

前言:这几天在写一个工具脚本分析线上的大量的日志文件,本来应该是索然无味的一个工作,但是本着做到极致的原则,激发了我不断思考如何优化。本文将从开发过程中的最开始版本,一点点讲解优化的过程,最终用golang实现了一个类似java的worker线程池,收获满满。
一,无脑开goroutine阶段
1,任务背景 这个工具的作用简单介绍如下:首先是线上的日志量是非常庞大的,然后要去读取日志文件的内容,然后一条条日志项分析,匹配出想要的日志项写入文件,再提取该文件中的数据计算。日志项格式模拟数据如下:
{
"id":xx,"time":"2017-11-19","key1":"value1","key2":"value2".......
}
2,无脑开gorountine 先给下代码(只放核心代码,省略文件操作和异常错误处理),再来说说这个阶段的思路
var wirteChan = make(chan []byte) //用于写入文件
var waitgroup sync.WaitGroup //用于控制同步
func main(){
//省略写入文件的打开操作,毕竟我们主要讲并发这块
//初始化写入的channel
InitWriter(outLogFileWriter)
//接下来去遍历每个日志文件,每读出一个日志项就开一个gorountine去处理
for _,file := range logDir {
if file.IsDir() {
continue
} else {
HandlerFile(arg.dir + "/" + file.Name()) //处理每个文件
}
}
}
/**
* 初始化Writer的channel
*/
func InitWriter(outLogFileWriter *bufio.Writer) {
go func() {
for data := range wirteChan {
nn, err := outLogFileWriter.Write(data)
}
}()
}
//处理每个文件,然后开G去处理每个日志项
func HandlerFile(fileName string) {
file, err := os.Open(fileName)
defer file.Close()
br := bufio.NewReader(file)
for {
data, err := br.ReadBytes('\n')
if err == io.EOF {
break
} else {
go Handler(data) //每次开一个G去处理,处理完写入writeChannel
}
}
}
解析:写博客很不喜欢放大篇幅代码,所以上面给的只是重要的代码,上面代码注释有说到的也不重复说了。好了,我们来想想上面的代码有什么问题?我们现在就假设我们就只有一个非常大的文件,文件中每个记录项都无脑开一个G去执行。那么,运行一下,我们会发现,好慢呀~。问题出在哪里呢?首先我们无法控制G的数量,其次日志文件非常大,这样运行下来,G的数量是非常庞大的,多个G要往一个channel中写数据,那么也会发生严重的阻塞。种种原因,导致了这个方法是不适用的
二,加入带缓冲的任务队列
1,任务队列 在上面我们说到,我们无法控制任务的数量,那么,我在这里就加入了一个任务队列,来对任务进行排队,同时可以控制任务的数量。上代码:
/**
* Job结构体,包含要处理的数据和处理函数(这个可根据需要修改)
*/
type Job struct {
Data []byte
Proc func([]byte)
}
//Job队列,存储要做的Job,将每个任务打包成Job发送到这里
var JobQueue chan Job = make(chan Job, arg.maxqueue)
//启动处理函数处理
func Handler(Data []byte) {
for range job := <-Queue {
job.Proc(Data)
}
}
解析:在这个时候,抽象出来了任务模型Job,由于函数调用其实就是函数地址加函数参数,所以我们可以将处理函数也放进Job中。然后让处理函数去处理就行了。想到这里,稍微有点佩服自己了,接着兴致勃勃的运行一下。嗯,好像没快多少(其实这个取决了你的处理函数,就是Job中的Proc)。What?冷静下来分析一下,真觉得自己真可爱。我仅仅是对任务进行了包装,然后用了一个带缓冲的任务队列,由于创建的Job远远大于单个M的处理能力,带缓冲只是稍微把问题拖后了一点。
三,Job/Worker模型
其实写到这里,心里对如何优化已经有点B数了。我想起了java中的线程池的概念,我可以建立一个线程池,然后池中包含多个worker(数量可以指定),每个worker去队列中取任务处理,处理完则继续取任务。同时为了提高通用性,参数类型都改为了interface{}。好了,接下来看看代码,这里的代码都很关键,所以就全部放上来了
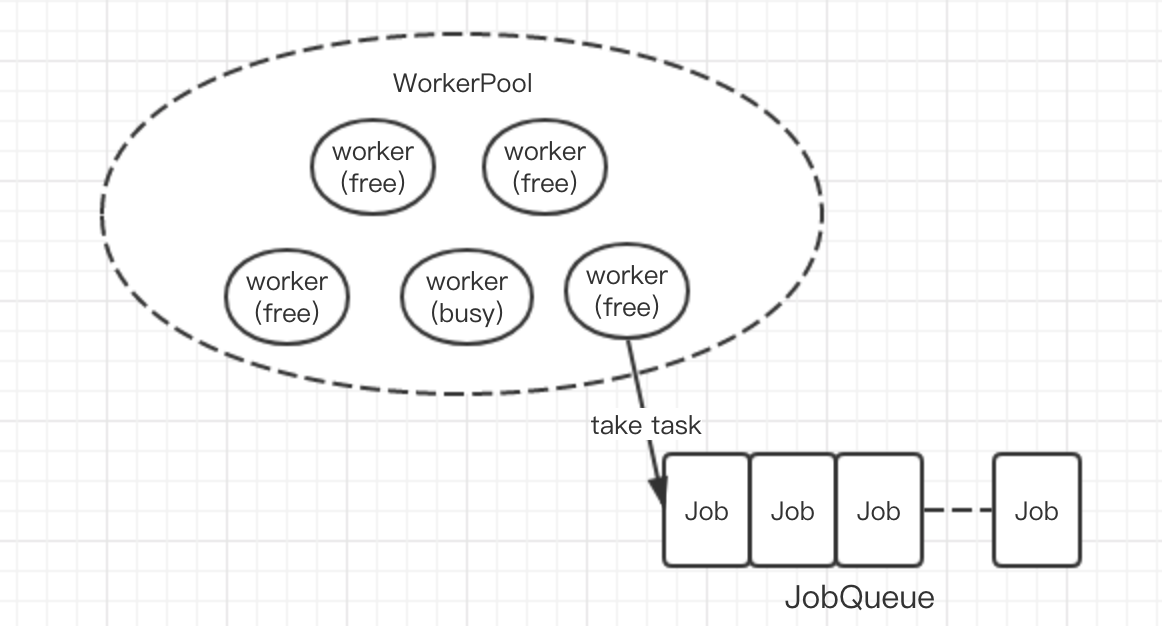
type Job struct {
Data interface{}
Proc func(interface{})
}
//Job队列,存储要做的Job
var JobQueue chan Job = make(chan Job, arg.maxqueue)
//Woker,用来从Job队列中取出Job执行
type Worker struct {
WokerPool chan chan Job //表示属于哪个Worker池,同时接收JobChannel注册
JobChannel chan Job //任务管道,通过这个管道获取任务执行
Quit chan bool //用来停止Worker
}
//新建一个Worker,需要传入Worker池参数
func NewWorker(wokerPool chan chan Job) Worker {
return Worker{
WokerPool: wokerPool,
JobChannel: make(chan Job),
Quit: make(chan bool),
}
}
//Worker的启动:包含:(1) 把该worker的JobChannel注册到WorkerPool中去 (2) 监听JobChannel上有没有新的任务到来 (3) 监听是否受到关闭的请求
func (worker Worker) Start() {
go func() {
for {
worker.WokerPool <- worker.JobChannel //每次做完任务后就重新注册上去通知本worker又处于可用状态了
select {
case job := <-worker.JobChannel:
job.Proc(job.Data)
case quit := <-worker.Quit: //接收到关闭信息,直接退出即可
if quit {
return
}
}
}
}()
}
//Worker的关闭:只要发送一个关闭信号即可
func (worker Worker) Stop() {
go func() {
worker.Quit <- true
}()
}
//管理Worker的调度器,包含最大worker数量和workerpool
type Dispatcher struct {
MaxWorker int
WorkerPool chan chan Job
}
//启动一个调度器
func (dispatcher *Dispatcher) Run() {
//启动maxworker个worker
for i := 0; i < dispatcher.MaxWorker; i++ {
worker := NewWorker(dispatcher.WorkerPool)
worker.Start()
}
//接下来启动调度服务
go dispatcher.dispatch()
}
func (dispatcher *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
go func(job Job) {
jobChannel := <-dispatcher.WorkerPool //获取一个可用的worker
jobChannel <- job //将该job发送给该worker
}(job)
}
}
}
//新建一个调度器
func NewDispatcher(maxWorker int) *Dispatcher {
workerPool := make(chan chan Job, maxWorker)
return &Dispatcher{
WorkerPool: workerPool,
MaxWorker: maxWorker,
}
}
解析:代码中每句都注释得非常清楚了,就不重复了。我们可以通过这样来开启这个模型:dispatcher := NewDispatcher(MaxWorker) dispatcher.Run()。有一点需要强调的是,处理函数这块需要根据自己的业务去写,然后和数据打包成Job再发给JobQueue就行了。接着我运行了我的脚本,几十G的文件经过三轮的处理函数(就是说我需要三轮处理,每轮处理都根据上轮的结果)耗时在三分钟到四分钟之间,而且CPU占用率等也不高。对于耗时高的,可以使用pprof工具分析一下到底慢在了哪里
四,总结
因为之前刚学了golang的并发原理,然后刚好有这个任务,于是自己就开始了从零一点点的摸索和优化,整个工具写完,自己对golang的并发的理解又更加的深入了,而且对锁,文件操作等也熟悉了起来。收获很多东西,所以我鼓励学习一个新东西,不能只懂原理,还要自己多动手一下,这样才牢固。其实这个模型还是存在一些不足之处,后续会继续优化。 期间也参考了一些很不错的博客,在这里也表示感谢。
