

一、Django简单接口开发分享:
1、在开发之前需要配置开发环境,摆脱Ubuntu上面开发,在Mac电脑上面创建虚拟环境开发
2、django-admin startproject jiekou
3、创建应用python manage.py startapp myjiekou
4、打开项目,把应用注册在setting.py文件
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'myjiekou',
)
5、在models.py文件里面定义模型类,定义需要的字段
# encoding=utf-8
from django.db import models
# Create your models here.
class MyModel(models.Model):
# 姓名
name = models.CharField(max_length=20)
# 年龄
age = models.CharField(max_length=100)
# 爱好
hobby = models.CharField(max_length=300)
6、生成迁移文件python manage.py makemigrations
7、生成迁移python manage.py migrate,迁移完成以后会自动生成一个auth表
8、运行python manage.py runserver,通过连接http://127.0.0.1:8000/admin看下后台管理界面
9、看后台管理界面之前需要注册管理员账号python manage.py createsuperuser
10、登进去以后为什么没有我们新建的表格那?
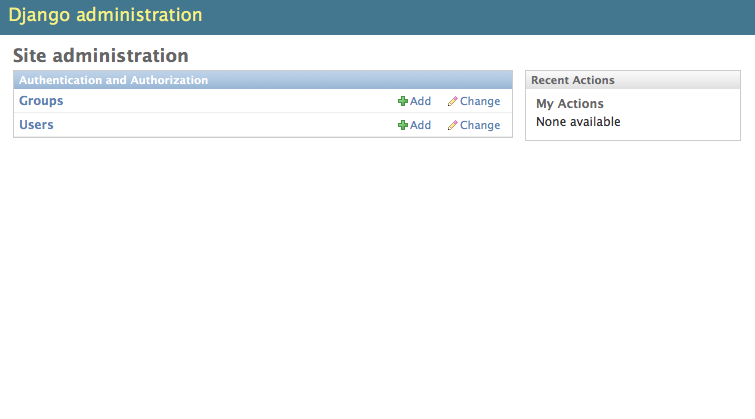 admin.png
admin.png 原因是:我们没有在admin.py文件里面进行注册我们的模型类,接下来进行注册
from django.contrib import admin
from myjiekou.models import MyModel
# Register your models here.
class MyAdmin(admin.ModelAdmin):
list_display = ["name","age","hobby"]
admin.site.register(MyModel,MyAdmin)
11、再次执行python manage.py runserver 12、让我们再看一下admin管理界面,并添加字段
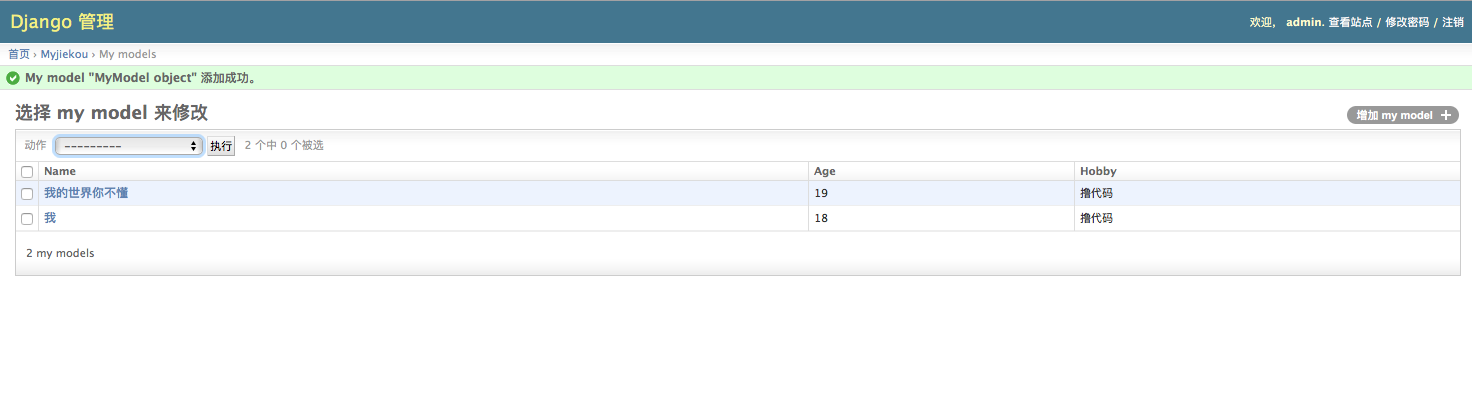 admin1.png
admin1.png 13、我们再admin管理界面的数据怎么怎么在django web页面显示那我们来进行下步操作,我们目的需要通过http://127.0.0.1:8000/index来进行访问显示我们输出的内容,首先我们先进行简单的显示
#encoding=utf-8
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def index(request):
return HttpResponse("你好 我的体育老师")
 admin2.png
admin2.png
再次,我们需要把SQLite数据展示在我们页面上,首先导入我们的模型类
setting.py配置路径
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR),'templates'],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
在view.py文件中
#encoding=utf-8
from django.shortcuts import render
from django.http import HttpResponse
from models import MyModel
# Create your views here.
def index(request):
content = MyModel.objects.all()
list = {"content":content}
return render(request,"myjiekou/index.html",list)
index.html显示
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul>
{% for item in content %}
<li>{{ item.name }}</li>
<li>{{ item.age }}</li>
<li>{{ item.hobby }}</li>
{% endfor %}
</ul>
</body>
</html>
注意:我们再操作过程中会产生一些问题,例如下面,我们解决就好
MIDDLEWARE_CLASSES = [
'django.contrib.sessions.middleware.SessionMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
]
14、管理界面汉语化
LANGUAGE_CODE = 'en-us'
15、接下来进行django接口开发
首先导入模块
from django.http import JsonResponse
url配置
from myjiekou import views
urlpatterns = [
url(r'^admin/', include(admin.site.urls)),
url(r'^index/', views.index),
url(r'^api/', views.api),
]
api实现
def api(request):
list = []
item = {}
content = MyModel.objects.all()
for one in content:
item["name"] = one.name
item["age"] = one.age
item["hobby"] = one.hobby
list.append(item)
return JsonResponse({"status":200,"date":list})
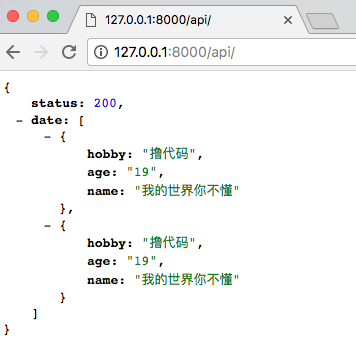 admin3.png
admin3.png 接下来我运行一下OC程序来调用这个接口,看是否调用成功
二、爬虫爬取某个网站
先了解下爬虫的基础模块
1、re模块:主要是使用正则匹配对抓取的数据进行分析
2、XPath:查找 HTML 节点或元素进行数据过滤
3、BeautifulSoup4: 也是一个HTML/XML的解析器,解析和提取 HTML/XML 数据
4、JSON与JsonPATH:JSON数据解析
下面通过一个实例说明,主要使用了XPath查找 HTML 节点或元素解析
# -*- coding:utf-8 -*-
import urllib2,os
import lxml.etree
class Xunmall():
def __init__(self):
self.url = "http://www.xunmall.com"
def get_html(self,p1 = ""):
# headers = {
# "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Mobile Safari/537.36"}
request = urllib2.Request(self.url + p1)
response = urllib2.urlopen(request)
html = response.read()
return html
def get_xpath(self):
xmlcontent = lxml.etree.HTML(self.get_html())
xmllist = xmlcontent.xpath('//h2[@class="floor_name"]/text()')
for item in xmllist:
with open('title.txt','a') as file:
file.write(item.encode('utf-8') + '\n')
file.close
def get_image(self):
xmlimage = lxml.etree.HTML(self.get_html())
imagelist = xmlimage.xpath('//div[@class="color_top"]/img/@src')
if os.path.isdir('./imgs'):
pass
else:
os.mkdir("./imgs")
for item in imagelist:
print self.url + item
with open('imgs/' + (self.url + item)[-8:],'a+') as file:
file.write(self.get_html(item))
file.close
def get_theme(self):
xmltheme = lxml.etree.HTML(self.get_html())
themelist = xmltheme.xpath('//h3[@class="floor_theme"]/text()')
for item in themelist:
with open('theme.txt','a') as file:
file.write(item.encode('utf-8') + '\n')
file.close
sloganlist = xmltheme.xpath('//p[@class="slogan"]/text()')
for item in sloganlist:
with open('theme.txt','a') as file:
file.write(item.encode('utf-8') + '\n')
file.close
give_outlist = xmltheme.xpath('//p[@class="give_out"]/text()')
for item in give_outlist:
with open('theme.txt', 'a') as file:
file.write(item.encode('utf-8') + '\n')
file.close
def get_html1(self,p2):
request = urllib2.Request(p2)
response = urllib2.urlopen(request)
html = response.read()
return html
# 食品标题和图片
def foodImageTitle(self):
foodImage = lxml.etree.HTML(self.get_html())
foodImageList = foodImage.xpath('//div[@class="pro_image"]/img/@src')
if os.path.isdir('./foodimage'):
pass
else:
os.mkdir("./foodimage")
for item in foodImageList:
print item
with open('foodimage/' + item[-20:],'a+') as file:
file.write(self.get_html1(item))
file.close
# 每个零食的详细信息(标题、图片、副标题)
def detail(self):
detailLink = lxml.etree.HTML(self.get_html())
detailLinkList = detailLink.xpath('//div[@class="nth_floor first_floor"]/div[@class="goods_box"]/ul[@class="item_list"]//a/@href')
for item in detailLinkList:
# print item[-18:]
detailUrl = lxml.etree.HTML(self.get_html("/" + item[-18:]))
detailImageList = detailUrl.xpath(
'//div[@class="info-panel panel1"]/img/@src')
for detailitem in detailImageList:
print '正在下载详情图片'
if os.path.isdir('./' + item[-18:-5]):
pass
else:
os.mkdir("./" + item[-18:-5])
with open(item[-18:-5] + '/' + detailitem[-9:], 'a+') as file:
file.write(self.get_html1(detailitem))
file.close
# 商品标题
detailtitleList = detailUrl.xpath(
'//div[@class="col-lg-7 item-inner"]//h1[@class="fl"]/text()')
for title in detailtitleList:
with open('foodtitle.txt', 'a+') as file:
file.write(title.encode('utf-8') + '\n')
file.close
# 商品编号
goodnumberList = detailUrl.xpath(
'//div[@class="col-lg-7 item-inner"]//li[@class="col-lg-5 col-md-5"]/text()')
for number in goodnumberList:
print number
if os.path.isdir('./qrcoder'):
pass
else:
os.mkdir("./qrcoder")
with open('qrcoder', 'a+') as file:
file.write(number.encode('utf-8') + '\n')
file.close
# 商品二维码:data_code
coderImageList = detailUrl.xpath('//div[@class="clearfixed"]//div[@class="barcode fr"]/img/@data_code')
for item in coderImageList:
print item
with open('goodnumber.txt', 'a+') as file:
file.write(item + '\n')
file.close
if __name__ == "__main__":
# 获取分类标题
xunmall = Xunmall()
# xunmall.get_xpath()
# 获取图片
# xunmall.get_image()
# 图片上面的标题
# xunmall.get_theme()
# 休闲食品标题和图片
# xunmall.foodImageTitle()
xunmall.detail()
后续会分享Swift哦,只是简单的分享下学习成果,和项目组一起探讨和学习。
