

如果你觉得内容太长,可以直接跳过看 repo: github.com/huozhi/html…
灵感
繁忙任务多了一件事,设计希望我们能有一个非常完备的 FAQ 子站点,能为用户提供非常详细的帮助信息。
Design: 首先这里会有一个搜索 🔍,可以检索任意页面,每个页面是富文本的帮助内容
FE: 嗯,看起来还不错,应该比较好搞
Design: 富文本中需要支持视频、gif、以及行内图片、块级图片 blablabla…我们希望和我们的主站点所有的交互、样式能保持一致
FE: 可这是个新项目,目前那些东西都还不能完全组件化地移植过来…
Design: 但我们希望视频、gif 都能有之前他们做好的样式、交互、功能
FE: 文本来自哪里?
Design: 我们希望还能有一个支持这些功能上传的编辑器…
FE:
着急吗?
Design: 嗯,尽快上线!
WHAT THE HELLLLL…

听起来是一件怎么着都干不完的活了,前端团队内部其实一件有一套支持复杂交互的视频、Gif 组件,还有一个编辑器,但是依赖的东西太多了,加上每个操作可能都有数据打点,开发的人并没有将组件化的程度搞到「随意无障碍移植」的程度,因为在富文本中显示视频、Gif 等内容需要使用之前的 RichText 组件,这里面包含的东西太多了。
而我们 只是想要一个静态页面
页面有这些交互就可以了,可以单独引入组件,但完全不需要编辑器富文本里更复杂的东西。。。
编辑器 & 富文本
当你在知乎的回答框中简单输入一些文字,对他们进行加粗、变成斜体、插入图片,其实就已经完成了一次富文本编辑。因为这些内容已经不仅仅是纯文字可以展示的内容了,他们需要更加复杂的 html 和 css 进行配合,可能还有 inline style,亦或附带 js 交互。
编辑器也分种类:
- stateful editor: 比如 draftjs,slate 等,都是将输入的 html 转为一个状态,再从状态序列化到真正的 html
- non-stateful editor: 不需要状态,比如简单的依赖 contenteditable,在其上做一层封装,如 Medium.js 等
保存编辑内容常规的思路有两种:
- 使用 stateful editor ,保存它的状态到数据库里,展示的时候从状态转换过来,比较自然
- 使用任意 editor,编辑的时候保存 html,显示的时候直接展示
保存状态有时候在迁移编辑器的时候容易带来问题,比如 google closure editor 迁移到 draftjs,如果原来就没有状态,突然来了个有状态,要转换原来的吗?如果哪天 draftjs 被替换成另一种怎么办?有点风险
如果保存 html,展示时候需要有交互怎么办?draftjs 和 slate 都是状态化的,在 html 和 state 之前转换是依靠一个 serializer + deserializer (序列化 + 反序列化 器)来完成的。draft 可能需要你使用 draft-convert 这样的库来做,slate 则直接内置了一个 html serializer + deserializer,非常方便。
说了这么多,和我们的场景有什么关系呢?
第一次尝试 slate 编辑器的时候,觉得非常舒服,因为它的 html 转换
const rules = [
{
deserialize(el, next) {
if (el.tagName.toLowerCase() == 'p') {
return {
kind: 'block',
type: 'paragraph',
nodes: next(el.childNodes)
}
}
},
// Add a serializing function property to our rule...
serialize(object, children) {
if (object.kind == 'block' && object.type == 'paragraph') {
return <p>{children}</p>
}
}
}
]
import { Html } from 'slate'
// Create a new serializer instance with our `rules` from above.
const html = new Html({ rules })
state = {
state: html.deserialize(html),
}
const string = html.serialize(someState)是不是很有意思?我们定义了一个序列化/反序列化的规则,然后就可以尽情在 state 和 html 之前转换了。COOL!!
看到这里,发现了吗?其实我们要的就是这样一个东西,一个剥离编辑器其他功能的,序列化和反序列化 html 功能的东西,来帮助我们完成更加复杂的状态展示。
LETS DOT IT
还记得编译器的原理吗?把 code string 转化成 machine code 的过程:
- tokenizer: 解析出特殊的 token
- parse: 转化成 AST
- transform: 把 AST 转换成 dest code
同样的,我们的 html 解析和中间状态转换就像极了这个过程,dest code 其实就是我们要的最终 form,它可以是一个组件,可能是另一个 html string,可能是一个 JSON,都随意啦
我们要做的就是三个过程:
- 解析 html 到合适的 html tag
- 转换成一个 tree,每个节点是一个 html tag,包含它自己的信息
- 遍历这个 tree,替换每个 node 到你想要的样子
Introduce you html2any
来看看我最后的实现 github.com/huozhi/html…
Run on React Native
可以看看在 React Native 上的表现:
一段包含粗体和图片的 html 被我们转换成了 Native 的形式,这是在 iOS 上的截图
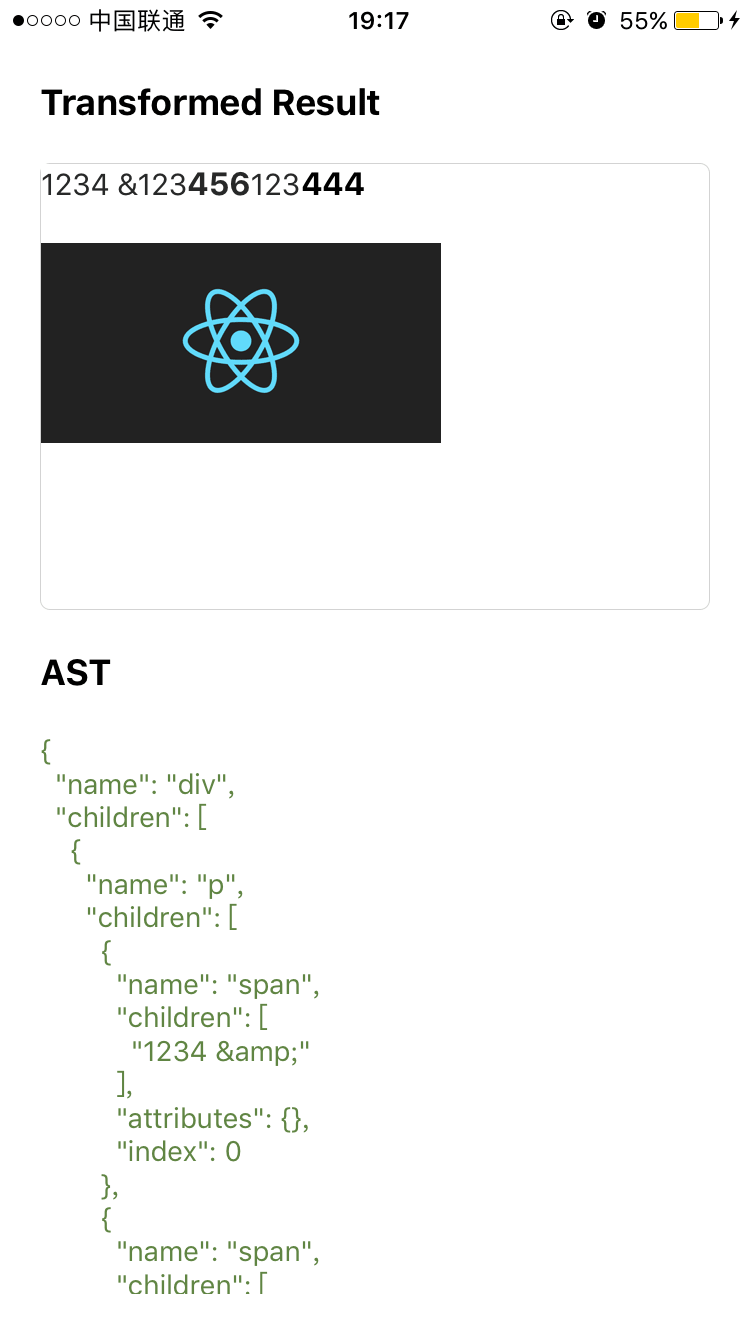
当然由于 React Native 的组件嵌套起来限制比较多,比如 Text 里套 View 需要指定 size 、Text 下的 Text 是没有样式继承的,不像 css..
Run on Web with React
可以点进去体验一下。我们做了一个简单的替换规则:
- br 替换成了一个 hr 标签
- gif 图片替换成了一个有 loading 的 gif player
- 原生视频被替换成了一个 react 的 video player
如果想要更多的规则替换,完全可以写更复杂的规则(rule 函数),然后剩下的交给 html2any 处理就好了
参考与对比
其实 html parser 本身在市面上已经有很多种形态了,大家最熟悉的就是 parse5、htmlparser2 等,连 cheerio 都用了 htmlparser2。为什么还要再自己重新造轮子写一个呢?
原因有下面几个吧:
- html2any 真的很小,如果处理状态化编辑器生成出来的 html,非常方便。如果你使用 slate,使用 draft,展示内容的时候不妨一试。
-
很多 parser 都是 sax 形式的,顺势向下 parse,会给你很多的 API 来处理中间的过程、阶段,我们其实并不需要这些,以及他们兼容了很多我们可能不需要的 case
-
最重要的原因 —— 很多 parser 专门为 web 而生,最终想要做出 html,或者是 DOM Tree,我们要的不是这些。看到上面的栗子了吗?我们做的是 Universal HTML! Render Everywhere!哈哈
最后附上我的 slide
