

视频教程的总结和一些自行补充的内容,旨在尽可能的理解其原理。
本文持续更新地址:个人博客机器学习面试基础知识 & 扩展-01
训练/开发/测试集
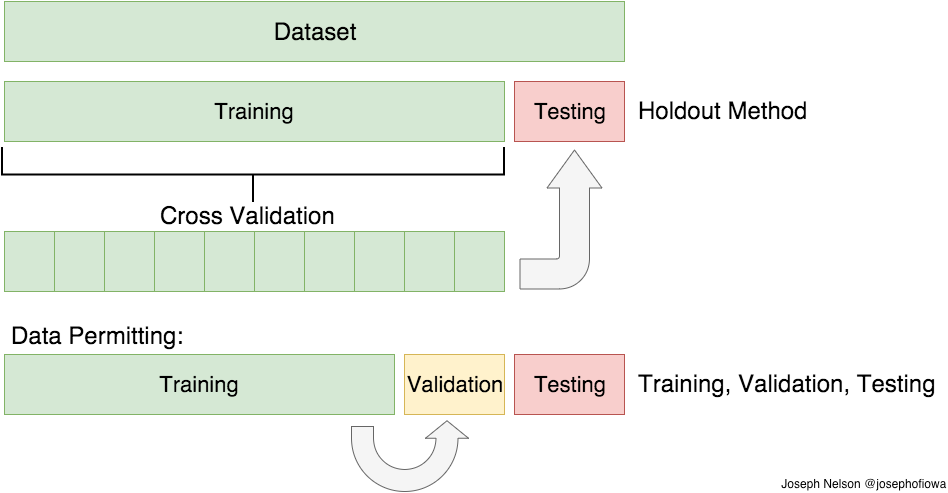
Tips
- 训练/开发/测试集经验比例 6:3:1
- 当数据量超过百万时,测试集只需约1w(也就是不需要严格按照比例增长)
- 严格保证分层取样
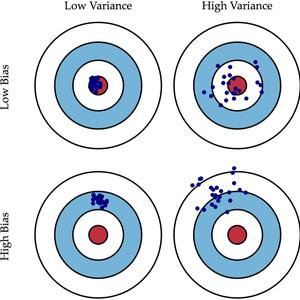
偏差(Bias)/ 方差(Variance)
在忽略噪声的情况下,泛化误差可分解为偏差、方差两部分。
- 偏差:度量学习算法的期望预测与真实结果的偏离程度,也叫拟合能力。
- 方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动造成的影响。
---摘自《机器学习》,周志华
分类器
| Train set error | 1% | 15% | 15% | 0.5% |
|---|---|---|---|---|
| Dev set error | 10% | 16% | 30% | 1% |
| status | high variance | high bias | high bias & high variance | low bias & low variance |
- 偏差:模型的预测误差率(训练集中的准确率越大,偏差越大)
- 方差:模型的泛化能力(开发集中的表现和训练集的差距大小,差距越大,代表方差越大)
high Bias 意味着模型的分类效果不好,high Variance 意味着模型往往过拟合,不能很好的泛化。
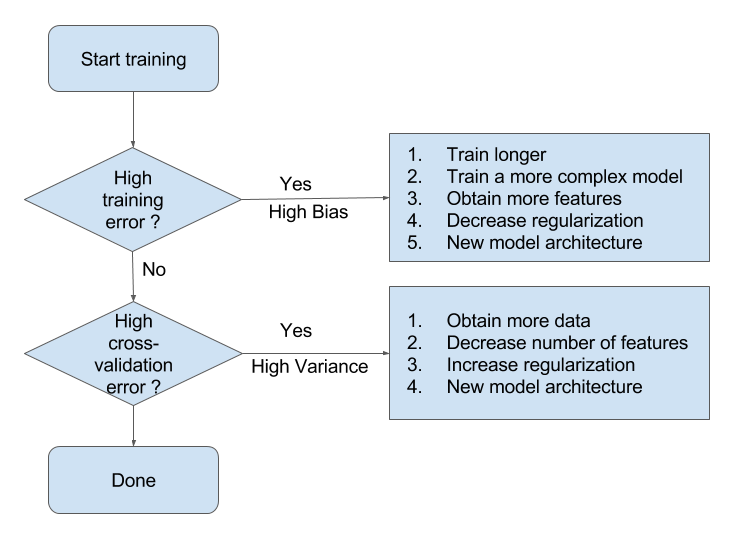
我们通常这样利用这两个参数调整我们的神经网络,其中部分内容会在本文的后面进一步探讨。
梯度消失与梯度爆炸
欠拟合和过拟合
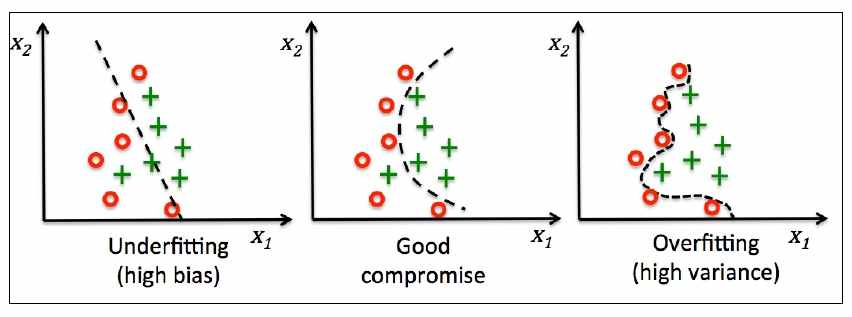
上图从左到右分别是欠拟合、合适的拟合和过拟合三种情况。
过拟合
过拟合是如何产生的?
- 根本原因:参数太多,模型复杂度过高,同时数据相对较少,或噪声相对较多。
整个训练过程其实是模型复杂度和过拟合之间的一个权衡,如下图
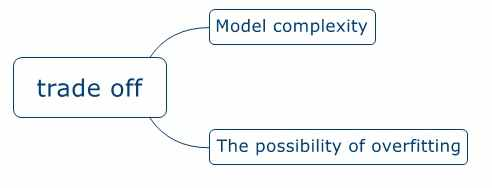
如何应对过拟合?我之前的一篇译文提到过:译文
如何应对过拟合?
结合前文中提到的偏差和方差,我们有以下经验:
也就是:
- 增大训练数据量 - 最有效的方案
- Cross Validation - 数据量不足的情况下常用
- Early Stopping - 提早结束训练过程
- 正则化(
regulation)- 主要是L1和L2正则化 - 采用
Dropout- 随机将某些神经元的权重初始化为零
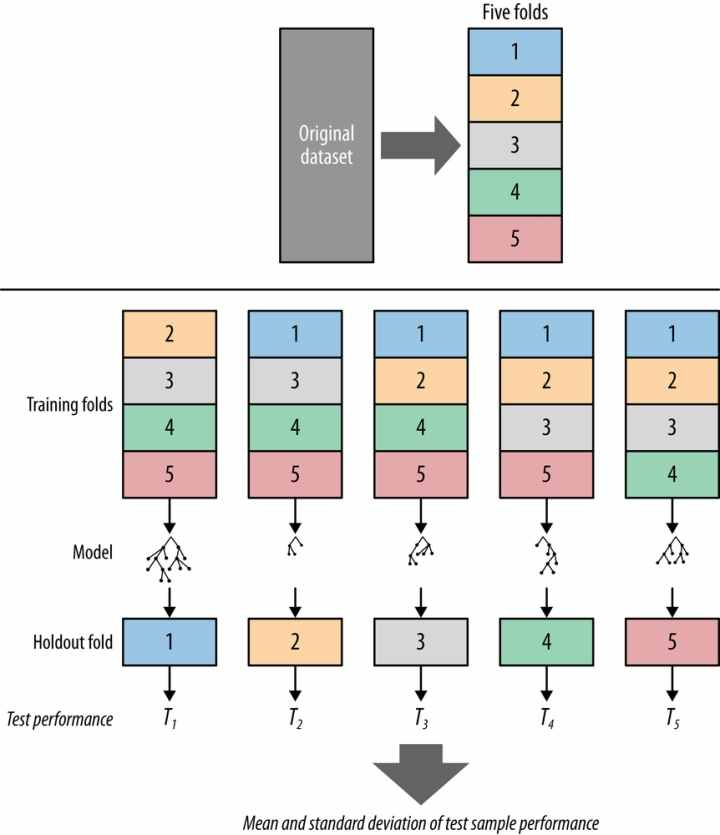
Cross Validation
回到交叉验证,根据切分的方法不同,交叉验证分为下面三种:
简单交叉验证
所谓的简单,是和其他交叉验证方法相对而言的。首先,我们随机的将样本数据分为两部分(比如: 70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,我们再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
S折交叉验证
又称(S-Folder Cross Validation),和第一种方法不同,S折交叉验证会把样本数据随机的分成S份,每次随机的选择S-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择S-1份来训练数据。若干轮(小于S)之后,选择损失函数评估最优的模型和参数。
留一交叉验证
又称(Leave-one-out Cross Validation),它是第二种情况的特例,此时S等于样本数N,这样对于N个样本,每次选择N-1个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况。
早停法(Early Stopping)
为了获得性能良好的神经网络,网络定型过程中需要进行许多关于所用设置(超参数)的决策。超参数之一是定型周期(epoch)的数量:亦即应当完整遍历数据集多少次(一次为一个epoch)如果epoch数量太少,网络有可能发生欠拟合(即对于定型数据的学习不够充分);如果epoch数量太多,则有可能发生过拟合(即网络对定型数据中的“噪声”而非信号拟合)。
早停法背后的原理其实不难理解:
- 将数据分为定型集和测试集
每个epoch结束后(或每N个epoch后):
- 用测试集评估网络性能
- 如果网络性能表现优于此前最好的模型:保存当前这一epoch的网络副本
将测试性能最优的模型作为最终网络模型
最优模型是在垂直虚线的时间点保存下来的模型,即处理测试集时准确率最高的模型。
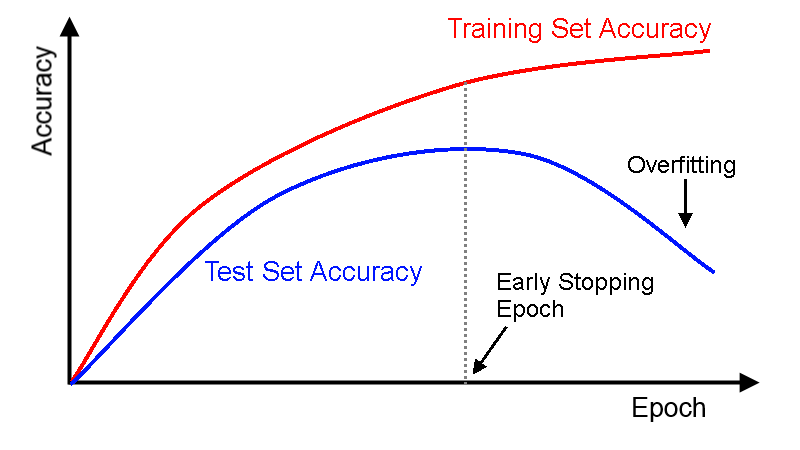
其中,停止条件可以是下面这三条
- 权重的更新低于某个阈值的时候
- 预测的错误率低于某个阈值
- 达到预设一定的迭代次数
正则化
正则化 是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或惩罚项(penalty term)
一般来说,监督学习可以看做最小化下面的目标函数:
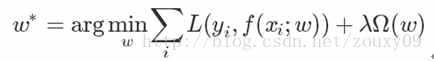
- 作用: 英文是
regulation,字面意思是调整修正,也就是调整上图中出现应对过拟合 - 常见种类: L0、L1、L2
L0范数
L0范数表示向量中所有非零元素的个数
定义:
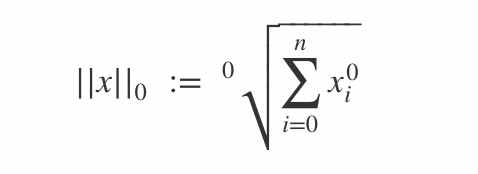
L1范数
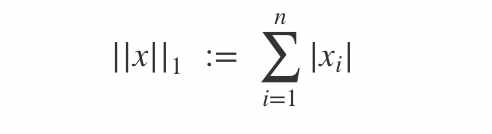
L2范数
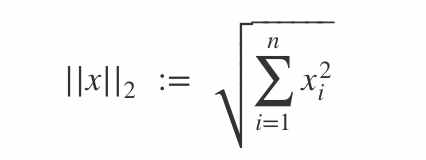
定义:L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0。
- L2范数如何减少过拟合?
使部分神经节点w的权重降低为零,从而简化网络,将上图中图3中转换为图1,结果是variance降低,bias增加。
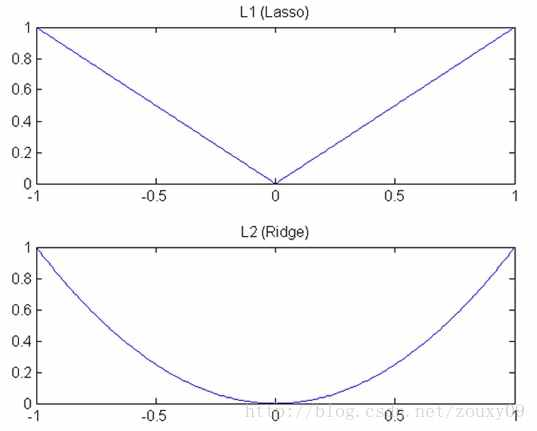
L1 / L2范式的区别
下降速度
模型空间的限制
视频讲解: 2:30
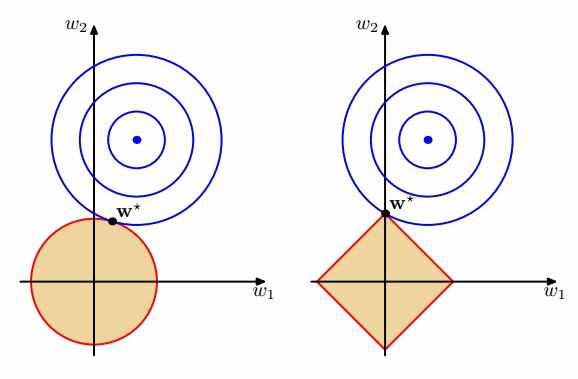
优化问题:把 w 的解限制在黄色区域内,同时使得经验损失尽可能小。
这也导致L2相对较为稳定,L1可以产生更多稀疏解。
Dropout
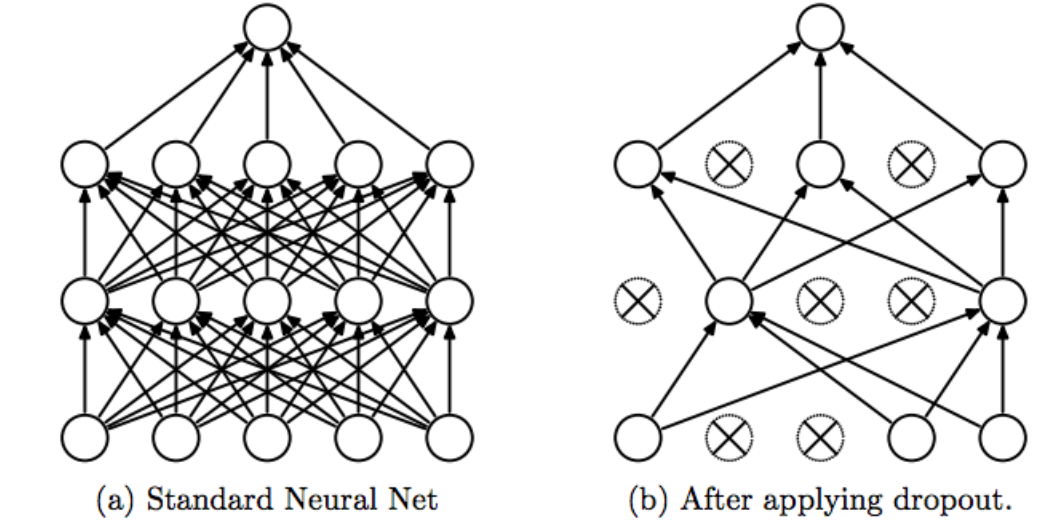
Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。
Experiment in Keras
基于 CIFAR-10 dataset 的实验
结果演示:
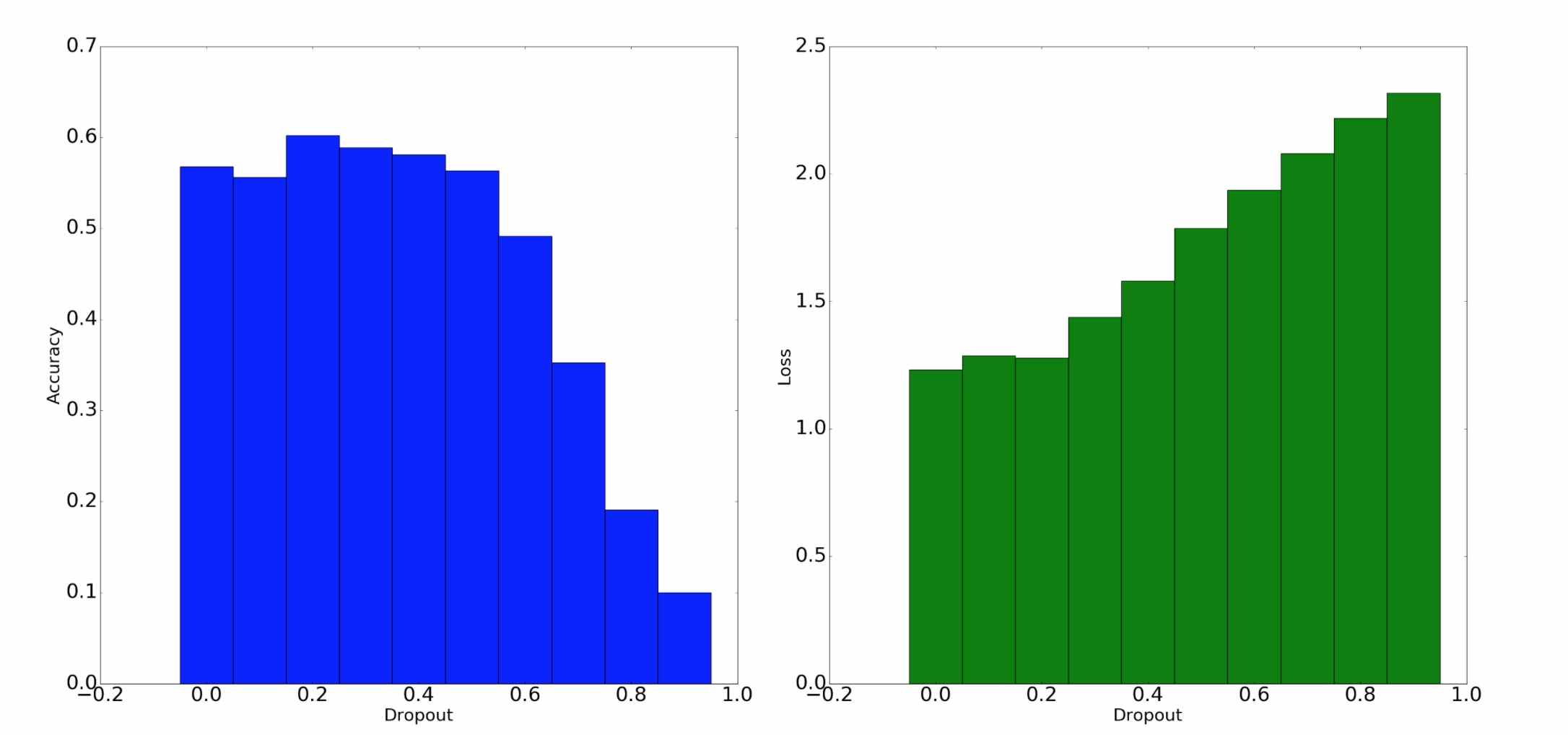
分析:dropout等于0.2的时候效果最佳
代码:Github
示例演示
代码演示
100代码的简单神经网络代码:pycharm
关于激活函数作用的直观解释:知乎回答:异或
可视化演示
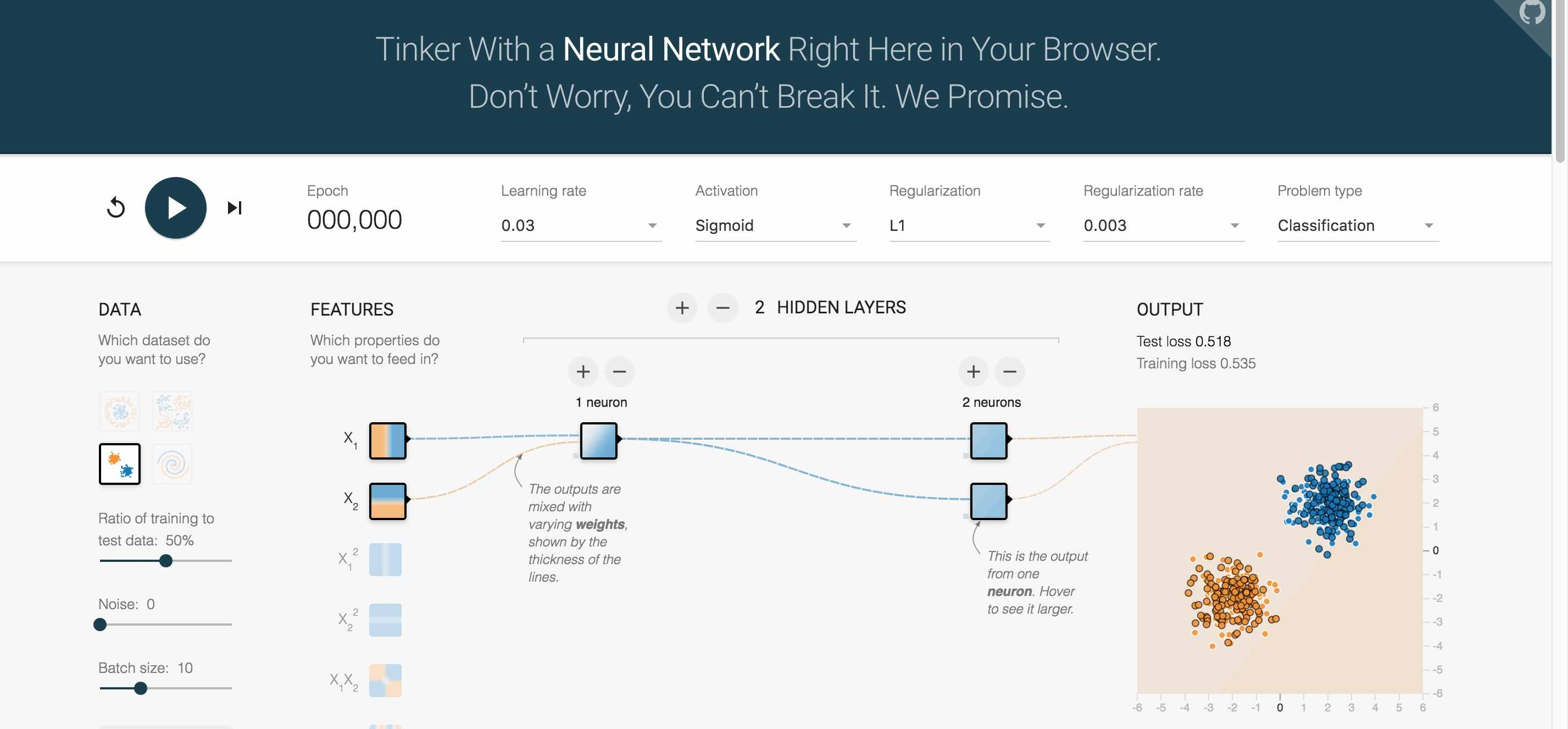
链接:TensorFlow
