

线性回归是用来度量变量间关系的统计技术。有意思的是该算法的实现并不复杂,但可以适用于很多情形。正是因为这些原因,我非常乐意以线性回归作为开始学习TensorFlow的开始。
请记住,不管在两个变量(简单回归)或多个变量(多元回归)情形下,线性回归都是对一个依赖变量,多个独立变量xi,一个随机值b间的关系建模。
在本小节中,会创建一个简单的例子来说明TensorFlow如何假设我们的数据模型符合一个简单的线性回归y = W * x + b,为达到这个目的,首先通过简单的python代码在二维空间中生成一系列的点,然后通过TensorFlow寻找最佳拟合这些点的直线。
首先要做的就是导入NumPy库,通过该库生成一些点,代码如下:

通过该代码,我们可以看到,我们生成了一些点并服从y = 0.1 * x + 0.3,因为增加了一些正态分布的偏差,所以这些点并不是完全符合这条直线,这样我们就生成了一个很有意思的例子。
本例子中,这些点经过显示后如下图所示,

读者可通过如下代码来生成该分布图(需要导入matplotlib库的一些函数,通过pip来安装matplotlib),

这些点将会是我们用来训练模型的数据集。
cost function 与梯度下降算法

下一步就是训练我们的学习算法,使其能从输入数据x_data计算得到输出值y。我们已经提前知道这是一个线性回归模型,所以我们用两个参数W与b来描述模型。
我们的目标是通过TensorFlow代码找到最佳的参数W与b,使的输入数据x_data,生成输出数据y_data,本例中将会一条直线y_data=W*x_data+b。读者知道W会接近0.1,b接近0.3,但是TensorFlow并不知道,它需要自己来计算得到该值。
标准的解决类似问题的方法是迭代数据集中的每一个值并修改参数W与b来每次获得更精确的结果。为确保随着迭代结果在逐渐变好,我们定义一个cost function(也被叫作“error function”)用来度量结果有多好(多坏)。
这个函数接收W与b的参数对并返回一个差值,该值代表了这条直线拟合数据的程度。在例子中,我们使用一个方差来表示cost function。通过平均方差,我们得到了算法每次迭代中生成的预估值与真实值间距离的平均“错误”。
稍后,将会介绍cost function的更多细节与替代者,但在这个例子中,平均方差会帮助我们一步步往最好的方向发展。
现在是时候开始用TensorFlow编程实现上面分析地所有细节了。首先先创建三个变量,

通过调用Variable方法定义一个变量,该变量会保存在TensorFlow内部图数据结构中。稍后我们会详细分析方法中的参数,我认为现在我们还是继续实现模型比较重要。
利用已经定义的变量,通过实际点与函数y= W * x + b计算得到的点之间的距离,我们可以实现cost function。随后,计算它的平方,求和后得平均值。在TensorFlow中,此cost function可表示为:
loss = tf.reduce_mean(tf.square(y - y_data)),
通过代码可以看到,此表达式计算了y_data与根据输入x_data计算得到的点y间距离的平方的平均值。
此时,读者可能已经知道拟合这些点最好的直线是有最小差值的那一条。因此,如果我们最小化error function,我们将会从数据中得到最好的模型。
这里先不介绍优化函数的详细细节,我们使用众所周知的梯度下降优化算法来最小化函数。在理论层面来说,梯度下降算法是给定一个参数集的函数,从参数集的初始值开始,向着函数最小化的参数值方向逐步迭代。通过朝着函数梯度负方向迭代前进来达到最小化。对距离求平方可以很方便地保证该值为正值同时使error function可微来计算梯度。
梯度下降算法以参数集的初始值开始(我们例子中是W与b),然后算法在迭代过程中逐步修改这些参数值,算法结束后,变量的值使得cost function获得最小值。
在TensorFlow中使用该算法,只需要执行下面两行代码:
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
到现在为止,TensorFlow已经有足够的信息在内部数据结构中创建相关数据,结构中也实现了一个为cost function定义的梯度下降算法优化器,该优化器可能会在后面训练过程中被调用。稍后我们会讨论函数的参数—学习速率(我们例子中为0.5)。
运行算法
如我们之前所学习到的,在代码中调用的TensorFlow库只是添加信息到内部图中,TensorFlow还没有运行该算法。正如前一章节中的例子一样,我们需要创建一个session,以train为参数调用run方法。因为我们已经定义了具体变量,我们必须提前初始化这些变量,命令代码如下:

现在我们可以开始迭代处理过程,算法会帮助我们找到W与b的值,该值使我们定义的模型能最好的拟合这些点。训练过程直到在数据集上达到了指定精度后才会停止。在这个具体例子中,我们假设只需要8次迭代就足够了,代码如下:

这段代码的运行结果中W与b的值会接近我们之前就知道的值。在这的机器上,打印的结果如下:

如果我们用下面代码以图的方式显示结果:

我们在图中可以看到8次迭代后得到的直线,参数W=0.0854与b=0.299.
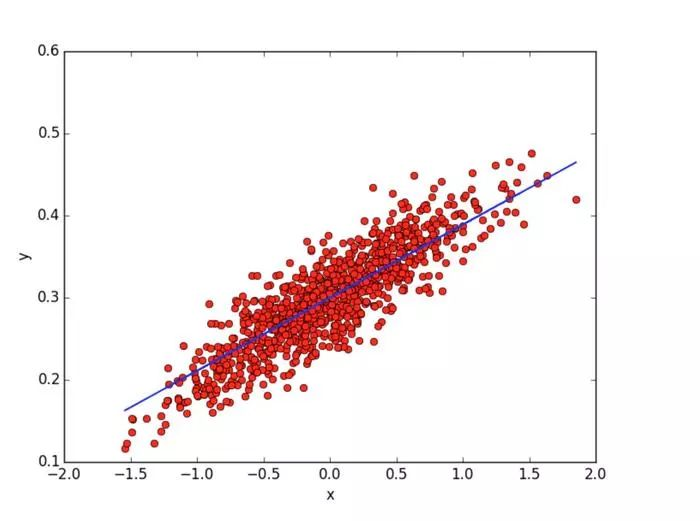
为了简单我们只执行了8次迭代,如果多迭代几次,得到的参数值会更接近真实值。可通过下面命令来打印W与b的值:
print(step, sess.run(W), sess.run(b))
在我的电脑中,显示的结果如下:

可以发现算法以初始值W=-0.0484与b=0.2972开始,然后算法逐步迭代参数值来最小化cost function。
同样可以用如下代码察看cost function逐渐减小的过程:
print(step,sess.run(loss))
在我机器上,显示的结果是:

建议读者把每次迭代后的图打印出来,这样我们可以观察算法每次调整参数值的过程,在本例子中,8次迭代过程的快照如下所示:
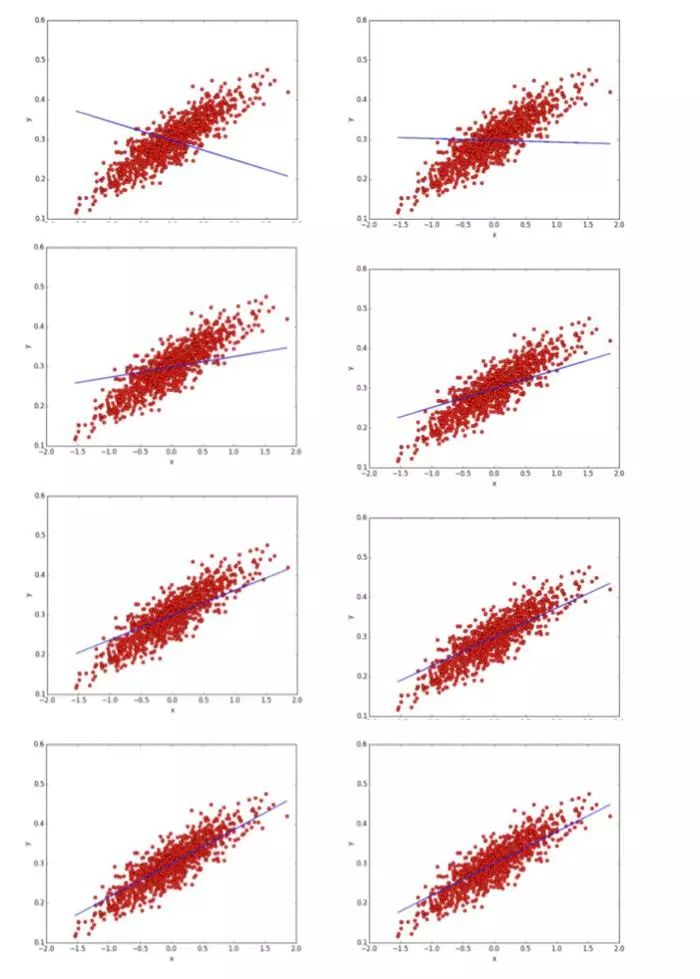
从图中可以读者可以发现,算法在每次迭代过程中都对数据拟合的越来越好。那么,梯度下降算法是如何逐渐逼近参数的值来使的cost function最小化呢?
因为我们的错误函数由两个参数(W和b)构成,可将其视为二维平面。该平面中的每一个点代表一条线。每个点上函数的高度是这条线的错误值。该平面上,一些线包含的错误值要比其它的小。当TensorFlow开始执行梯度下降查找后,它会从平面上某一点(例子中的点是W= -0.04841119与b= 0.29720169)开始,沿着最小差值的方向前进。
为在错误函数上运行梯度下降算法,TensorFlow计算它的梯度。梯度就像一个指南针,指引我们朝着最小的方向前进。为了计算梯度,TensorFlow会对错误函数求导,在我们的例子中就是,算法需要对W和b计算部分导数,以在每次迭代中为前进指明方向。
之前提到的学习速率,控制着每次迭代中TensorFlow前进的步长。如果该参数设置过大,可能会越过最小值。相反,如果该参数过小,需要大量迭代才能到达最小值。所以,使用恰当的学习速率非常重要。有一些不同的技术来选取学习速率,但这已经超出了本书讨论的范围。一个确保梯度下降算法很好工作的方法是确保每次迭代中错误都在减小。
为了帮助读者测试运行本章中的代码,读者可以从Github上下载regression.py文件,下面是该方件中的全部代码:
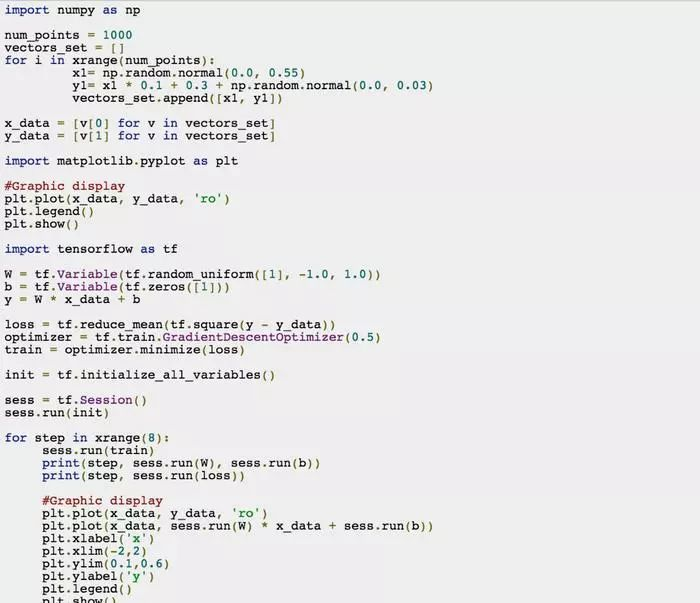
本章中,我们通过一个基本的线性回归算法来学习了TensorFlow库两个基本组件的使用:cost function与梯度下降算法。下一章节中我们会详细分析TensorFlow中基础数据结构的细节。
