

世界最强围棋AI AlphaGo Zero带给世人的震撼并没有想象中那么久——不是因为大家都去看谁(没)跟谁吃饭了,而是DeepMind再次迅速超越了他们自己,超越了我们剩下所有人的想象。
其中,DeepMind团队描述了一个通用棋类AI“AlphaZero”,在不同棋类游戏中,战胜了所有对手,而这些对手都是各自领域的顶级AI:
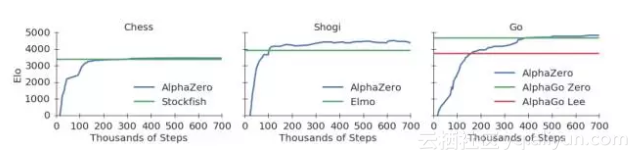
而AlphaGo Zero更是不必介绍,相信“阿法元”之名已经传遍中国大江南北。而AlphaZero在训练34小时后,也胜过了训练72小时的AlphaGo Zero。
看着AlphaZero赢,简直太不可思议了!这根本就不是计算机,这压根儿就是人啊!
我的神啊!它竟然只玩d4/c4。总体上来看,它似乎比我们训练的要少得多。
比AlphaGo Zero更强的AlphaZero来了!8小时解决一切棋类!
知乎用户PENG Bo迅速就发表了感慨,我们取得了他的授权,转载如下(知乎链接见文末):
这令人震惊,因为此前大家都认为Stockfish已趋于完美,它的代码中有无数人类精心构造的算法技巧。
然而,现在Stockfish就像一位武术大师,碰上了用枪的AlphaZero,被一枪毙命。
训练过程极其简单粗暴。超参数,网络架构都不需要调整。无脑上算力,就能解决一切问题。
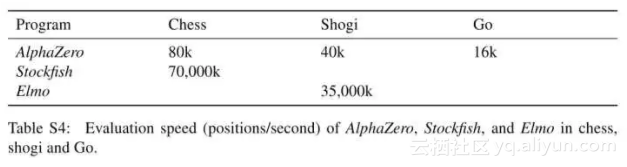
Stockfish和Elmo,每秒种需要搜索高达几千万个局面。
AlphaZero每秒种仅需搜索几万个局面,就将他们碾压。深度网络真是狂拽炫酷。
当然,训练AlphaZero所需的计算资源也是海量的。这次DeepMind直接说了,需要5000个TPU v1作为生成自对弈棋谱。
不过,随着硬件的发展,这样的计算资源会越来越普及。未来的AI会有多强大,确实值得思考。
个人一直认为,MCTS+深度网络是非常强的组合,因为MCTS可为深度网络补充逻辑性。我预测,这个组合未来会在更多场合显示威力,例如有可能真正实现自动写代码,自动数学证明。
为什么说编程和数学,因为这两个领域和下棋一样,都有明确的规则和目标,有可模拟的环境。(在此之前,深度学习的调参党和架构党估计会先被干掉...... 目前很多灌水论文,电脑以后自己都可以写出来。)

AlphaZero算法是AlphaGo Zero算法更通用的版本。它用深度神经网络和白板(tabula rasa)强化学习算法,替代传统游戏程序中所使用的手工编码知识和领域特定增强。
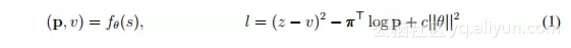
其中,c是控制L2权重正则化水平的参数。更新的参数将被用于之后的自我对弈当中。
AlphaZero算法与原始的AlphaGo Zero算法有以下几大不同:
1、AlphaGo Zero是在假设结果为赢/输二元的情况下,对获胜概率进行估计和优化。而AlphaZero会将平局或其他潜在结果也纳入考虑,对结果进行估计和优化。
奢华的计算资源:5000个第一代TPU,64个第二代TPU,碾压其他棋类AI
像AlphaGo Zero一样,棋盘状态仅由基于每个游戏的基本规则的空间平面编码。下棋的行动则是由空间平面或平面矢量编码,也是仅基于每种游戏的基本规则。
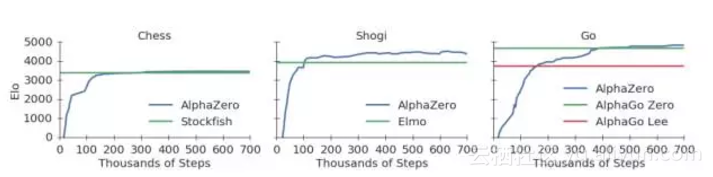
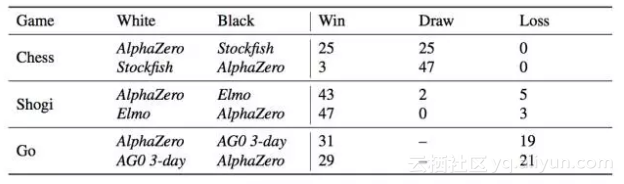
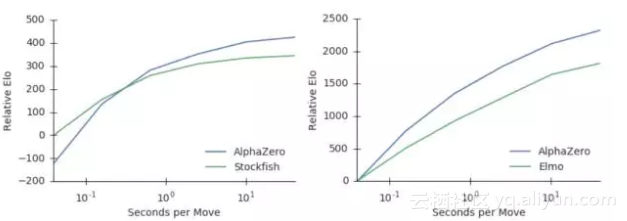
分析10万+人类开局,AlphaZero确实掌握了国际象棋,alpha-beta搜索并非不可超越
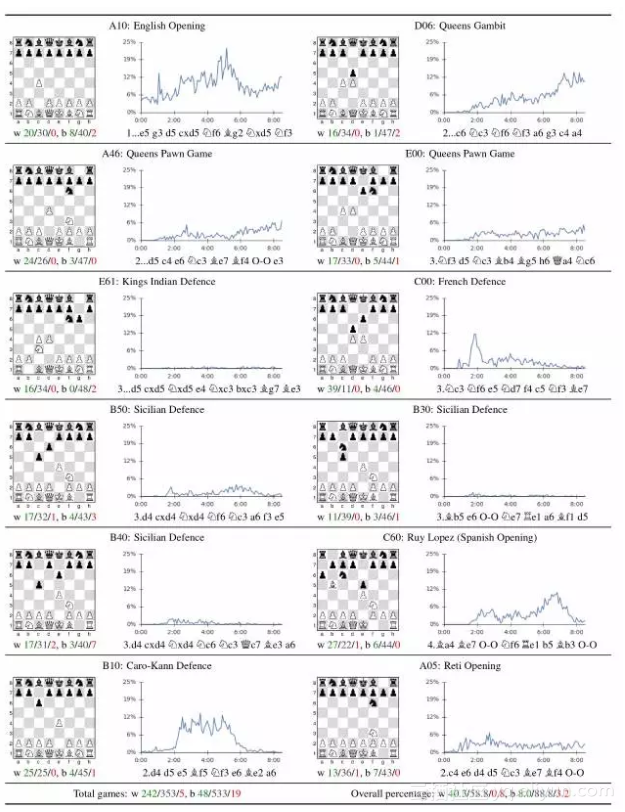
表2:对12种最受欢迎的人类的开局(在一个在线数据库的出现次数超过10万次)的分析。每个开局都用ECO代码和通用名称标记。这张图显示了自我对弈的比例,其中AlphaZero都是先手。
