

摘要: 编解码模型提供了一种使用循环神经网络来解决诸如机器翻译这样的序列预测问题的模式。编解码模型可以用Keras Python深度学习库来进行开发,使用该模型开发的神经网络机器翻译系统的示例在Keras博客上也有描述,示例代码与Keras项目一起分发。该示例为用户开发自己的编解码LSTM模型提供了基础。
在本教程中,你将学会如何用Keras为序列预测问题开发复杂的编解码循环神经网络,包括:
- 如何在Keras中为序列预测定义一个复杂的编解码模型。
- 如何定义一个可用于评估编解码LSTM模型的可伸缩序列预测问题。
- 如何在Keras中应用编解码LSTM模型来解决可伸缩的整数序列预测问题。
教程概述
Keras中的编解码模型
可伸缩的序列问题
用于序列预测的编解码LSTM
Python环境
- 需安装Python SciPy,可以使用Python 2/3进行开发。
- 必须安装Keras(2.0或更高版本),并且使用TensorFlow或Theano作为后端。
- 需安装scikit-learn、Pandas、NumPy和Matplotlib。
这篇文章对搭建环境有一定的帮助: - 如何用Anaconda设置机器学习和深度学习Python环境
Keras中的编解码模型
编解码模型是针对序列预测问题组织循环神经网络的一种方法。它最初是为机器翻译问题而开发的,并且在相关的序列预测问题(如文本摘要和问题回答)中已被证明是有效的。
该方法涉及到两个循环神经网络,一个用于对源序列进行编码,称为编码器,另一个将编码的源序列解码为目标序列,称为解码器。
Keras深度学习Python库提供了一个机器翻译编解码的例子(lstm_seq2seq.py),作者在文章“十分钟简介:在Keras中进行序列学习”中进行了讲解。
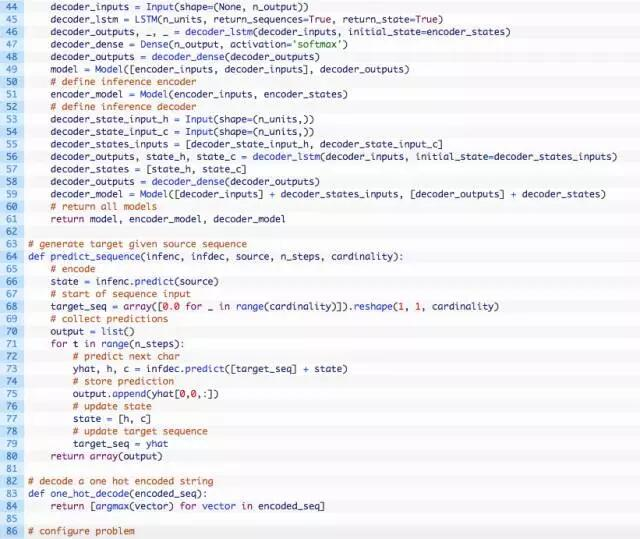
以该示例的代码为基础,我们可以开发一个通用函数来定义编解码循环神经网络。下面是define_models()函数。
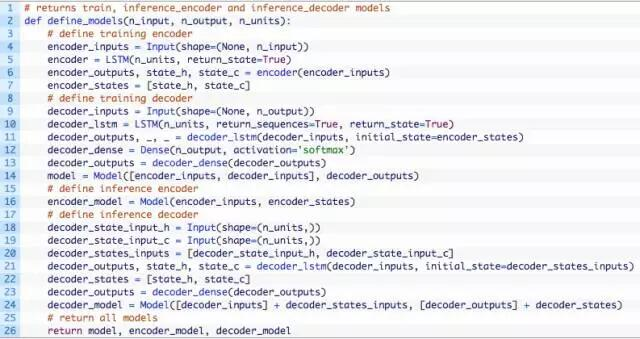
该函数有3个参数:
- n_input:输入序列的基数,例如每个时间步长的特征、字或字符的个数。
- n_output:输出序列的基数,例如每个时间步长的特征、字或字符的个数。
- n_units:在编码器和解码器模型中创建的单元的数量,例如128或256。
该函数创建并返回3个模型:
- train:给定源、目标和偏移目标序列进行训练的模型。
- inference_encoder:对新的源序列进行预测时使用的编码器模型。
- inference_decoder:对新的源序列进行预测时使用的解码器模型。
该模型对给定的源序列和目标序列进行训练,其中模型以源序列和目标序列的偏移作为输入,对整个目标序列进行预测。
该模型对源和目标序列进行训练,其中模型将目标序列的源和位移版本作为输入,并预测整个目标序列。
例如,源序列可能是[1,2,3],目标序列是[4,5,6],则训练时模型的输入和输出将是:
Input1: ['1', '2', '3']
Input2: ['_', '4', '5']
Output: ['4', '5', '6']
当为新的源序列生成目标序列时,该模型将会被递归调用。
源序列会被编码,同时,目标序列生成一个元素,使用类似于“_”这样的起始符来启动这个过程。因此,在上述情况下,训练过程中会生成以下这样的输入输出对:

这里,你可以看到递归是如何使用模型来构建输出序列。在预测过程中,inference_encoder模型用于对输入序列进行编码。然后,inference_decoder模型用于逐步生成预测。
下面这个predict_sequence()函数可以在模型训练完成之后根据给定的源序列生成目标序列。
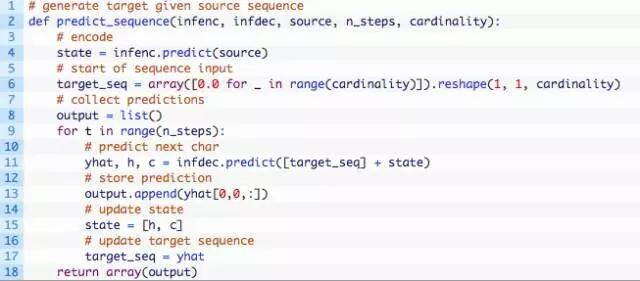
此函数需要5个参数:
- infenc:对新的源序列进行预测时使用的编码器模型。
- infdec:对新的源序列进行预测时使用的解码器模型。
- source:已编码的源序列。
- n_steps:目标序列中的时间步长数。
- cardinality:输出序列的基数,例如每个时间步长的特征、单词或字符的数量。
该函数返回包含目标序列的列表。
可伸缩序列问题
在本章节中,我们将提出一个可伸缩的序列预测问题。
源序列是一系列随机生成的整数值,例如[20, 36, 40, 10, 34, 28],目标序列是输入序列的反向预定义子集,例如前3个元素倒序排列[40, 36, 20]。源序列的长度可配置,输入和输出序列的基数以及目标序列的长度也可配置。我们将使用的源序列元素个数是6,基数是50,目标序列元素个数是3。
下面是具体的例子。

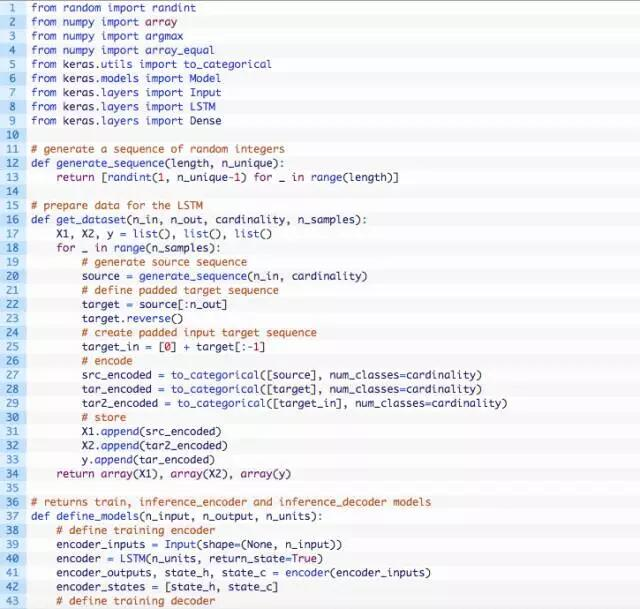
首先定义一个函数来生成随机整数序列。我们将使用0值作为序列字符的填充或起始,因此0是保留字符,不能在源序列中使用。要实现这一点,把1添加配置的基数,以确保独热编码足够大。
例如:
n_features = 50 + 1
可以使用randint()函数生成1和-1之间的随机整数。下面的generate_sequence()生成了一个随机整数序列。
# generate a sequence of random integers
def generate_sequence(length, n_unique):
return [randint(1, n_unique-1) for _ in range(length)]
接下来,创建一个与给定源序列相对应的输出序列。为了方便起见,把源序列的前n个元素作为目标序列并将其逆序排列。
# define target sequence
target = source[:n_out]
target.reverse()
我们还需要一个输出序列向前移动一个时间步长的版本,把它作为生成的模拟目标序列。可以直接由目标序列进行创建。
# create padded input
target sequencetarget_in = [0] + target[:-1]
现在,所有的序列已经定义好了,下面可以对它们进行独热编码了,即将它们转换为二进制向量序列。可以使用Keras内置的to_categorical()函数来实现这个。
可以将所有这些操作都放到get_dataset()这个产生指定数量序列的函数中。

最后,对独热编码序列进行解码,以使其可以再次读取。这不仅对于打印生成的目标序列是必需的,而且也可用于比较完全预测目标序列是否与预期目标序列相匹配。 one_hot_decode()函数将对已编码的序列进行解码。
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [argmax(vector) for vector in encoded_seq]
我们可以将所有这些结合在一起并进行测试。下面列出了一个完整的代码示例。

运行示例,首先打印生成的数据集的形状,确保训练模型所需的3D形状符合我们的期望。
然后将生成的序列解码并打印到屏幕上,展示一下源和目标序列是否符合我们的本意,以及正在进行的解码操作。
(1, 6, 51) (1, 3, 51) (1, 3, 51)
X1=[32, 16, 12, 34, 25, 24], X2=[0, 12, 16], y=[12, 16, 32]
下面将开发一个针对该序列预测问题的模型。
用于序列预测的编解码LSTM
在本章节中,我们将把第一节开发的编LSTM模型应用到第二节开发的序列预测问题上。
第一步是配置这个问题。
# configure problem
n_features = 50 + 1
n_steps_in = 6
n_steps_out = 3
接下来,定义模型并编译训练模型。

接下来,生成包含10万个样本的训练数据集并训练模型。

模型训练完成之后,就可以对其进行评估了。评估的办法是对100个源序列进行预测并计算目标序列预测正确的个数。可以在解码的序列上使用numpy的array_equal()函数来检查是否相等。
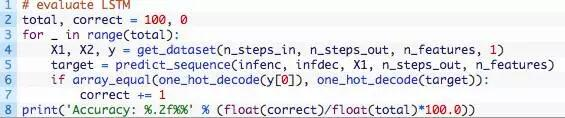
最后,示例将产生一些预测并打印出解码的源、目标和预测目标序列,以检查模型是否按预期的那样运行。
将上面所有的代码片段合在一起,完整的代码示例如下所示。
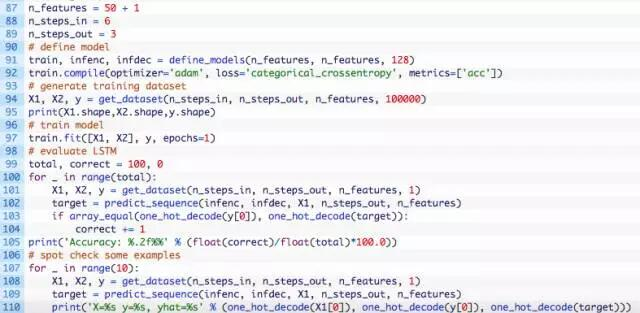
运行示例,首先打印准备好的数据集的形状。
(100000, 6, 51) (100000, 3, 51) (100000, 3, 51)
接下来,显示一个进度条,在一台现代多核CPU上的运行时间不会超过一分钟。
100000/100000 [==============================] - 50s - loss: 0.6344 - acc: 0.7968
再接下来,评估模型并打印准确度。 可以看到,该模型在新的随机生成的样本上实现了100%的准确度。
Accuracy: 100.00%
最后,生成10个新的例子,然后预测目标序列。 可以看到,模型正确地预测了每种情况下的输出序列,并且期望值与源序列颠倒的前3个元素相匹配。
X=[22, 17, 23, 5, 29, 11] y=[23, 17, 22], yhat=[23, 17, 22]
X=[28, 2, 46, 12, 21, 6] y=[46, 2, 28], yhat=[46, 2, 28]
X=[12, 20, 45, 28, 18, 42] y=[45, 20, 12], yhat=[45, 20, 12]
X=[3, 43, 45, 4, 33, 27] y=[45, 43, 3], yhat=[45, 43, 3]
X=[34, 50, 21, 20, 11, 6] y=[21, 50, 34], yhat=[21, 50, 34]
X=[47, 42, 14, 2, 31, 6] y=[14, 42, 47], yhat=[14, 42, 47]
X=[20, 24, 34, 31, 37, 25] y=[34, 24, 20], yhat=[34, 24, 20]
X=[4, 35, 15, 14, 47, 33] y=[15, 35, 4], yhat=[15, 35, 4]
X=[20, 28, 21, 39, 5, 25] y=[21, 28, 20], yhat=[21, 28, 20]
X=[50, 38, 17, 25, 31, 48] y=[17, 38, 50], yhat=[17, 38, 50]
现在,你就拥有了编解码器LSTM模型的模板了,你可以将其应用到你自己的序列预测问题上了。
总结
在本教程中,你学会了如何用Keras为序列预测问题开发复杂的编解码循环神经网络,具体一点说,包括以下几个方面:
如何在Keras中为序列预测定义一个复杂的编解码模型。
如何定义一个可用于评估编解码LSTM模型的可伸缩序列预测问题。
如何在Keras中应用编LSTM模型来解决可伸缩的整数序列预测问题。
