

在JDK1.7之前,LinkedList是采用双向环形链表来实现的,在1.7及之后,Oracle将LinkedList做了优化,将环形链表改成了线性链表。本文对于LinkedList的源码分析基于JDK1.8。
LinkedList既然是通过一个双向线性链表来实现,那么肯定就能够很轻易的找到链表的第一个节点和最后一个节点,在源码中可以看到有这两个字段:
transient Node<E> first; // 链表第一个节点
transient Node<E> last; // 链表最后一个节点先来看一下什么是节点Node:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}节点Node中有三个成员:
- item : 存储的元素
- next : 下一个节点
- prev : 上一个节点
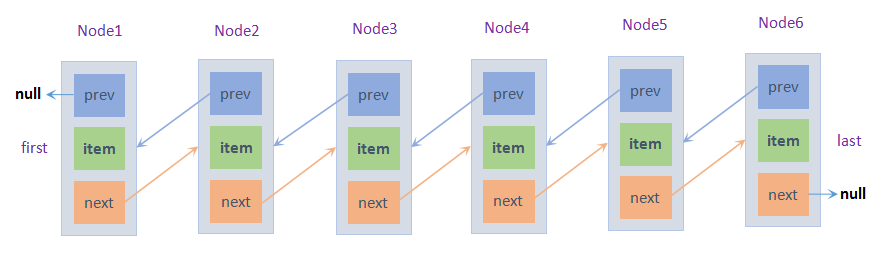
节点中保存有需要存储的元素,同时持有上一个节点和下一个节点的引用,各个节点依次持有前后节点的引用就形成了一个链,这样,当我们需要查找链中某一个节点保存的元素时,只需要通过第一个节点或者最后一个节点依次查找,就可以找到我们需要的节点。
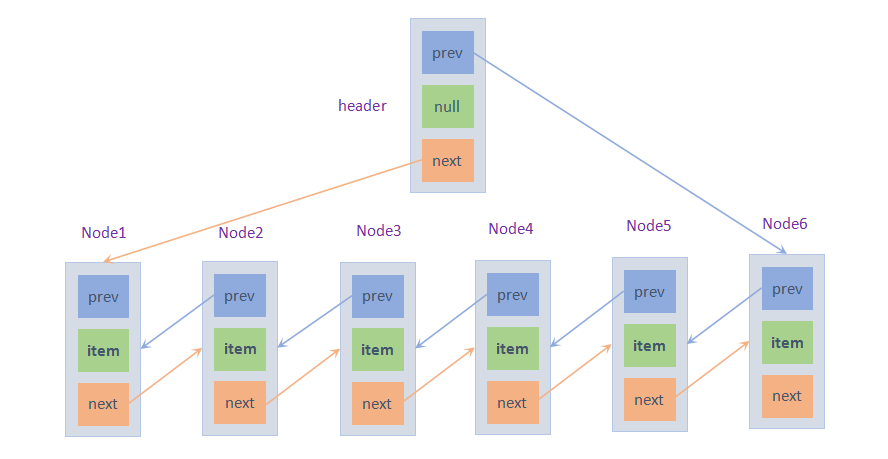
需要注意的是,在JDK1.7及之后,第一个节点first的前一个节点prev为null,最后一个节点last的后一个节点next也为null。而在JDK1.6及之前,头节点header是一个不保存元素的节点,header的下一个节点next是第一个元素节点,而header的上一个节点是最后一个元素节点,这样使得它形成一个环形的双向链表。
LinkedList的构造函数有两个,一个无参,另一个可以传入一个集合:
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}看下addAll方法的实现:
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// 检查是否越界
checkPositionIndex(index);
// 将集合c转化为数组a
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
// pred为插入元素位置点前一个节点,succ为插入元素位置的后一个节点
Node<E> pred, succ;
if (index == size) { // index==size的话,在链表的末尾添加元素
succ = null;
pred = last;
} else { // 否则的话,从链表中间加入
succ = node(index);
pred = succ.prev;
}
// 遍历需要加入的元素数组a
for (Object o : a) {
// 通过元素o构造一个节点Node
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null) // 插入位置的前一个节点为null,说明需要插入的是first节点
first = newNode;
else // 插入位置的前一个节点不为null,即从链表中或链表末尾插入
// 将要插入的节点复制给插入位置的上一个节点的next
pred.next = newNode;
// 将newNode赋值给下个需要插入的节点的pred
pred = newNode;
}
if (succ == null) { // succ为null,说明是从末尾添加的元素,将添加的最后一个元素赋值给last
last = pred;
} else { // 从链表中某个位置添加的,重新连接上添加元素时断开的引用链
pred.next = succ;
succ.prev = pred;
}
// 更新链表的大小
size += numNew;
modCount++;
return true;
}在构造方法中调用addAll方法,相当于是向一个空链表中添加集合c中的元素。
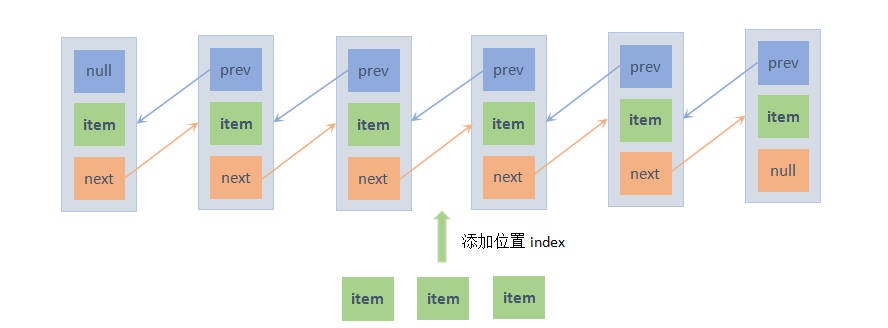
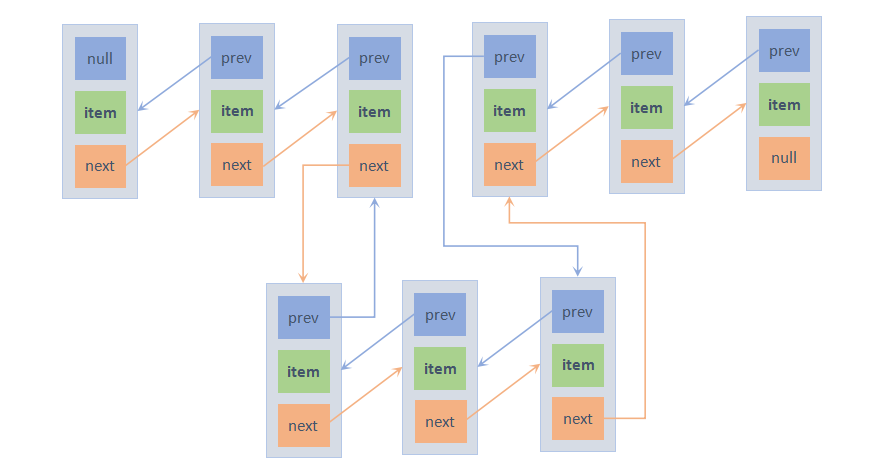
如果是在已有元素的链表中调用addAll方法来添加元素的话,就需要判断指定的添加位置index是否越界,如果越界会抛出异常;如果没有越界,根据添加的位置index,断开链表中index位置的节点前后的引用,加入新元素,重新连上断开位置的前后节点的引用。过程如下图:
add方法:
public boolean add(E e) {
linkLast(e);
return true;
}直接就调用了linkLast方法,说明默认的add方法是直接将元素添加到已有的链表的末尾。
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}新加入元素的节点赋值给last节点,然后判断了一下加入之前的last节点是否为空,为空的话,说明链表中没有元素,新加入的就是链表的first节点;不为空直接将之前的最后一个节点的next引用添加的节点即可。
还有一个add方法,指定了添加位置:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}先判断是否越界,在判断添加的位置是否在已有链表的末尾,如果在末尾就直接添加到末尾,不在末尾的话,调用linkBefore添加到index位置的节点之前。
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}pred为null的话,说明succ是添加元素前链表的first节点,加入元素e,更新first节点,并更改引用链。
addFirst和addLast方法中分别调用了linkFirst方法和linkLast方法:
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}linkFirst/linkLast方法即是将新节点添加到链表的头部或者尾部,更新链表的prev和next引用。
remove方法:
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}不管需要移除的元素O是否为空,都是遍历后调用unlink方法来删除节点,继续看unlink方法:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
// 如果prev为null的话,那么删除的是first节点,将next指定为删除后的first节点
first = next;
} else {
// prev不为null,将prev的next引用指向next,并解除x元素对prev的引用
prev.next = next;
x.prev = null;
}
if (next == null) {
// 如果next为null,那么删除的是last节点,将prev指定为删除后的last节点
last = prev;
} else {
// next不为null,将next的prev引用指向prev,并解除x的next引用
next.prev = prev;
x.next = null;
}
// 置空x节点中的元素
x.item = null;
size--;
modCount++;
return element;
}removeFirst和removeLast方法同样是直接调用了unlinkFirst和unlinkLast,实现和unlink差不多,不做过多解释。
set方法,set方法即修改链表中指定位置的元素:
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}找到指定位置的节点x,更改该节点的item属性就行了。
获取节点的node方法:
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { // 靠近头部
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 靠近尾部
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}判断位置index是靠近头部还是尾部,靠近头部,则从first节点往后遍历,靠近尾部则从last节点往前遍历,这种方式可以使得链表查找的时候遍历次数不会超过链表长度的一半,从而提升查找效率。
get、getFirst、getLast方法:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}getFirst和getLast直接后去first和last节点中的元素值,get方法则直接调用了node方法,不再解释。
LinkedList源码中的其他方法不再分析了,实现都很容易理解。从LinkedList的增、删、改、查等方法的实现逻辑可以看出来,LinkedList的增和删效率相对于改和查要高,因为每次修改和查询都要从链表的头节点或尾节点开始遍历,而增加和删除,只需要在制定位置断开节点引用,添加和删除元素后,重新连上引用链即可。所以,LinkedList适合用在添加和删除比较频繁,而修改和查询较少的情况下。
