

备注:本文编译自iOS 11 by系列教程(http://raywenderlich.com)
前言
在刚刚过去的苹果十周年iPhone发布会上,除了Steve Jobs Theatre,可能大家印象最深刻的就是iPhone X的面部识别(face id)功能了。关于face id,网上已经有了无数条关于用“刷脸”来买买买的段子。

当然,要实现这种神奇的“刷脸”功能,除了iphone x“留海“部分的多个摄像头和传感器之外,相关的软件算法也是必不可少的。
在本教程中,我们将了解苹果iOS11中除了ARKit之外的极具前瞻性的框架,也即Core ML和Vision框架,并通过一个示例来讲解如何利用Core ML和Vision框架来实现人脸识别。
需要提醒大家的是,iPhone X的强大“刷脸”功能是软硬件完美结合的表现,这也是苹果一贯的风格。我们使用Core ML和Vision可能没法实现那种魔术般的效果,但也是非常值得去探索的。
人类都是视觉动物。根据Time杂志的统计,2016年的Top10非游戏类应用中,有7个跟图片和/或视频分享有关(美国排行榜)。其中的一些应用,诸如Facebook,Snapchat和Instagram等,给用户提供了丰富多彩的图像相关功能,比如图像校正、添加滤镜、面部识别等等。
在iOS11中的全新Vision框架基于Core Image和Core ML框架构建,并且提供了几个简单易用的功能,用于分析图片和视频。它具体支持的特性包括面部跟踪,面部识别,面部特征点,文本检测,矩阵检测,二维码检测,物体跟踪,以及图像登记等。
在本章的内容中,我们将学习如何检测人体面部,学习面部特征点,以及如何使用Vision和Core ML来给场景分类。
开始前的准备
在开始学习之前,请确保已经安装了Xcode9的正式版(9月13日已从beta版升级为正式版,同时开发者版本的iOS也已经推送了GM版)。
使用Xcode打开本章的起始项目:GetReady。
项目地址:链接:http://pan.baidu.com/s/1bpD7DAv 密码:35fb
这个项目的作用是查看你的照片,然后为不同的场景对家人和朋友做一些装饰。这些场景包括徒步旅行,以及去海滩度假。对于徒步旅行的场景,我们可以给家人和朋友戴上游客的帽子,而对于海滩晒日光浴的场景则戴上太阳镜。
关于图片细节的视图控制器ImageViewController.swift这个文件将是本教程的学习重点。
编译运行应用,此时我们会看到一个空白的屏幕。点击右上角的“+”按钮可以打开照片选择器。
注意:如果在打开照片选择器的时候看到console里面出现一些警告或log信息,大可以忽略。
如果你使用的是iOS模拟器,那么会预加载一些漂亮的花朵和瀑布。但是因为本教程主要涉及人脸,因此这些用处不大。不过好在iOS 11模拟器允许我们添加图片!
我们可以用自己的照片,或者直接从GetReady\images文件夹中找到hiker.jpg文件,然后将其拖到Photos应用中。这样它就被导入到Simulator中,从而在应用中可用。
注意看这里的“留海”造型,因为我在模拟器里面选的是iPhone X~
而且这个模拟器里面是没有Home键的,那么想返回到Simulator主界面怎么办呢?只需要从最下方往上拖动,就可以回到桌面了。想来这也是iPhone X设备上的正式操作吧,有点小期待。
好了,现在返回这个应用,点击右上角的加号,选择刚才的新照片。此时这个照片将以缩略图的形式显示在屏幕上。
点击(模拟器)缩略图,图片将会放大显示,而这里也将是对图片作出修饰的视图控制器。

照片里面的哥们看起来很享受这个徒步之旅,但是好像漏掉了一些什么。是的,他sans chapeau(法语-没有帽子)!让我们给这哥们送一顶帽子,来保护他此刻光芒万丈的秃头!
面部检测
为了找到添加帽子的合适位置,我们需要找到照片中每个头部的尺寸。幸运的是,Vision很擅长的一件事情就是识别面部的基本轮廓。
注意:Core Image中的CIDector同样可以用于识别照片中的人脸。不过新的Vision提供了更为强大的面部识别功能,而且可以识别相对更小的面部,侧脸,被物体、帽子和眼镜挡住的脸。当然,不太好的地方就是Vision的速度相对较慢,而且需要更强大的计算性能,也更耗电?
对于本教程的第一部分,我们的目标是给照片中所识别出的每个人体头部绘制一个游客帽子。而在后续的内容中,我们将基于更多的数据信息来调整帽子的朝向,同时给海滩上享受日光浴的人们戴上太阳镜。
面部轮廓检测
在Xcode中打开ImageViewControlller.swift,替代其中的viewWillAppear(_:)方法如下:
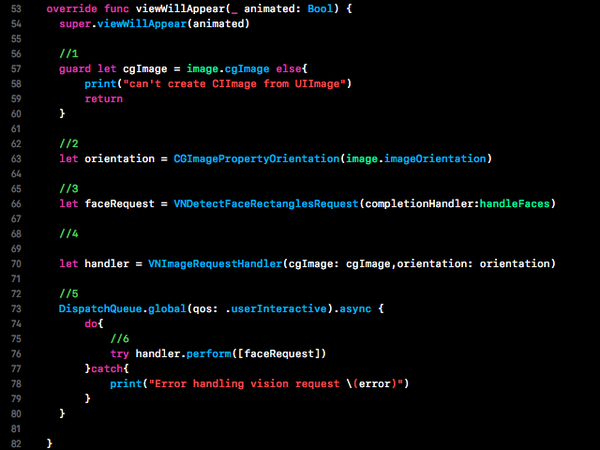
以上代码完成了对Vision API的调用:
1.Vision不适用于UIImage,而是对图片的原始数据,像素缓存,CIImage或CGImage有效。
2.设置了orientation属性,从而确保所检测的轮廓与图片是同一方向的。
3.这行代码创建了一个面部检测请求。这里的completion handler是一个类实例方法,很快我们将实现它。
4.我们需要一个图片请求的handler来处理单一图片的一个或多个请求。
5.Vision请求可能或耗费一些时间,因此最好是在背景队列中执行。
6.perform(-:)获取了请求列表,并执行面部检测的任务。在检测过程的最后,将从背景队列中触发请求调用。
Completion handler
正如其名字所表示的,VNDectectFaceRectangleRequest用于发现图片中的面部轮廓。Vision请求将调用所检测物体数组的completion handler。
找到handleFaces(request:error:)方法,并使用以下代码替换:
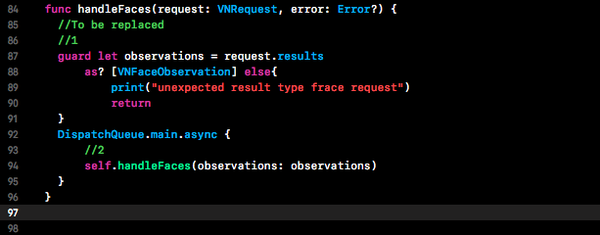
以上代码完成了以下任务:
1.确认请求返回了有效的VNFaceObservation元素的results数组。
2.将真正困难的工作交给main队列中的另一个函数。
当然这个函数目前还没有定义,因此Xcode肯定会提示出错的。为了解决该问题,我们需要在刚才的handleFaces():方法之后添加一个新的observation-handling方法:
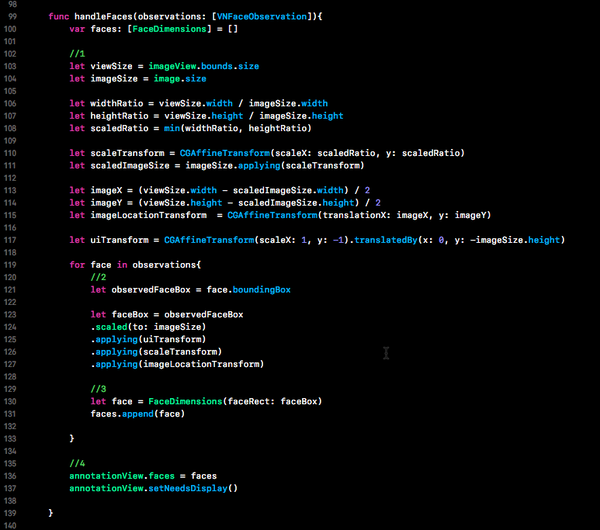
以上方法遍历了所有的observations,并从进行面部检测的图片中变换坐标和定义区域。
1.这里我们确定了image view视图中图片的真实边界。因为image view的内容填充模式是Aspect Fit,因此会自动缩放以满足image view的至少一个维度大小。也就是说另外一个维度就无法与image view的坐标对齐。如果选择另一种模式,比如Scale to Fill,可以简化这个计算过程,但是看起来效果就不太好了。
2.对每个observation,我们都需要将其坐标转换到imageView的坐标。
3.我们将面部轮廓封装到一个定制的FaceDimensions结构中,并将其添加到一个数组中。该结构的作用是在应用中传递面部数据。
4.最后,我们需要将所有的面部数据添加到annotationView之中,后面将用它在原始图片上绘制自定义的图片。
之所以需要第二步,是因为observation的boundingBox是在Core Graphics的坐标系中正交化的,其原点位置在左下角。当我们需要在某个视图上开始绘制之前,需要对bounding box做以下操作:
1.进行denormalize操作,使其符合输入的图片大小。
2.将其移入UIKit的坐标系
3.将其缩放到绘制的长宽比
4.将其转换到图片在image view中的位置。
在继续学习之前,我们先让以上代码可以正常运行。
打开annotationView.swift,然后更改drawDebug变量的值为true,具体如下:
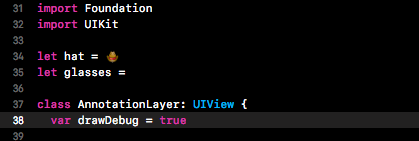
这样一来,就将在所识别的脸部绘制绿色的方框。
编译运行程序,然后选择一个照片,很快我们就会在所有识别出的面部看到一个绿色的方框。

当然,我承认这里用iOS11 Simulator主要是想体验下iPhone X的操作。那么在我的iphone 6s Plus上是否可以正常运行呢?
我找了两张昨天发布会上的照片,发现识别速度还是可以的,不过遗憾的是Tim Cook在帮主光芒万丈之下没被认出来,当然,这个我这个照片中Cook本身很模糊也有关系。


所以说,Core ML和Vision框架的强大威力还是值得信赖的。
敬请期待下一部分内容,我们将给识别出来的人脸加上一些装饰品~
