

本篇推送主要涉及SQL语言中较为复杂的子查询与函数嵌套。
虽然这个MySQL系列取名为MySQL基础入门,但是个人不打算做单个函数的用法总结,或者说简单罗列,(这些内容你可以通过很多途径了解)因为一方面以前有过SQL基础方面的学习经历(本科的计算机必修课以及计算机等级考试)现在应该更加深入一些,另一方面SQL是一门数据分析语言,单纯的一个两个函数基本很少能解决问题。
SQL语言不像R语言和Python那种面向对象的语言,提供了各种灵活多变的的可用方法以及成千上万的高效解决工具,更没有提供像管道函数那样的参数传递工具,所以多重任务想要一次性解决大多数时候需要借助子查询和函数嵌套。
(如果你是第一次接触SQL语言,最好能够通过浏览一两本入门书或者系统了解一下SQL的查询语法之后再来看此文)
本文的练习数据素材取自天善智能大数据模块的畅销课程——“七周成为数据分析师”,主讲老师是在职场混迹多年的数据大咖,老司机秦路老师。
秦老师的课程针对数据分析师所需要的业务知识、分析技能、编程技能等各个模块都做了非常精彩的总结和案例分享,推荐喜欢或者感兴趣的小伙伴儿入手。
由于是付费课程,这里不便提供原始数据,还请各位见谅,但是文中所有的代码输出均会在适当的地方提供数据预览和字段描述,此文仅是我学习其中的MySQL模块的课程大作业,用自己的思路实现一遍,同时又按照老师的思路整理出代码,通过思路的对比查漏补缺、提升sql的代码实践能力。
同时我会把这份大作业使用R语言和Python中的常用分析工具实现,这样读者可以对比三种工具之间实现相同需求的过程差异以及各自优缺点,加深数据处理过程的理解。
首先大致介绍这两份数据:
userinfo 客户信息表
userId 客户id
gender 性别
brithday 出生日期
orderinfo 订单信息表
orderId 订单序号(虚拟主键)
userId 客户id
isPaid 是否支付
price 商品价格
paidTime 支付时间
以上两个表格是本次分析的主要对象,其中匹配字段是userId。
本次分析的五个问题:
1、统计不同月份的下单人数;
2、统计用户三月份回购率和复购率
3、统计男女用户消费频次是否有差异
4、统计多次消费的用户,第一次和最后一次消费间隔是多少?
5、统计不同年龄段用户消费金额是否有差异
6、统计消费的二八法则,消费的top20%用户,贡献了多少额度?
1、统计不同月份的下单人数;
第一道题目比较简单,仅需将日期字段通过日期函数转换为月份标签,然后根据月份标签聚合出单月下单的人数即可!
我的思路是使用DATE_FORMAT函数输出购买记录的月度标签,然后使用聚合函数group by函数对月度标签进行聚合(计数),使用count计数时要考虑重复购买的情况,进行客户去重,获取真实人数。
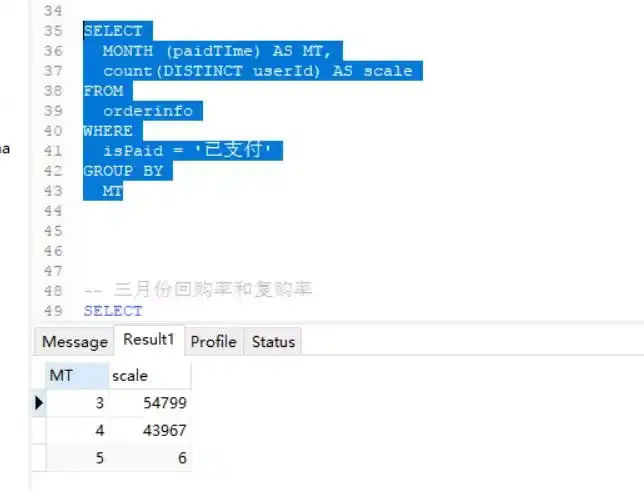
SELECT
DATE_FORMAT(paidTIme, '%Y-%m') AS MT,
count(DISTINCT userId) AS scale
FROM
orderinfo
WHERE
isPaid = '已支付'
GROUP BY
MT
因为购买日期字段都是同一个年份的,所有老师直接使用MONTH函数,这样更加简便!
SELECT
MONTH (paidTIme) AS MT,
count(DISTINCT userId) AS scale
FROM
orderinfo
WHERE
isPaid = '已支付'
GROUP BY
MT
2、统计用户三月份回购率和复购率
第二道题目需要理解回购率和复购率的业务含义(我之前都搞混了,后来去百度查的),复购率等于当月消费者中消费次数多于一次的人数占比,回购率则是上一个月消费者中在当月再次消费的占比。
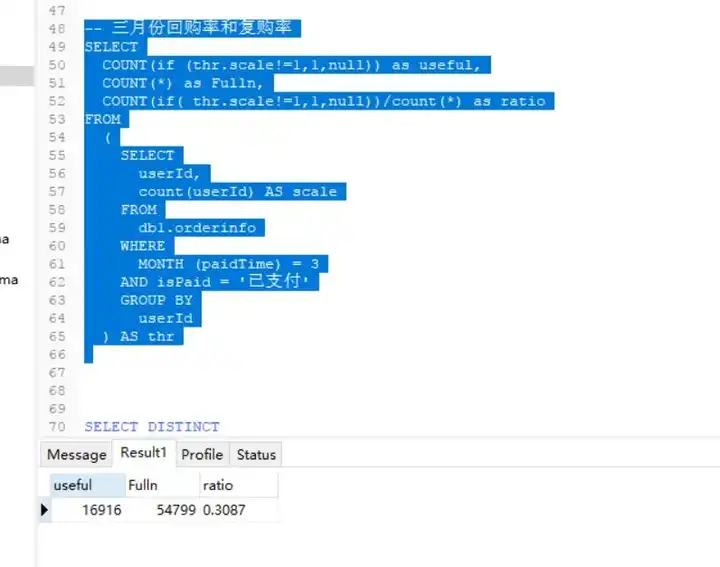
计算复购率(复购率的计算思路,自己的与老师的差不多):
先计算三月份购买人数,并作为一个子查询返回,外层查询使用count+if函数计算大于一次消费的购买者人数,将其与总人数相除,即可得到复购率。
SELECT
COUNT(if (thr.scale!=1,1,null)) as useful,
COUNT(*) as Fulln,
COUNT(if( thr.scale!=1,1,null))/count(*) as ratio
FROM
(
SELECT
userId,
count(userId) AS scale
FROM
db1.orderinfo
WHERE
MONTH (paidTime) = 3
AND isPaid = '已支付'
GROUP BY
userId
) AS thr
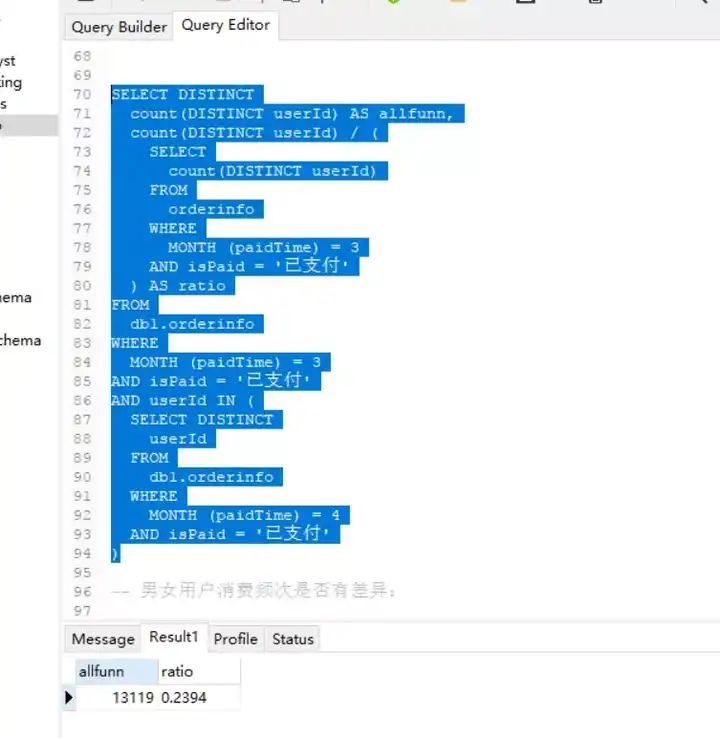
计算回购率(自己的思路):
对三月份购买者进行去重,使用count计算三月份购买者中有多少出现在四月份购买者中(通过在where中使用子查询作为过滤条件),将返回结果记录数与三月份购买者总人数相除即可得到回购率。
SELECT
count(DISTINCT userId) AS allfunn,
count(DISTINCT userId) / (
SELECT
count(DISTINCT userId)
FROM
orderinfo
WHERE
MONTH (paidTime) = 3
AND isPaid = '已支付'
) AS ratio
FROM
db1.orderinfo
WHERE
MONTH (paidTime) = 3
AND isPaid = '已支付'
AND userId IN (
SELECT DISTINCT
userId
FROM
db1.orderinfo
WHERE
MONTH (paidTime) = 4
AND isPaid = '已支付'
)
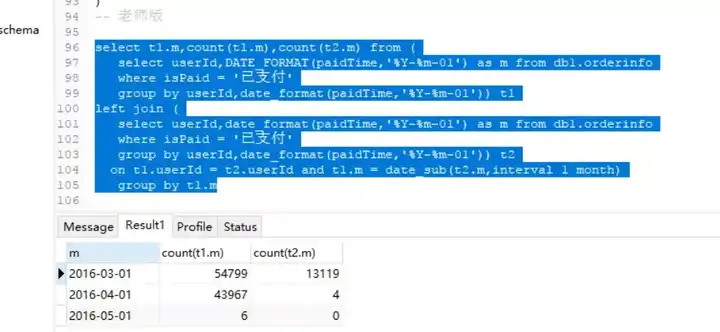
关于回购率,老师使用了一个自连接,勉强能理解大致思路,通过对比两个月份的月度标签是否相差一个月,相差一个月则为老客户重复购买,这样在月份多时具有更好地适用性。
select t1.m,count(t1.m),count(t2.m) from (
select userId,DATE_FORMAT(paidTime,'%Y-%m-01') as m from db1.orderinfo
where isPaid = '已支付'
group by userId,date_format(paidTime,'%Y-%m-01')) t1
left join (
select userId,date_format(paidTime,'%Y-%m-01') as m from db1.orderinfo
where isPaid = '已支付'
group by userId,date_format(paidTime,'%Y-%m-01')) t2
on t1.userId = t2.userId
and t1.m = date_sub(t2.m,interval 1 month)
group by t1.m
3、统计男女用户消费频次是否有差异
这个问题被我给复杂化了,我分别求了一次男性消费频次和女性消费频次!思路就是先将用户表和订单表做联结,然后过滤性别为男的记录并通过分组返回单一消费者记录。(女性的计算类比男性)
-- 男性消费频次
SELECT
SUM(mmg.mean) / count(*) AS mam_m
FROM
(
SELECT
orderinfo.userId,
ROUND(COUNT(orderinfo.userId), 1) AS mean
FROM
orderinfo
INNER JOIN userinfo ON orderinfo.userId = userinfo.userId
WHERE
userinfo.gender = '男'
GROUP BY
orderinfo.userId
) AS mmg
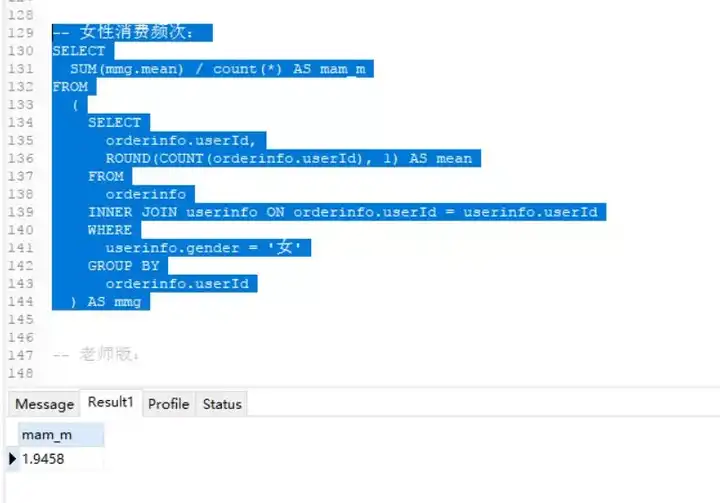
-- 女性消费频次:
SELECT
SUM(mmg.mean) / count(*) AS mam_m
FROM
(
SELECT
orderinfo.userId,
ROUND(COUNT(orderinfo.userId), 1) AS mean
FROM
orderinfo
INNER JOIN userinfo ON orderinfo.userId = userinfo.userId
WHERE
userinfo.gender = '女'
GROUP BY
orderinfo.userId
) AS mmg
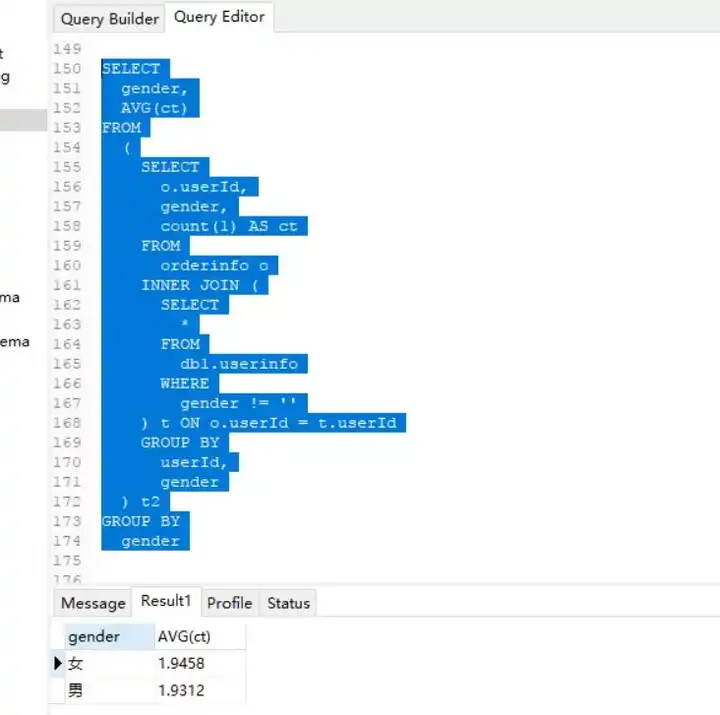
男女消费频次(老师版):
老师首先在连接两个表的基础上,剔除了无效记录,通过count做了单个购买者的购买数量统计,
然后使用了基于性别的分组均值聚合,输出男女性平均消费频次。这个思路太棒了,我特么的就是想不到~_~
SELECT
gender,
AVG(ct)
FROM
(
SELECT
o.userId,
gender,
count(1) AS ct
FROM
orderinfo o
INNER JOIN (
SELECT
*
FROM
db1.userinfo
WHERE
gender != ''
) t ON o.userId = t.userId
GROUP BY
userId,
gender
) t2
GROUP BY
gender
4、统计多次消费的用户,第一次和最后一次消费间隔是多少?
这个题目是我耗费我时间最长的一道题目,其实逻辑上肯定大家都知道需要筛选出那些消费次数大于1次的记录,然后通过单个购买者所有消费记录中最远的消费时间与最近的消费时间做时间差即可。说起来简单可以做起来并不简单。于是我把代码写成了下面这个样子!
SELECT
* FROM
(
SELECT
userId,
DATEDIFF(
myresult.uptime,
myresult.odtime
) AS difftime
FROM
(
SELECT
lowf.userId,
lowf.odtime,
UPf.uptime
FROM
(
SELECT
userId,
min(ldd.ltime) AS odtime
FROM
(
SELECT
userId,
paidTime AS ltime
FROM
orderinfo
WHERE
isPaid = '已支付'
ORDER BY
userId,
Ltime
) AS ldd
GROUP BY
userId
) AS lowf
INNER JOIN (
SELECT
userId,
max(pdd.ptime) AS uptime
FROM
(
SELECT
userId,
paidTime AS ptime
FROM
orderinfo
WHERE
isPaid = '已支付'
ORDER BY
userId,
ptime DESC
) AS pdd
GROUP BY
userId
) AS UPf
ON lowf.userId = UPf.userId
) AS myresult
) AS myresult1
WHERE
difftime != 0
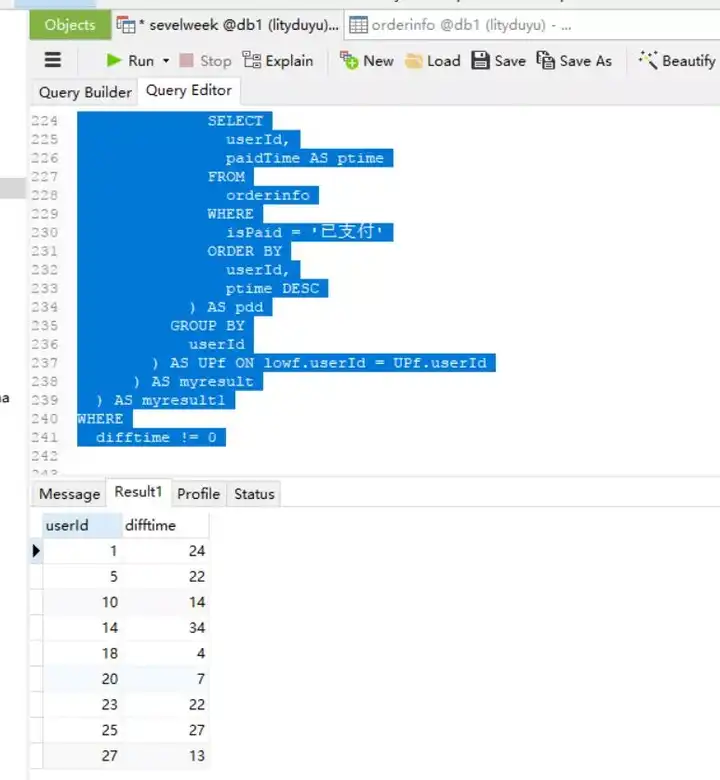
我的大体思路是,最内层的逻辑是先筛选出来消费者距今最远消费记录,最近消费记录,并将两次输出做内连接。在输出的表基础上,做时间差,如果时间为0则说明只有一次消费,直接使用difftime != 0过滤掉即可。
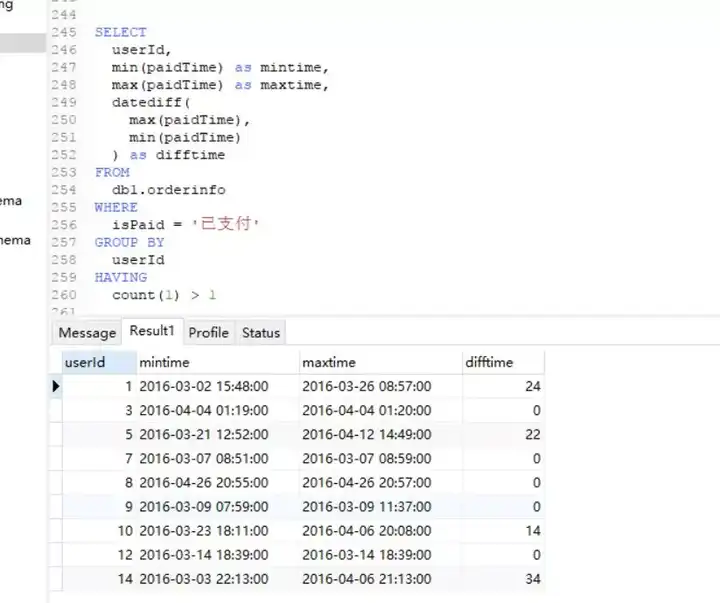
以下是老师给出的思路,看完之后大呼自愧不如,可以看到我上面的那个内连接是多此一举,使用max、min两个函数并列字段就可以解决,但是我写的太复杂了!居然也能跑出来。
SELECT
userId,
min(paidTime) as mintime,
max(paidTime) as maxtime,
datediff(
max(paidTime),
min(paidTime)
) as difftime
FROM
db1.orderinfo
WHERE
isPaid = '已支付'
GROUP BY
userId
HAVING
count(1) > 1
5、统计不同年龄段用户消费金额是否有差异
这个问题乍一看,我不太理解,最初想着这个年龄段怎么定义(没有给出精确的定义),然后我就想着平时一说到年龄代购就说什么70后、80后、90后什么的,就以为这种就可以做年龄段依据。
我个人的大体思路就是,最内层首先做两个表的联结(联结的同时过滤掉缺失值和未支付记录),然后中间层对出生日期进行分类编码(1970~1979为70后,以此类推)。
最后最外层通过对年龄段进行分组聚合,求不同年龄段下的支付价格的均值。
SELECT
trend,
round(avg(price), 2) AS means
FROM
(
SELECT
userId,
btdate,
price,
CASE
WHEN btdate BETWEEN '1970-01-01' AND '1979-12-31' THEN '70后'
WHEN btdate BETWEEN '1980-01-01' AND '1989-12-31' THEN '80后'
WHEN btdate BETWEEN '1990-01-01' AND '1999-12-31' THEN '90后'
WHEN btdate BETWEEN '2001-01-01' AND '2009-12-31' THEN '00后'
ELSE '10后'
END
AS 'trend'
FROM
(
SELECT
o.userId,
price,
date(brith) AS btdate
FROM
orderinfo o
LEFT JOIN (
SELECT * FROM
db1.userinfo
WHERE
gender != ''
) t ON o.userId = t.userId
WHERE
isPaid = '已支付'
AND
date(brith) != '0000-00-00'
) AS mt
ORDER BY
userId
) AS outtable
GROUP BY
trend
ORDER BY
means
关于年龄段消费金额差异,老师给出的思路:
SELECT
age,
AVG(ct)FROM
(
SELECT
o.userId,
age,
count(o.userId) AS ct
FROM
db1.orderinfo o
INNER JOIN (
SELECT
userId,
CEIL((YEAR(now()) - YEAR(brith)) / 10) AS age
FROM
db1.userinfo
WHERE
brith > '1901-00-00'
) AS t
ON o.userId = t.userId
GROUP BY
o.userId,
age
) t2
GROUP BY
age
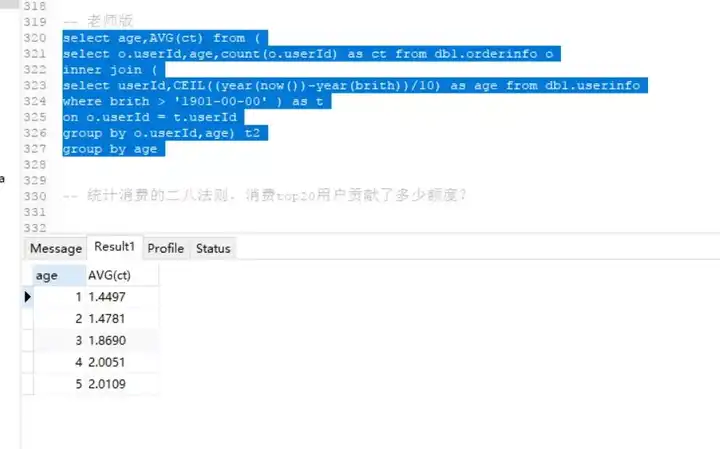
以上老师计算了各年龄段购买者消费消费频次的平均值。这里老师使用日期函数替代了分别编码工作,使得整体代码看起来很简洁易懂。(自己需要学的还有很多!)
6、统计消费的二八法则,消费的top20%用户,贡献了多少额度?
其实这个二八法则的问题逻辑很简单,就是按照单个消费者总消费金额排序,计算出那些前20%的的购买者消费金额占总体消费金额的比例。虽然逻辑很简单,但是在MySQL中想要写出次逻辑却并不是一件容易的事情,因为MySQL不支持 top n 这种函数,想要过滤前n个记录只能通过 追加 limit参数才可以。
所以我自己写了两段代码才解决:
首先按照单个消费者总购买金额排序,计算出前总支出排在前top20的消费者数量。(一共是17130)
SELECT
ceil(count(*) / 5)
FROM
(
SELECT
userId,
sum(price) AS allsp
FROM
orderinfo
WHERE
date(paidTime) != '0000-00-00'
AND isPaid = '已支付'
GROUP BY
userId
ORDER BY
allsp DESC
) AS spend
-- 17130
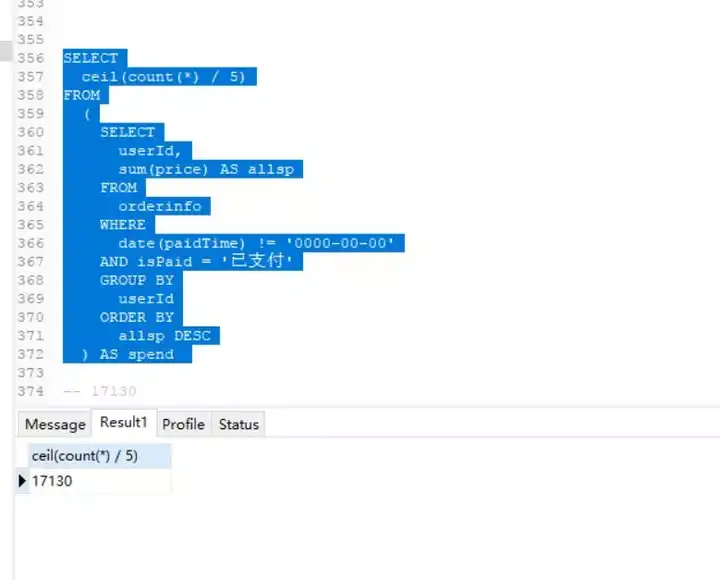
然后再次运行次查询,使用limit参数限制输出前17130 个记录并计算其总金额占所有消费金额的比例即可。
SELECT
(
SELECT
sum(allsp) AS top20
FROM
(
SELECT
userId,
sum(price) AS allsp
FROM
orderinfo
WHERE
date(paidTime) != '0000-00-00'
AND isPaid = '已支付'
GROUP BY
userId
ORDER BY
allsp DESC
LIMIT 17130
) AS spend
) / (
SELECT
sum(allsp) AS entry
FROM
(
SELECT
userId,
sum(price) AS allsp
FROM
orderinfo
WHERE
date(paidTime) != '0000-00-00'
AND isPaid = '已支付'
GROUP BY
userId
ORDER BY
allsp DESC
) AS spend
) as top20ratio
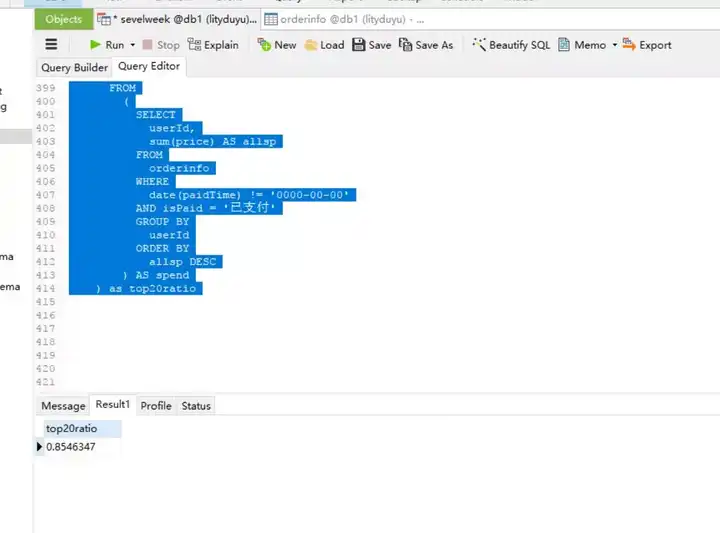
计算结果是85.46%左右。
由于篇幅所限,关于这五个问题的R语言版、Python版,期待下一篇推送吧!
说几点个人感想:
1、因为之前关于数据清洗和数据处理技能,全部都是在R语言中练习的,突然使用SQL来做,即便很简单的需求逻辑,写起来都感觉磕磕碰碰,总之就是无法灵活运用,简单问题往往被复杂化。
2、SQL中查询语句有固定的模式,所有的输出都要严格依赖select …… from…… where group by语句,甚至连各种函数都无法单独使用,这一点儿导致很多需要多步完成需求无法分割成多个中间步骤,必须借助子查询。
3、SQL没有像R语言一样的管道操作符或者Python中的方法调用,多任务步骤在一个句子中只能依赖子查询进行嵌套,稍微复杂些的需求,如果基础函数使用不够灵活的话,可能会写的很繁杂。
SQL查询语法需要在深刻理解表关系的基础上,尽量使用自带函数解决,这样既高效、又可以节省代码,以上自己写的代码中,有特别多的地方有冗余,以后还需要勤加练习,加强各种场景下的实践,灵活运用才能写出来简洁、高效、可复用性高的任务代码。
以下链接是秦路老师在天善学院所主讲的七周成为数据分析师系列课程!
七周课程,七种数据分析师必备技能,循序渐进、逐个击破,推荐给对数据分析、商业分析感兴趣的小伙伴儿学习!
