

本文从代码细节入手,一步一步分析Top-Calls,并且如何解决。
我们的Node程序都实在太慢了,完全看不出它所谓的性能优势。
基础工作
系统一般会受哪些方面影响?
对于一般的系统,性能问题主要会受以下几部分影响:
我们这次是从第一点:代码实现 的角度来狠扣细节,一块一块代码来修改
性能分析的一般步骤
根据以往的经验,分析性能问题的一般步骤:
- 使用性能测试工具(比如jmeter)来评估性能,得到一个基础值
- 使用Profiler工具来剖析哪块代码最耗时
- 针对最耗时的代码,做优化
- 重复上述三步,直到性能达到预期未知
从代码细节实现入手,解决性能问题的一般思路
这个其实是一个技巧性问题,可以持续总结
我们的基础工作
- 因为Node是单进程的,因此我们性能评估时,可以就先测试单个Node进程的;最终上线前,可以再起多个进程做整体的性能评估
- 因为我们也是HTTP服务,因此性能测试工具我们就采用jmeter
- Profiler工具,貌似只能选择v8-profiler,具体怎么使用可以执行Google,我比较偷懒,直接使用WebStorm里的 V8 Profiling
开始干活了 …
测试基准值
我们的Web框架是自己实现在自己实现了一套 依赖注入 机制的基础上,使用express作为基础的HTTP Server,差不多就是 SpringMVC for Node,取名为 guice-web V2。因此可以先做一个框架本身和express之间的性能对比:
| 性能指标 | guice-web V2 | express |
|---|---|---|
| QPS | 32 | 1390 |
这块express我加了几个所需要的中间件,因此性能结果比官方值低
得到这个性能查询结果让我很惊愕,guice-web V2性能竟然只有express的 1/43
不过没事,我们下面来看看性能究竟耗在哪儿了?
分析一:第一次V8 profiling结果分析
使用v8 profiling可以得到如下结果:
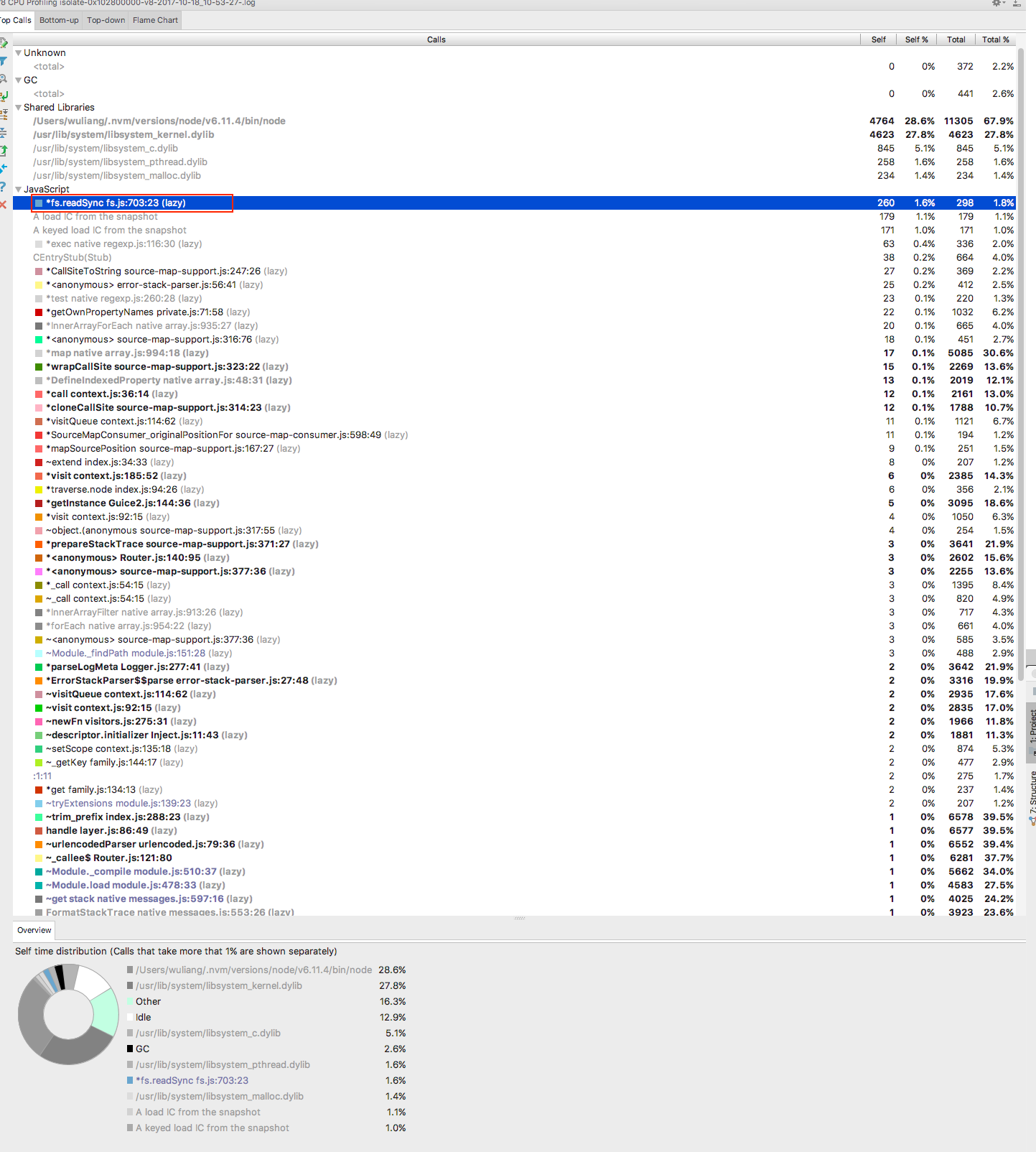
profiling结果会按函数的调用次数将代码中的函数从高到低排序,从这种图中可以看出,消耗我们最多的竟然是 fs.readSync;
这个结果让我很意外,因为我感觉代码中压根没有读文件的,尤其还是同步读文件的,但为啥会有这个结果呢?
继续看旁边的 Bottom-UP,这个是将函数整个调用栈从外到里的展示出来:
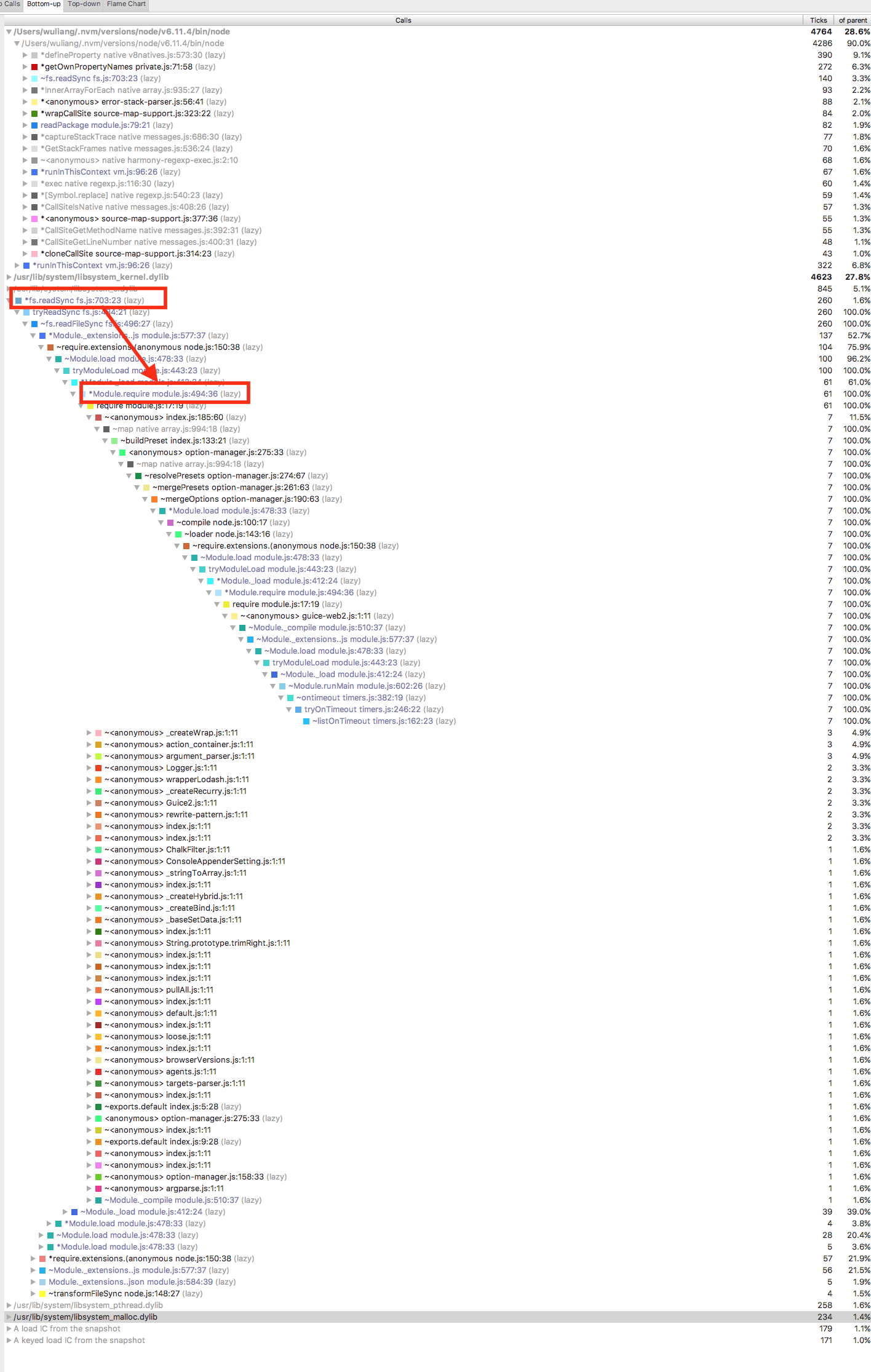
从上述这张图其实就可以比较方便地分析出来,其实是node的 require 调用的是 fs.readSync,于是我想起来了,==有些代码require没有写到文件的头部,而是写到函数内的== 。这个主要是我对Node模块的加载机制理解有问题,我以为Node编译时会把所有require语句都提前,但其实不会。
另外,写个demo再证明一下刚才说的逻辑:
// require在文件头部
require('http');
require('https');
require('child_process');
require('cluster');
require('fs');
require('crypto');
require('net');
require('events');
require('zlib');
require('util');
function f() {}
var startTime = new Date().getTime();
f();
var endTime = new Date().getTime();
console.log(endTime - startTime)
// 得到结果0// require在函数中
function f() {
require('http');
require('https');
require('child_process');
require('cluster');
require('fs');
require('crypto');
require('net');
require('events');
require('zlib');
require('util');
}
var startTime = new Date().getTime();
f();
var endTime = new Date().getTime();
console.log(endTime - startTime);
// 得到39这下彻底说明了问题了。
不过node本身会对require做缓存,应该虽然这块require被调用的次数多,并且还是同步IO的,但却成不了性能瓶颈。
我们接着往下分析
分析二:都是babel-register惹的祸
我们再看看刚才的Top-Calls,发现很多都是 source-map 什么的,这个是什么鬼?
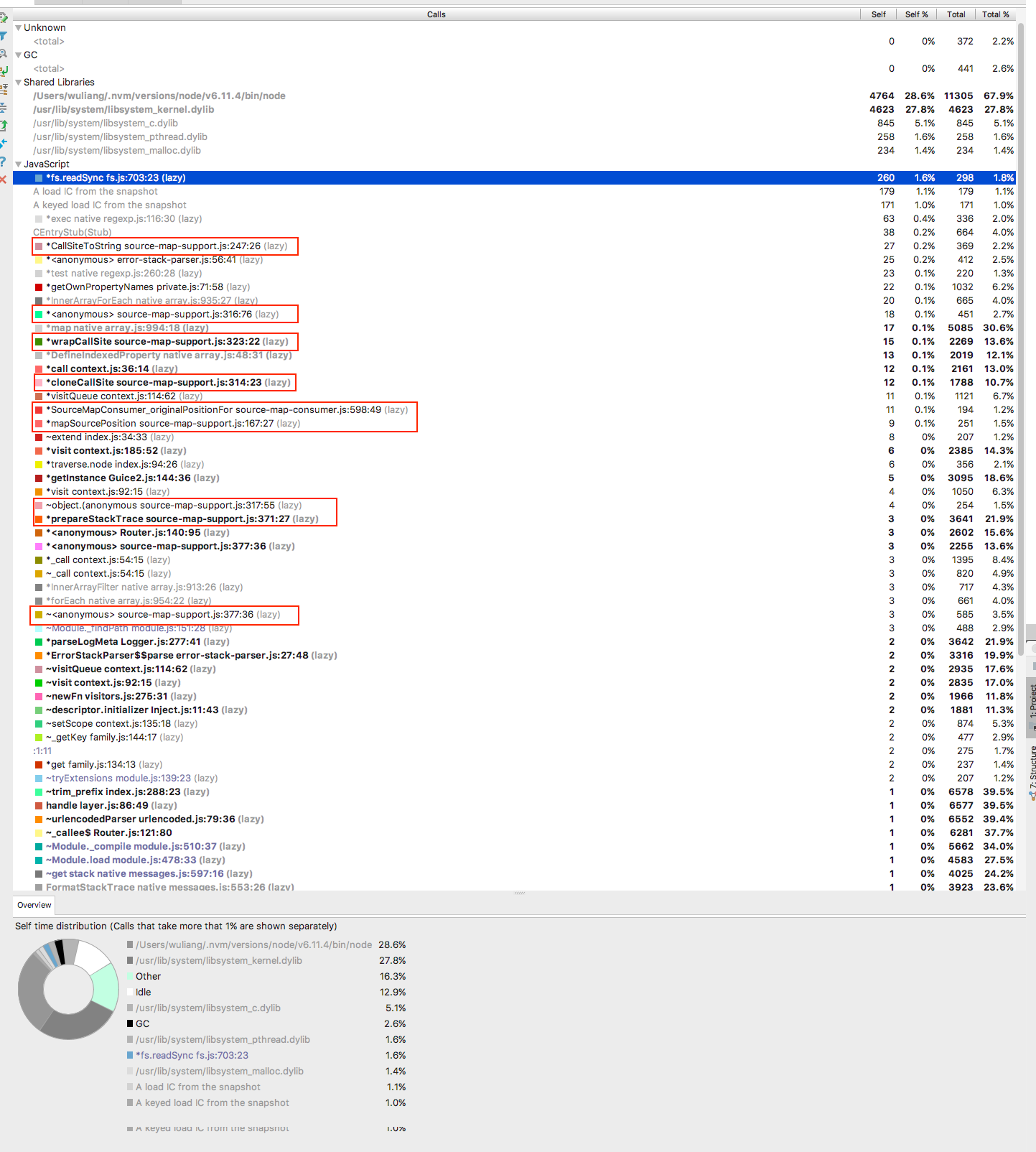
细想一下,于是明白了,因为代码大量使用了ES6/ES7的语法,依赖 babel 的转换,但为了之前开发方便,不想每次都编译,我直接在入口文件 require('babel-register')。原本想着其实没为啥,感觉反正是程序启动时babel就转换了所有文件,但忘了==它需要跟踪堆栈==了。于是把入口文件的require('babel-register')去掉后,babel转换后,测试babel转换后的性能,得到如下结果:
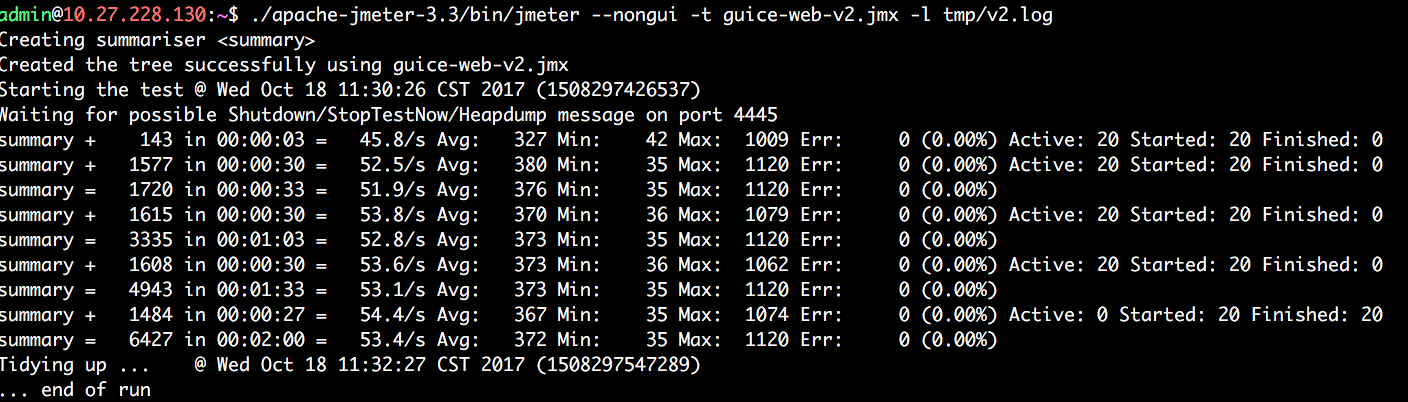
QPS直接从32提升到50+,提升快一倍了。
即使这样,比我预想得还慢很多,我的目标至少是 express 的一半。
分析三:真正的优化开始了,活用babel
以上两块分析和改动,都是很小的调优,没有涉及到系统本身的筋骨。我们继续分析:我们可以看到,top的是 error-stack-parser.js 这个文件,这个源于我引入的error-stack-parser。
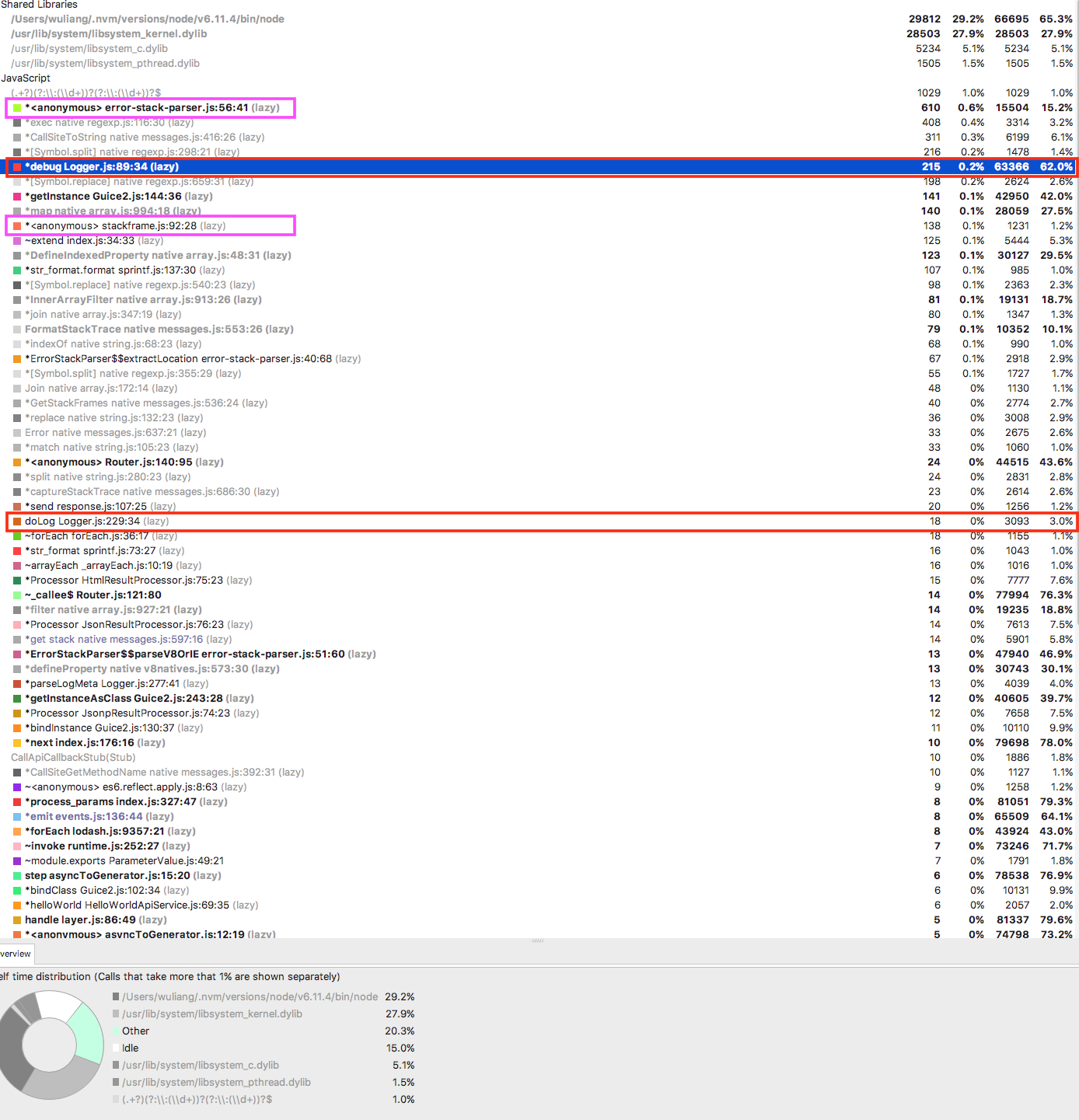
为什么我要引入这个依赖?
我写了一个日志输出模块,但日志输出模块中我期望的输出格式是:
日期(YYYYMMDD)LEVEL APP_NAME message (in fileName:lineNumber)
这其中日期(YYYYMMDD)、fileName、lineNumber都是变量,其中的fileName和lineNumber怎么获取?
参考baryon/tracer 中的做法,通过 (new Error()).stack 中来解析得到。另外,为了解析方便,我引入了error-stack-parser来方便解析,而error-stack-parser是使用正则表达式来解析,超慢的!!!
问题的原因是找到了,但如何解决?
最简单的办法当然是不输出fileName和lineNumber,但这个不是我想要的。
另外一个办法,自然是哪儿输入log,哪儿就传入fileName和lineNumber,node有__filename 这种预置变量,但却没__line 这种,并且,如果要求每个输出log的地方都要从logger.debug("msg")改成:logger.debug(__filename, __line, "msg"),其实也不太适合,没有logger模块是这么要求使用者的。
我想起以前写C++时,日志的输出都是封装成一个宏,比如:
#define LOG_INFO(format, args...) { \
logger->log(alog::LOG_LEVEL_INFO, __FILE__, __LINE__, __FUNCTION__, format, ##args);}那么我能不能也改成这般呢?
babel是个好东西,它可以让我们自创各种语法,于是我们可以利用babel,将代码从logger.debug("msg")改成:__LOG_DEBUG__(logger, "msg"),然后经过babel转换后,变成logger.debug({fileName: "filename", lineNumber: 12}, "msg")
下面我们来实现这个babel插件:
const path = require('path');
const LOG_PATTERN = /__LOG_(\w+)__/;
module.exports = ({types}) => {
const void0Expression = types.unaryExpression('void', types.numericLiteral(0), true);
let transformLog = (nodePath, state) => {
let calleeName = nodePath.node.callee.name;
let matched = LOG_PATTERN.exec(calleeName);
let methodName = matched[1].toLowerCase();
let filePath = path.resolve(state.file.opts.filename);
let startLineNumber = nodePath.node.loc.start.line;
let calleeInstance = "";
if (nodePath.node.arguments[0].type === "MemberExpression") {
calleeInstance = nodePath.node.arguments[0].object.name + "." + nodePath.node.arguments[0].property.name
}
else {
calleeInstance = nodePath.node.arguments[0].name;
}
let calleeExpression = types.identifier(calleeInstance + "." + methodName);
let logBasic = types.identifier(JSON.stringify({
lineNumber: startLineNumber,
fileName: filePath
}));
let calleeArguments = [
logBasic
];
for (const arg of nodePath.node.arguments.slice(1)) {
calleeArguments.push(arg);
}
let joinedCallExpression = types.callExpression(calleeExpression, calleeArguments);
nodePath.replaceWith(joinedCallExpression);
};
return {
visitor: {
CallExpression: function(nodePath, state) {
let calleeName = nodePath.node.callee.name;
if (LOG_PATTERN.test(calleeName)) {
transformLog(nodePath, state);
}
}
}
};
};经过这个插件转换:
__LOG_DEBUG__(self.logger, 'got instance: %s', name);转成成了
self.logger.debug({"lineNumber":224,"fileName":"/Users/wuliang/zone/node-guice/src/v2/Guice2.js"}, 'got instance: %s', name);好了,我们再测试一下性能:
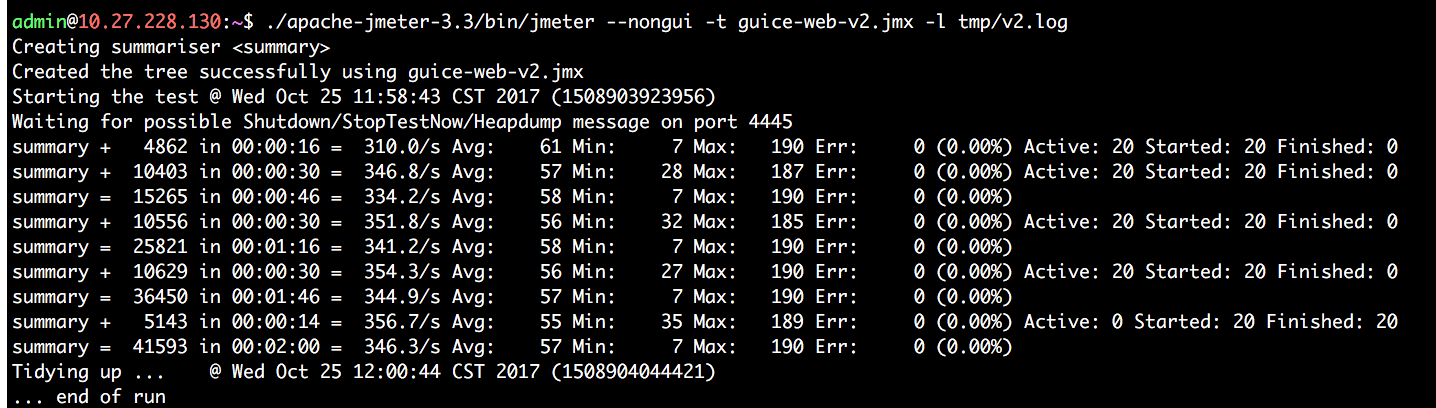
==QPS基本上达到300+,比之前提升了10倍了==。
分析四:map vs object
上述的性能测试结果非常可喜,但距离我的目标还有很大距离,我们继续分析 Top-Calls。我们可以看到,除了logger外,另外一个消耗大头就是Guice2.js中的getInstance,这个是因为我整个框架重度依赖我自己写的依赖注入框架Guice,而这个getInstance是其中取对象的方法。
在这个依赖注入中,有一个instancePool是保存所有绑定信息,另外一个instanceCache是缓存对象的,以便实现Singleton。之前这两个属性都是普通的object:{},那我们就拿这个{}入手,改成Map试试性能。
在jsperf有一个关于map和object的性能对比测试,大家可以跑一下看看:es6-map-vs-object-properties。从这上面可以看出,Map还是有一定性能优势的,于是我们把instancePool和instanceCache都改成Map
测试一下性能,还是挺可喜的:
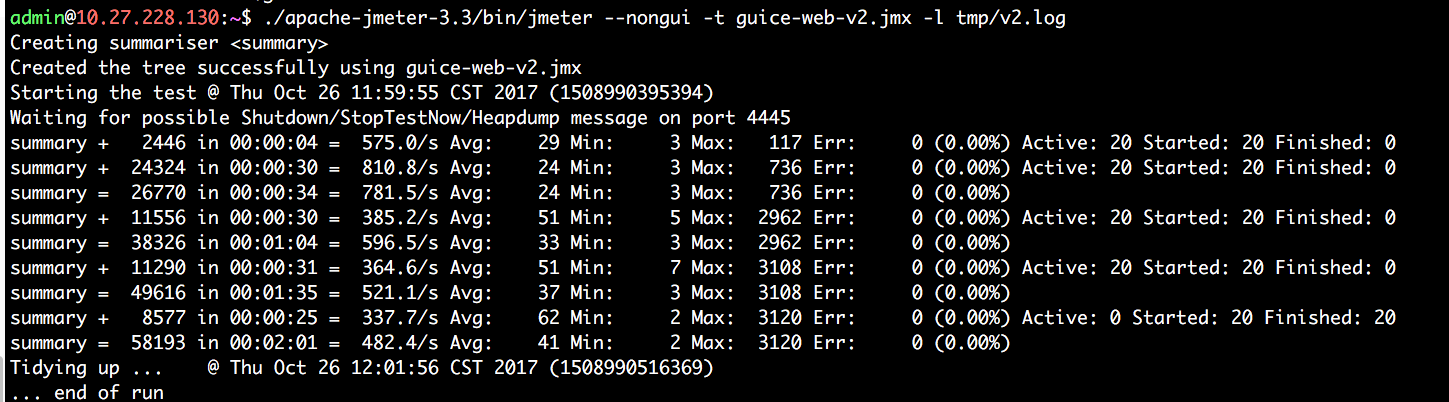
==性能明显比之前提升了不少,最低时刻也和上一个场景持平,顶峰竟然可以到800+了==
分析五:努力争取将各个函数都优化到极致
到了上述成果后,我整体性能排查到了一定的瓶颈,感觉大头都已经优化了,那么我们就看看细节上还有那些可以优化的
细节优化一:没必要Node环境上加载针对es5/6/7的polyfill
因为我们的不少基础模块都是可以跨平台(Node和浏览器)使用的,因此为了解决浏览器兼容性问题,都引入了es5-shim、es6-shim、es7-shim。理论上这些polyfill都会根据运行环境来觉得是不是要polyfill;但下面这个结果颠覆了我:
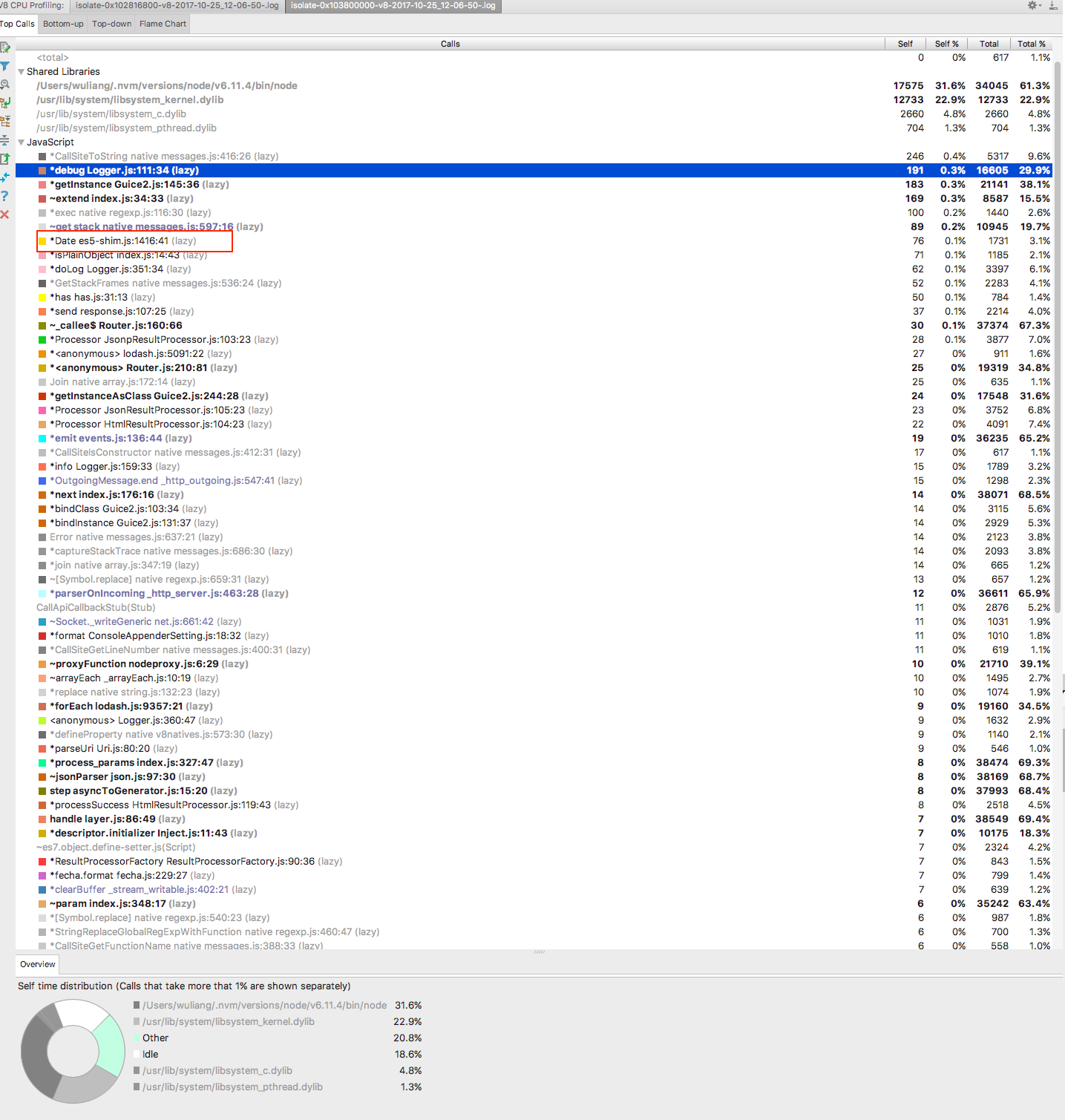
竟然使用了es5-shim里面的Date!
看一下es5-shim中的实现,es5-shim.js:1413,可以看到它有个doesNotParseY2KNewYear || acceptsInvalidDates || !supportsExtendedYears的判断,那我估计连Node都不符合它对Date的定义吧。
解决办法倒好办,在Node环境上,果断放弃es5-shim、es6-shim、es7-shim
细节优化二:Date的格式化输出
这块有两个点可以优化:
new Date().getTime()vsDate.now()- Date格式化的库的选择
new Date().getTime()vsDate.now()
这块在jsperf已经有了TestCase:date-now-vs-new-date,一跑就可以看出,Date.now()的性能优势相当明显
Date格式化的库的选择
Date格式化的选择真的非常多,比如moment、比如比moment小巧很多的fecha,
我之前都是采用fecha的,但经过性能测试下来,最后选择了带缓存的speed-date。
为什么呢?
因为我这边对Date的格式化主要是在输出请求的originalUrl上,并且我们的系统流量非常大,因此缓存同一时间的格式化阶段收益就比较明显了。
细节优化三:字符串拼接的优化
因为一个曾经的C++开发,对sprintf的偏好可能是与生俱来的。因此我其实并不喜欢直接的string相加,或者es6中的template literals。
其实Node已经自带util.format方法了,但我之前竟然一直忽略了这个方法,而使用了alexei/sprintf.js,但后来发现,竟然还是util.format最快,可以看如下的性能结果:

另外,这块其实还有一个小优化点,经过babel转换后的代码,有些代码是这般的"ke" + "ys",这块我加了一个babel插件:laysent/babel-plugin-transform-string-join来针对这种情况进行优化,直接让它变成:"keys"
细节优化四:针对生产环境的一些优化
比如在我的日志库中,我们对日志的date、level等信息都做了彩色输出(写JS都就可以搞这些,呵呵);但彩色输出其实在生产环境没啥用,因为生产环境日志都是写到一个文件中的,一般的模块都会做istty的判断,以决定要不要彩色输出。因此这个判断在生产环境上就成了一个负担。
解决办法:加一个启动时的环境变量,比如NODE_ENV=production,来屏蔽这个彩色输出。
细节优化点五:一些基本原则
剩余一些基本的原则,和Node无关:
- 把能提前初始化的变量尽量以前初始化,虽然浪费点内存
- 把函数中跳出判断尽量提前
分析六:express相关
有一个隐含的优化点突然被我发现,因为我们对所有请求头都加上了CORS,之前的代码是:
app.use(function (request, response, next) {
response.header(
'Access-Control-Allow-Origin',
request.headers.origin
);
response.header(
'Access-Control-Allow-Headers',
'Content-Type, Access-Control-Allow-Headers, Authorization, X-Requested-With'
);
response.header(
'Access-Control-Allow-Methods',
'GET,HEAD,POST,PUT,DELETE,OPTIONS'
);
response.header('Access-Control-Allow-Credentials', 'true');
next();
});当我改成:
response.header({
'Access-Control-Allow-Origin': request.headers.origin,
'Access-Control-Allow-Headers':
'Content-Type, Access-Control-Allow-Headers, Authorization, X-Requested-With',
'Access-Control-Allow-Methods':
'GET,HEAD,POST,PUT,DELETE,OPTIONS',
'Access-Control-Allow-Credentials': 'true'
});
next();性能竟然又提升了不好,经过上述分析五和分析六的优化,最终测试结果:
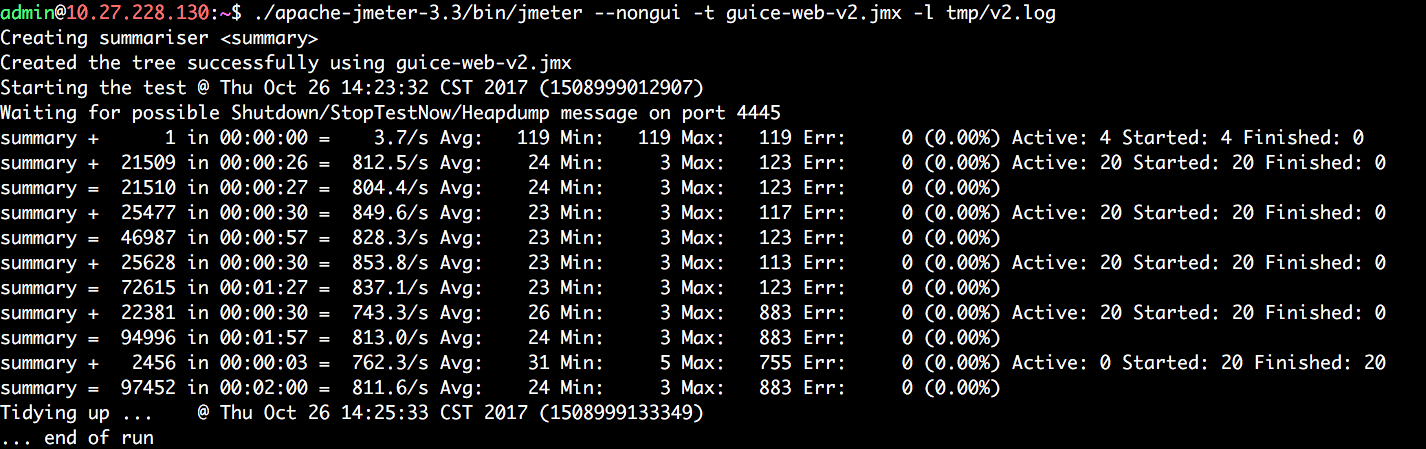
上述这图只是某些点的QPS,我分析jmeter的日志,==QPS达到: 680,已经比之前的32倍==,成果杠杠的!
分析六:明明说是40倍,为啥才是32倍呢?标题党?
我这边对比的框架guice-web已经我们的2.0版本,但目前我们线上用的还是1.x版本,1.x版本的QPS只有17,比2.0版本还慢不少,因此==从1.x版本的17到2.0版本的32到经过优化后的680,40倍的差距啊==
我们的1.x版本和2.0版本优化了哪些?
涉及性能的点有:
- 1.x版本大量使用了kriskowal/q作为Promise库,但经过profiling分析,这个库性能实在不咋地
- 不盲目使用promise:之前为了通用,大量方法都使用了promise,但事实上,这种做法过于盲目,非常影响性能,还是应该合理使用
- 也不要盲目使用
process.nextTick:这个也一样,因为它会把任务放到下一个轮询上去了,盲目使用,就会造成明明这会可以做的事情,却偏偏往后才做,并且因为你无法预估队列中的任务的时间消耗。
总结
这块我们就针对代码中的诸多细节做了优化,总结一下包含以下几个点:
- 尽可能少用正则表达式:v8对正则表达式的执行那是相当慢,后续我想试试看,写个语法解析器来替代正则表达式,可能会快点
- 活用转换和编译
- 选择适合的数据结构
- 对依赖库的选择要做好调研
- 合理使用promise和
process.nextTick,能不放到下一个时间轮询中就尽量不那么做
其实可以做优化的点还很多(比如for … of 中await的问题),后面我们再继续总结。
