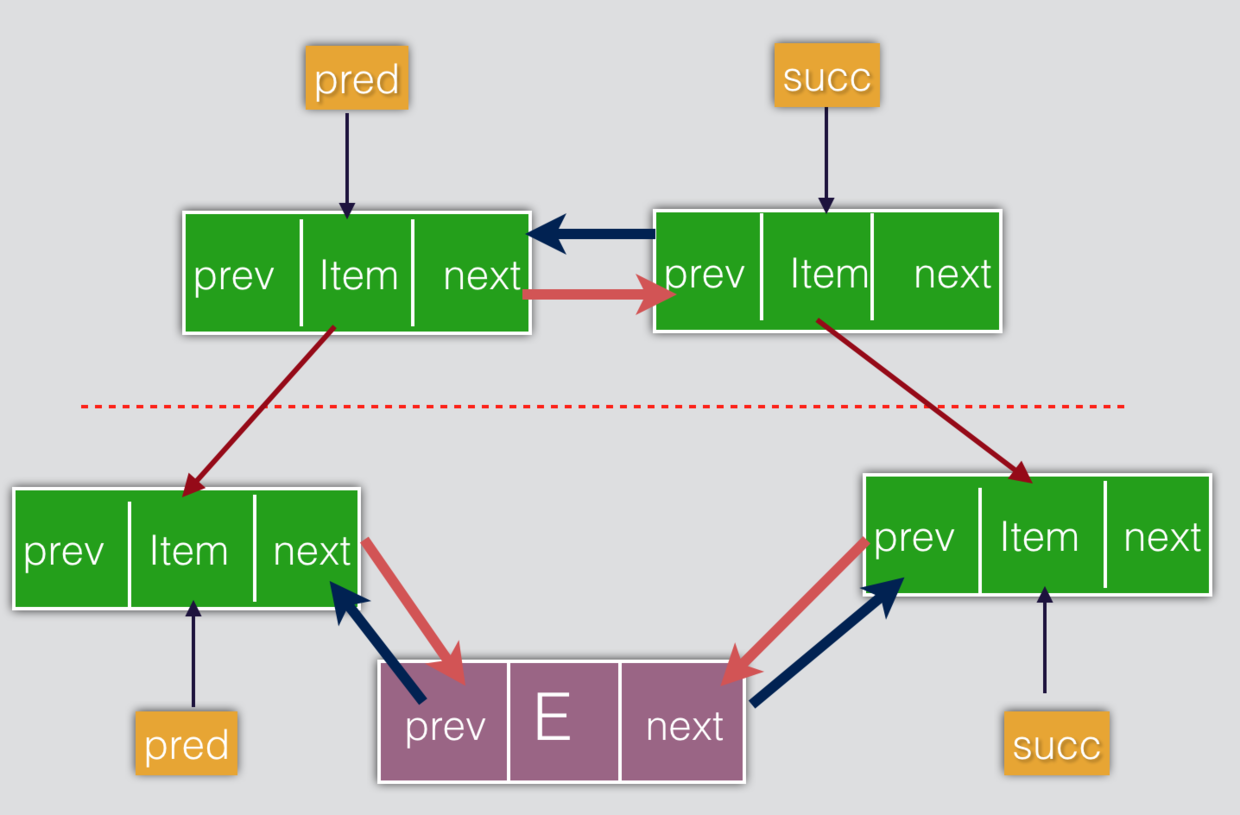
其余几个常用的add方法也是基于以上函数:
public boolean add(E e) {
linkLast(e);
return true;
}
add函数默认在函数尾部插入元素
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
addAll(Collection<? extends E> c)指的是在list尾部插入一个集合,具体实现又依赖于addAll(size,c),指的是在指定位置插入一个集合:
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index); // 检查index位置是否超出范围
Object[] a = c.toArray(); //将集合c转变成Object数组 同时计算数组长度
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) { //如果插入位置为尾部,succ则为null,原来链表的last设置为此刻的pred节点
succ = null;
pred = last;
} else {
succ = node(index); //否则,index所在节点设置为succ,succ的前置节点设为pred
pred = succ.prev;
}
for (Object o : a) { //循环遍历数组a
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null); //以a为element元素构造Node节点
if (pred == null)
first = newNode; //如果pred为空,此Node就为first节点
else
pred.next = newNode; //否则就往pred后插入该Node
pred = newNode; //newNode此刻成为新的pred, 这样不断循环遍历,把这个数组插入到链表中
}
if (succ == null) { //如果succ为空,就把插入的最后一个节点设为last
last = pred;
} else {
pred.next = succ; //否则,把之前保存的succ接到pred后面
succ.prev = pred; //并且把succ的前向指针指向插入的最后一个元素
}
size += numNew; //记录增长的尺寸
modCount++; //记录修改次数
return true;
}
具体流程可以看代码中的注释。
####删除节点####
因为实现了Deque的接口,所以还是实现了removeFirst, removeLast方法。
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
首先保存fisrt节点到f,如果为空,抛出NoSuchElementException异常,实际还是调用unlinkFirst完成操作。
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item; //把f.item的值保存到element
final Node<E> next = f.next; //把f.next的值记住
f.item = null;
f.next = null; // help GC //把item和next的都指向null
first = next; //next成为实际的first节点
if (next == null) //next为空的话,因为next是第一个节点,所以链表都是空的,last也为空
last = null;
else
next.prev = null; //next不为空,也要将它的前驱节点记为null,因为next是第一个节点
size--; //节点减少一个
modCount++; //操作次数加1
return element;
}
removeLast的实现基本和removeFirst对称:
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
主要实现还是借助于unlinkLast:
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item; //保存最后一个节点的值
final Node<E> prev = l.prev; //把最后一个节点的前驱节点记为prev,它将成为last节点
l.item = null;
l.prev = null; // help GC //l节点的item和prev都记为空
last = prev; //此时设置刚才记录的前驱节点为last
if (prev == null) //prev为空的话,说明要删除的l前面原来没节点,那么删了l,整个链表为空
first = null;
else
prev.next = null; //prev成为最后一个节点,没有后继节点
size--;
modCount++;
return element;
}
在指定index删除
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
首先也是检查index是否合法,否则抛出IndexOutOfBoundsException异常。
如果删除成功,返回删除的节点。
具体实现依赖于unlink,也就是unlink做实际的删除操作:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
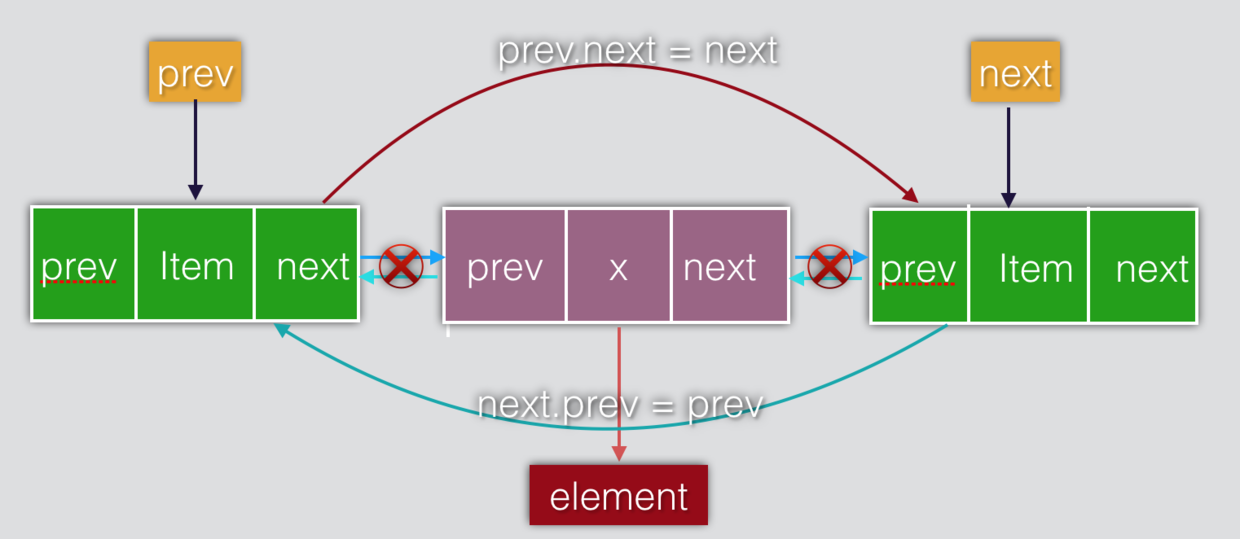
- 将删除的节点保存在element里,同时把要删除节点的前驱节点标记为prev,后继节点标记为next;
- 如果prev为空,那么next节点直接为first节点,反之把prev的next指向next节点,如图中上面弯曲的红色箭头所示;
- 如果next为空,那么prev节点直接为last节点,反之把next的prev指向prev节点,如图中下面弯曲的蓝色箭头所示;
- 把要删除的节点置空,返回第一步保存的element。
还有种删除是以删除的元素作为参数:
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
- o为null,也是遍历链表,找到第一个值为null的节点,删除;
- o部位空,遍历链表,找到第一个值相等的节点,调用unlink(x)删除。
####清空列表
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
由代码看出,也就是循环遍历整个链表,将每个节点的每个属性都置为空。
LinkedList还定义了很多别的方法,基本上和上面分析的几个函数功能类似
- elemet和GetFirst一样,都返回列表的头,并且不移除它,如果列表为空,都会抛出NoSucnElement异常;
- peek也会返回第一个元素,但是为空时返回null, 不抛异常;
- remove方法内部就是调用removeFirst,所以表现相同,返回移除的元素,如果列表为空,都会抛出NoSucnElement异常;
- poll也是移除第一个元素,只是会在列表为空时只返回null;
- offer和offerLast在尾部add节点, 最终调用的都是addLast方法,offerFirst在头保护add节点,调用的就是addFirst方法;
- peekFirst返回头节点,为空时返回null,peekLast返回尾节点,为空时返回null,都不会删除节点;
- pollFirst删除并返回头节点,为空时返回null ,pollLast删除并返回尾节点,为空时返回null;
- push和pop也是让LinkedList具有栈的功能,也只是调用了addFirst和removeFirst函数。
####ListIterator
最后重点说一下LinkedList中如何实现了ListIterator迭代器。
ListIterator是一个更加强大的Iterator迭代器的子类型,它只能用于各种List类的访问。尽管Iterator只能向前移动,但是ListIterator可以双向移动。它还可以产生相对于迭代器在列表中指向的当前位置的前一个和后一个元素的索引,可以用set()方法替换它访问过得最后一个元素。
定义如下:
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
指定index,可以在一开始就获取一个指向index位置元素的迭代器。 实际上LinkedList是实现了ListItr类:
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned;
private Node<E> next; //用于记录当前节点
private int nextIndex; //用于记录当前节点所在索引
private int expectedModCount = modCount;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index); //返回index处的节点,记录为next
nextIndex = index; //记录当前索引
}
public boolean hasNext() {
return nextIndex < size; //通过判断nextIndex是否还在size范围内
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next; //记录上一次的值
next = next.next; //往后移动一个节点
nextIndex++; //索引值也加1
return lastReturned.item; //next会返回上一次的值
}
public boolean hasPrevious() { //通过哦按段nextIndex是否还大于0,如果<=0,就证明没有前驱节点了
return nextIndex > 0;
}
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev; //往前移动
nextIndex--;
return lastReturned.item;
}
public int nextIndex() {
return nextIndex;
}
public int previousIndex() {
return nextIndex - 1;
}
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (modCount == expectedModCount && nextIndex < size) {
action.accept(next.item);
lastReturned = next;
next = next.next;
nextIndex++;
}
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
我们可以发现在ListIterator的操作中仍然有checkForComodification函数,而且在上面叙述的各种操作中还是会记录modCount,所以LinkedList也是会产生快速失败事件的。
