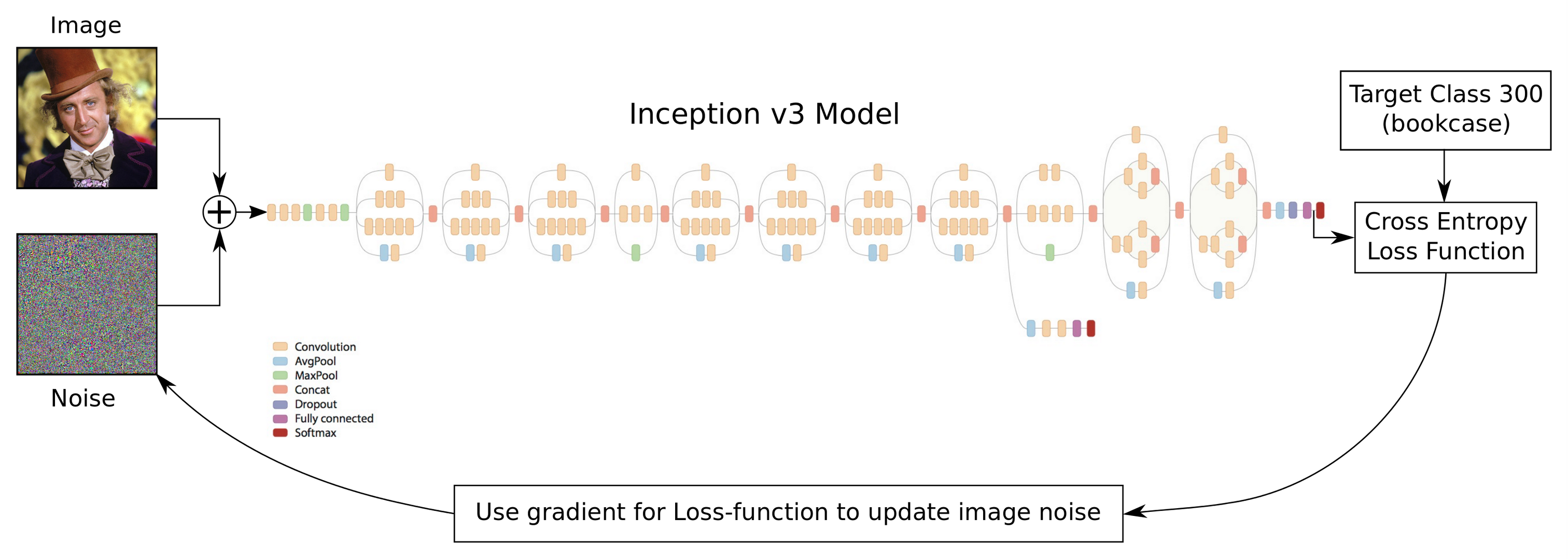
from IPython.display import Image, display
Image('images/11_adversarial_examples_flowchart.png')
导入
%matplotlib inline
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import os
# Functions and classes for loading and using the Inception model.import inception
使用Python3.5.2(Anaconda)开发,TensorFlow版本是:
tf.__version__
'0.11.0rc0'
Inception 模型
从网上下载Inception模型。
从网上下载Inception模型。这是你保存数据文件的默认文件夹。如果文件夹不存在就自动创建。
# inception.data_dir = 'inception/'
如果文件夹中不存在Inception模型,就自动下载。 它有85MB。
inception.maybe_download()
Downloading Inception v3 Model ... Data has apparently already been downloaded and unpacked.
载入Inception模型
载入模型,为图像分类做准备。
注意warning信息,以后可能会导致程序运行失败。
model = inception.Inception()
获取Inception模型的输入和输出
取得Inception模型输入张量的引用。这个张量是用来保存调整大小后的图像,即299 x 299像素并带有3个颜色通道。我们会在调整大小后的图像上添加噪声,然后还是用这个张量将结果传到图(graph)中,因此需要确保调整大小的算法没有引入噪声。
# Set the graph for the Inception model as the default graph,# so that all changes inside this with-block are done to that graph.with model.graph.as_default():
# Add a placeholder variable for the target class-number.# This will be set to e.g. 300 for the 'bookcase' class.
pl_cls_target = tf.placeholder(dtype=tf.int32)
# Add a new loss-function. This is the cross-entropy.# See Tutorial #01 for an explanation of cross-entropy.
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y_logits, labels=[pl_cls_target])
# Get the gradient for the loss-function with regard to# the resized input image.
gradient = tf.gradients(loss, resized_image)
deffind_adversary_noise(image_path, cls_target, noise_limit=3.0,
required_score=0.99, max_iterations=100):"""
Find the noise that must be added to the given image so
that it is classified as the target-class.
image_path: File-path to the input-image (must be *.jpg).
cls_target: Target class-number (integer between 1-1000).
noise_limit: Limit for pixel-values in the noise.
required_score: Stop when target-class score reaches this.
max_iterations: Max number of optimization iterations to perform.
"""# Create a feed-dict with the image.
feed_dict = model._create_feed_dict(image_path=image_path)
# Use TensorFlow to calculate the predicted class-scores# (aka. probabilities) as well as the resized image.
pred, image = session.run([y_pred, resized_image],
feed_dict=feed_dict)
# Convert to one-dimensional array.
pred = np.squeeze(pred)
# Predicted class-number.
cls_source = np.argmax(pred)
# Score for the predicted class (aka. probability or confidence).
score_source_org = pred.max()
# Names for the source and target classes.
name_source = model.name_lookup.cls_to_name(cls_source,
only_first_name=True)
name_target = model.name_lookup.cls_to_name(cls_target,
only_first_name=True)
# Initialize the noise to zero.
noise = 0# Perform a number of optimization iterations to find# the noise that causes mis-classification of the input image.for i in range(max_iterations):
print("Iteration:", i)
# The noisy image is just the sum of the input image and noise.
noisy_image = image + noise
# Ensure the pixel-values of the noisy image are between# 0 and 255 like a real image. If we allowed pixel-values# outside this range then maybe the mis-classification would# be due to this 'illegal' input breaking the Inception model.
noisy_image = np.clip(a=noisy_image, a_min=0.0, a_max=255.0)
# Create a feed-dict. This feeds the noisy image to the# tensor in the graph that holds the resized image, because# this is the final stage for inputting raw image data.# This also feeds the target class-number that we desire.
feed_dict = {model.tensor_name_resized_image: noisy_image,
pl_cls_target: cls_target}
# Calculate the predicted class-scores as well as the gradient.
pred, grad = session.run([y_pred, gradient],
feed_dict=feed_dict)
# Convert the predicted class-scores to a one-dim array.
pred = np.squeeze(pred)
# The scores (probabilities) for the source and target classes.
score_source = pred[cls_source]
score_target = pred[cls_target]
# Squeeze the dimensionality for the gradient-array.
grad = np.array(grad).squeeze()
# The gradient now tells us how much we need to change the# noisy input image in order to move the predicted class# closer to the desired target-class.# Calculate the max of the absolute gradient values.# This is used to calculate the step-size.
grad_absmax = np.abs(grad).max()
# If the gradient is very small then use a lower limit,# because we will use it as a divisor.if grad_absmax < 1e-10:
grad_absmax = 1e-10# Calculate the step-size for updating the image-noise.# This ensures that at least one pixel colour is changed by 7.# Recall that pixel colours can have 255 different values.# This step-size was found to give fast convergence.
step_size = 7 / grad_absmax
# Print the score etc. for the source-class.
msg = "Source score: {0:>7.2%}, class-number: {1:>4}, class-name: {2}"
print(msg.format(score_source, cls_source, name_source))
# Print the score etc. for the target-class.
msg = "Target score: {0:>7.2%}, class-number: {1:>4}, class-name: {2}"
print(msg.format(score_target, cls_target, name_target))
# Print statistics for the gradient.
msg = "Gradient min: {0:>9.6f}, max: {1:>9.6f}, stepsize: {2:>9.2f}"
print(msg.format(grad.min(), grad.max(), step_size))
# Newline.
print()
# If the score for the target-class is not high enough.if score_target < required_score:
# Update the image-noise by subtracting the gradient# scaled by the step-size.
noise -= step_size * grad
# Ensure the noise is within the desired range.# This avoids distorting the image too much.
noise = np.clip(a=noise,
a_min=-noise_limit,
a_max=noise_limit)
else:
# Abort the optimization because the score is high enough.breakreturn image.squeeze(), noisy_image.squeeze(), noise, \
name_source, name_target, \
score_source, score_source_org, score_target
绘制图像和噪声的帮助函数
函数对输入做归一化,则输入值在0.0到1.0之间,这样才能正确的显示出噪声。
defnormalize_image(x):# Get the min and max values for all pixels in the input.
x_min = x.min()
x_max = x.max()
# Normalize so all values are between 0.0 and 1.0
x_norm = (x - x_min) / (x_max - x_min)
return x_norm
这个函数绘制了原始图像、噪声图像,以及噪声。它也显示了类别名和评分。
defplot_images(image, noise, noisy_image,
name_source, name_target,
score_source, score_source_org, score_target):"""
Plot the image, the noisy image and the noise.
Also shows the class-names and scores.
Note that the noise is amplified to use the full range of
colours, otherwise if the noise is very low it would be
hard to see.
image: Original input image.
noise: Noise that has been added to the image.
noisy_image: Input image + noise.
name_source: Name of the source-class.
name_target: Name of the target-class.
score_source: Score for the source-class.
score_source_org: Original score for the source-class.
score_target: Score for the target-class.
"""# Create figure with sub-plots.
fig, axes = plt.subplots(1, 3, figsize=(10,10))
# Adjust vertical spacing.
fig.subplots_adjust(hspace=0.1, wspace=0.1)
# Use interpolation to smooth pixels?
smooth = True# Interpolation type.if smooth:
interpolation = 'spline16'else:
interpolation = 'nearest'# Plot the original image.# Note that the pixel-values are normalized to the [0.0, 1.0]# range by dividing with 255.
ax = axes.flat[0]
ax.imshow(image / 255.0, interpolation=interpolation)
msg = "Original Image:\n{0} ({1:.2%})"
xlabel = msg.format(name_source, score_source_org)
ax.set_xlabel(xlabel)
# Plot the noisy image.
ax = axes.flat[1]
ax.imshow(noisy_image / 255.0, interpolation=interpolation)
msg = "Image + Noise:\n{0} ({1:.2%})\n{2} ({3:.2%})"
xlabel = msg.format(name_source, score_source, name_target, score_target)
ax.set_xlabel(xlabel)
# Plot the noise.# The colours are amplified otherwise they would be hard to see.
ax = axes.flat[2]
ax.imshow(normalize_image(noise), interpolation=interpolation)
xlabel = "Amplified Noise"
ax.set_xlabel(xlabel)
# Remove ticks from all the plots.for ax in axes.flat:
ax.set_xticks([])
ax.set_yticks([])
# Ensure the plot is shown correctly with multiple plots# in a single Notebook cell.
plt.show()
寻找并绘制对抗样本的帮助函数
这个函数结合了上面的两个方法。它先找到对抗噪声,然后画出图像和噪声。
defadversary_example(image_path, cls_target,
noise_limit, required_score):"""
Find and plot adversarial noise for the given image.
image_path: File-path to the input-image (must be *.jpg).
cls_target: Target class-number (integer between 1-1000).
noise_limit: Limit for pixel-values in the noise.
required_score: Stop when target-class score reaches this.
"""# Find the adversarial noise.
image, noisy_image, noise, \
name_source, name_target, \
score_source, score_source_org, score_target = \
find_adversary_noise(image_path=image_path,
cls_target=cls_target,
noise_limit=noise_limit,
required_score=required_score)
# Plot the image and the noise.
plot_images(image=image, noise=noise, noisy_image=noisy_image,
name_source=name_source, name_target=name_target,
score_source=score_source,
score_source_org=score_source_org,
score_target=score_target)
# Print some statistics for the noise.
msg = "Noise min: {0:.3f}, max: {1:.3f}, mean: {2:.3f}, std: {3:.3f}"
print(msg.format(noise.min(), noise.max(),
noise.mean(), noise.std()))
# This has been commented out in case you want to modify and experiment# with the Notebook without having to restart it.# session.close()# model.close()