

作者:李立 导语: “不需要人类知识” 得以实现是因为模型+ MCTS 提升器 的训练方法。在利用模型的基础上,MCTS 提升器总是强于模型本身,从而为模型提升指明了方向;模型的提升又进一步增强了 MCTS 提升器的能力;这就形成了正向循环。一个总是比模型强的提升器,是正向循环能够建立的关键。
AlphaGo Zero [1] 已经出来一段时间了。本来 AlphaGo Zero 一出来就应该写科普的,但自己实在懒。等到现在才更新。

AlphaGo Zero 最大的亮点是:完全没有利用人类知识,就能够获得比之前版本更强大的棋力。主要的做法是: 1) 利用蒙特卡洛树搜索建立一个模型提升器,2) 在自我对弈过程中,利用提升器指导模型提升,模型提升又进一步提高了提升器的能力。
1. 蒙特卡洛树搜索简介
蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS) 是一种树型搜索技术,具有如下所示的树型结构。
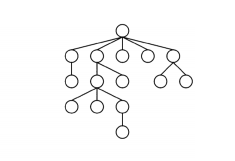
树中每一个节点 s 代表了一个围棋盘面,并带有两个数字。一个是访问次数N(s),另一个质量度Q(s)。访问次数 N(s)表示在搜索中节点被访问的次数。面对一个盘面,MCTS 会进行重复搜索,所以一个节点可能会被反复访问,这个下面细说。质量度Q(s)表示这个节点下 AlphaGo 的优势程度,其计算公式如下所示。
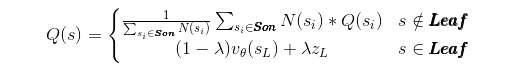
这个公式的意思是:1)对于非叶子节点,质量度等于该节点所有树中已有子节点的质量度均值。2)对于叶子节点,质量度跟价值网络估计的获胜概率vθ(sL)有关,还跟快速走子模拟后续比赛得到的胜负结果zL有关。叶子节点的质量度等于这两者的加权混合,其中混合参数λ介于0和1之间。
有了 MCTS 的结构,我们就可以继续介绍 MCTS 怎么做搜索的。当对手落了一子,AlphaGo 迅速读入当前盘面,将之当作搜索的根节点,展开搜索。MCTS 搜索的流程如下图所示,一共分为四个步骤:
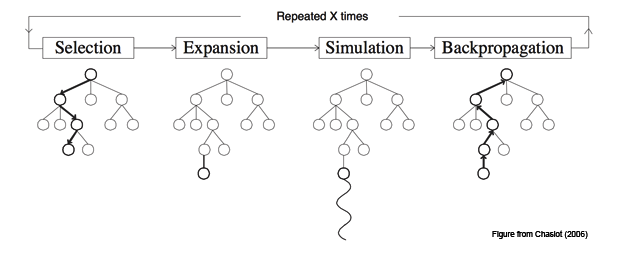
- 选择:从根节点 R 开始,递归选择某个子节点直到达到叶子节点 L。当在一个节点s,我们怎么选择子节点si呢?我们选择子节点不应该乱选,而是应该选择那些优质的子节点。AlphaGo 中的选择子节点的方式如下所示。
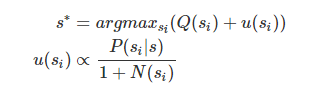
其中p(si|s)是策略网络的输出。一个有意思的点在于一个节点被访问次数越多,选择它作为子节点的可能性越小,这是为了搜索多样性考虑。
扩展:如果 L 节点上围棋对弈没有结束,那么可能创建一个节点 C。
模拟:计算节点 C 的质量度。
反向传播:根据 C 的质量度,更新它爸爸爷爷祖先的质量度。
上述搜索步骤反复进行,直到达到某个终止条件。搜索结束后,MCTS 选择根节点的质量度最高的子节点作为 AlphaGo 的着法。
2. 网络结构和训练方法
AlphaGo Zero 的网络结构和之前的版本不同。AlphaGo Zero 的网络结构采用了 resnet 网络,而之前的版本则采用了传统的 CNN 网络。同时 AlphaGo Zero 将 policy 网络和 value 网络结合在一起,一个网络同时输出不同动作概率和预估胜率,如下所示。
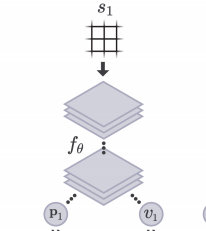
网络结构定义好了,我们来看下 AlphaGo Zero 是怎么自我对弈 (Self-Play) 进行训练的。将上面的模型接入 MCTS, MCTS 就能有策略地进行搜索,搜索结果是当前盘面不同动作的概率。由于 MCTS 经过了搜索,输出的动作概率肯定要好于模型自身输出的动作概率,因此可以将 MCTS 视作模型的提升器。自我对弈是从初始围棋盘面开始;MCTS 输入当前盘面 s1 输出不同动作概率 p1,按照该概率采样一个动作作为玩家落子;MCTS 作为对手输入当前盘面 s2 输出不同动作的概率 p2,按照该概率采样一个动作作为对手的落子;不停执行,直到分出胜负 z。收集数据(s1,p1,z),..., 作为训练数据训练模型。整个训练流程如下所示。
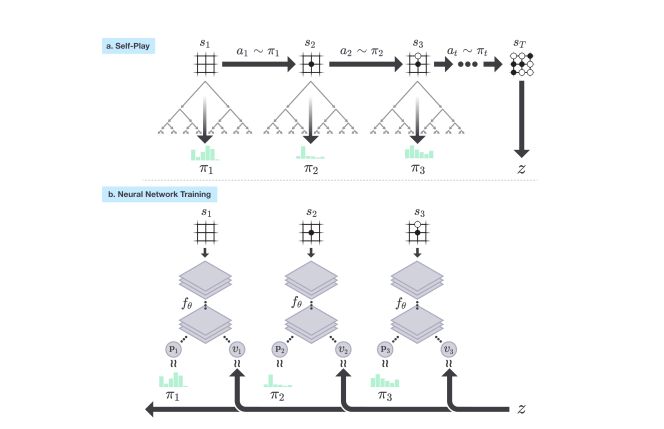
在这里,我个人有点疑问。这种训练方法明显地和我们认知的基于马尔科夫决策过程 (Markov Decision Process, MDP) 的强化学习有区别,但论文还是称之为强化学习。难度强化学习有更广义的定义嘛?
3. 实验效果
3.1 不同网络结构的比较
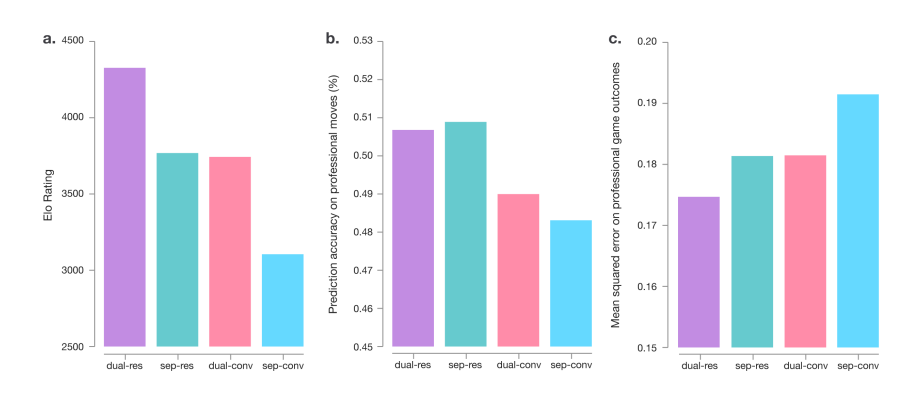
AlphaGo Zero 网络结构有两个改动:1) 用 resnet 替代了传统 CNN, 2) 合并了 policy 网络和 value 网络。下图可以看出这两个改动能提高 AlphaGo Zero 的效果(sep 表示policy和value分开,dual 表示合在一起; res 表示 resnet 网络,cnn 表示传统的CNN)。
3.2 不同版本 AlphaGo 的比较
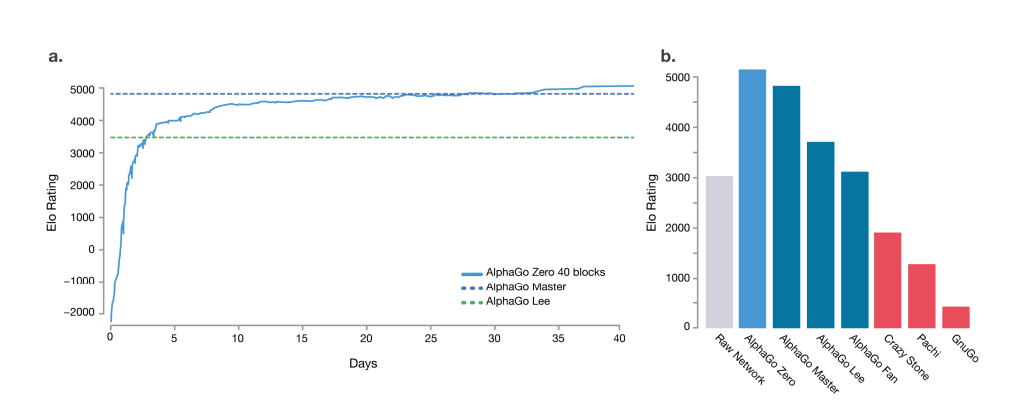
从下图可以看出,不用人类知识的 AlphaGo Zero 超过之前的版本。另外从下图能看出来的是,训练完成之后,MCTS 提升器 + 模型的能力还是要比模型要强。
4. 总结
大家以为围棋都做到头了,其他做围棋的团队在极力用旧方法提高棋力。没有想到 DeepMind 以 “不需要人类知识” 为最大亮点,搞出这么一个重磅研究工作。“不需要人类知识” 得以实现是因为模型+ MCTS 提升器的训练方法。在利用模型的基础上,MCTS 提升器总是强于模型本身,从而为模型提升指明了方向;模型的提升又进一步增强了 MCTS 提升器的能力;这就形成了正向循环。一个总是比模型强的提升器,是正向循环能够建立的关键。
很多自媒体已经开始鼓吹,这是迈向通用智能的重要一步。这个是不对的。围棋因为规则明确和完全信息,我们找到了 MCTS 这个总是比模型强的模型提升器。但在更多通用领域,这样的模型提升器还是比较难找到的。
本文首发于博客:www.algorithmdog.com/alphago-zer… 和微信公众号 AlgorithmDog,欢迎大家关注~
相关阅读
被 TensorFlowLite 刷屏了吧,偏要再发一遍
学习笔记DL002:AI、机器学习、表示学习、深度学习,第一次大衰退
学习笔记DL001 : 数学符号、深度学习的概念
此文已由作者授权腾讯云技术社区发布,转载请注明原文出处
原文链接:https://cloud.tencent.com/community/article/192908?fromSource=gwzcw.631407.631407.631407
海量技术实践经验,尽在腾讯云社区
