

前端体系建设从前端开始专职发展就慢慢开始演进了。过去,我们习惯描绘一些技术细节作为前端体系所需要的,而没有看到其背后的连接,所谓建设之道,即是建立向前向后的连接。前端在项目研发中的上流是交互视觉,下流是后端研发。这两个角色之间的连接对我们来说至关重要。
这就有两个方面,一是团队与团队之间的体系,尤其是上下流团队之间的连接。二是前端团队之内的体系,可以理解为角色之中的连接。
与设计师的连接
对于前端的前端是交互视觉,交互视觉在我们固有的理解一定带着『不可控』的因素,即便我们定了交互视觉标准。
沉淀组件体系标准
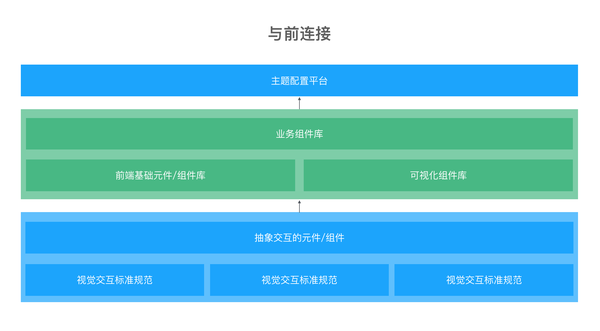
我们分解系统的基本交互逻辑,一定由基本组件构成。我们完全可以固化下来沉淀成基础组件库。对于基本组件而言,我们确定一个『可变』范围,包括底色,边框色,圆角,字体等,梳理出一套『样式变量』。那么就在可视范围内,我们可以调整出多套基本交互视觉模板。
不同形态的产品用户体验心流是不同的,所形成的交互视觉会有所不同。因此,对于前端来说与之连接一定是在同一个交互视觉规范下。这个范围的界定可以通过用户体验心流一致来判断,比如操作控制类,数据展示类等。今天,设计师们一般会将产品设计理念沉淀成一套设计语言,如 antd 会针对后台应用类。
这时,我们必须要考虑背后的问题,我们怎么针对不同的交互视觉抽象组件。antd 背后的 rc-component 就高度抽象了组件行为,让上层 antd 去选择用怎样的交互。形成很好的组件体系,也很方便的让其它前端基于此新建一套设计语言。
因此,抽象交互的组件体系结合不同的视觉交互标准规范就可以形成一系列组件库,从而构成前端组件体系,而其中的样式部分经过我们的抽象可以成为主题配置的要素,最终形态就是主题配置平台。当我们的业务选择生成一套组件的时候可以同时生成交互所需要的组件模板,非常方便地让视觉完成页面和应用级别的工作。
material design 就是很好的 demo。google 设计师开发的基于 material 风格的 sketch plugin 意在生成复杂的 Material Design 风格的交互控件。更进一步,可以将 sketch 在生成模板代码。这是连锁反应。
更好的相互理解
在与交互视觉的连接中,前端的工作很像是『翻译』。但工程师本身对于设计,甚至美感是相对不擅长的领域,但我们在工作中常常遇到设计师的天马行空,对于前端开发成本较高的情况。另外,还有很多设计师会以『技术先行』的方式尝试自己的交互 demo。
在专业领域,比如数据可视化,带着数据研发流程在内,这时侯不只是单纯的从视觉交互上考虑,而是从数据本身的角度结合视觉交互去帮助理解业务,从而设计一种合适的可视化形态。
因此,对于角色本身来说,并不完全都是正向连接的关系。前端也有义务帮助设计师更好的理解页面的构建方式,可视化图表的正常使用方式等。
与后端研发的连接
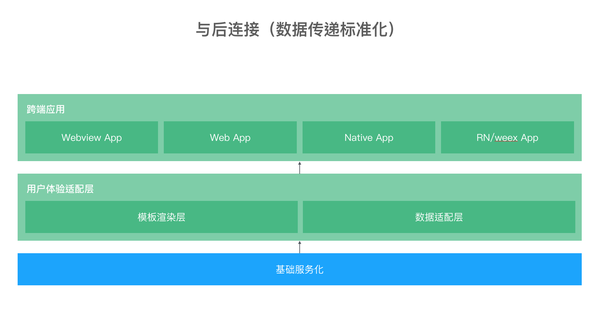
前端与后连接的是后端研发,现在应用为了高效的交互体验已经极少使用同步请求,因此,我们与后端的连接主要在于异步接口定义上,还有一部分是页面初始化的页面模板渲染两个部分。
接口定义对于前后端之间是一份契约,将两个角色团队的人连接起来,高效协作。对于传统前后端交互,为了并行开发的便利,会在项目前相互对接口进行约定,然后各自开发,最后在预发环境下联调正式接口。这个过程有几个问题。
数据模型
由于前端对于数据的理解不是基于底层数据,而是基于界面元素。尽管前后端对于接口的约定在项目一开始就会约定,但后端对于最终数据的来源存在不确定性。字段及格式在总是会有不少调整,对于项目来说带来的很多风险。
对于通用业务,前后端倾向于均抽象一套实体模型。那么前后端只要维护这一套数据模型就可以实现无调整即可上线。这时配合 GraphQL 感觉会有『彻底』的前后端分离,更好的是非常适合来做数据适配。
单独考虑数据适配层,对于前后端都可以来做这一层,需要做一些取舍。考虑到了发布成本,数据、后端,前端发布的成本中前端一定是最小的。一旦数据或后端出问题,前端可以快速适配作应急处理。因此,在现实当中,常常由前端来做一层的适配。
对于个性化业务,只能 case by case 来约定接口。这时,我们需要一个 Mock 接口的服务来作模拟接口,实现对线上接口的代理。通过平台与本地工具无缝切换,同步这个过程。这么做为了最小化联调的时间。Easy Mock 平台就是一个不错的开源选择。
跨端适配
由于不同的终端产品与研发的视角均不同,研发对于数据的理解也会不同。例如在无线端数据要求更精简,而 Web 上一般没有这样的要求。
那么我们想到对于底层数据都是相似的,但上层应用接口却有差异。那么,我们就让原来面向应用的接口下沉形成的微服务,提高抽象性与稳定性。而在它的前端引入一层 BfF(服务于前端的后端)层。这种模式不会为所有的客户端创建通用的接口,我们可以拥有多个 BfF,对应于 Web、移动客户端等。
这一层的好处在于后端主要的关注点下沉到微服务架构,如果其中一个服务要迁移,那么其中一个 BfF 就可以调用新服务,其它的保持不变。进一步提高了系统的解耦。
当然,这种模式的问题在于谁来维护 BfF 层。如果由后端来维护这一层那么选用一种轻量级的语言会加快研发的效率,比如 PHP。如果由前端来维护这一层,那么 Node 就非常适合。对于接口服务来说主要是高 IO 场景,正与 Node 优势相匹配。这一选择取决于团队人员的配比。
模板管理
在过去接口服务还不多的情况,前后端主要的连接就在于模板。
对于后端来说会把系统变量直接写在模板中,这对于前端维护来说就带来了很多困难。对于前端来说,我们的脚本与样式的配置都在模板当中,常常因为发新版需要改地址。
对于耦合这么严重的这部分。对于今天前端来说,已经慢慢找到自己的方法。就是通过 Node 来管理这个模板,将模板做成通用服务,后端会把系统变量发送给服务,服务来完成后续的模板生成的工作。
这带来的另一个好处是我们在做 SSR 时只需要将逻辑在这一层当中完成即可。
那么,在理想情况下,我们会抽象一层『用户体验适配层』来做两个工作,模板渲染与数据适配。这也是今天前端工作外沿的一个表现之一。对于后端来说,这一层相当轻,对于前端来说,这一层对于我们的连接显得更加顺畅。
稳定性保障
产品的数据化运营,我们都耳熟能详,一般体现在运营效率的突破,商业模式的创新,客户价值的提升等。
那么再来看商业价值的背后是产品的稳定性,从产品角度稳定性链路是贯穿在交互行为的链路中。其中,一系列的交互行为引发了一系列的前后端的请求,后端与数据库的请求。我们称之为端到端的稳定性保障。
端到端的监控,除了我们必须要制定好详细的规范以外,重点看的是每条链路上的性能,并能够在最短的时间内知道哪里的链路出问题了。做法比较简单,前端发送的每一个请求都会带上一个 traceId,这样就可以马上跟踪到是后端的哪一个类,并关联到是哪些 SQL 的调用,哪些关联表位于哪些机房中。
正因为有这样的全链路保障,我们不同角色之间相互独立,又相互连接在一起。成为产品保障的基石。
更好的相互理解
诚如上述与设计师一样,与后端研发合作同样涉及到如何帮助后端更好的理解前端。
前端与后端的理解差异往往来自于数据接口上。后端是服务器环境,前端是浏览器环境,往往两者处于的立场不同,不能感同深受。前端考虑的是用户体验增强,因此,为了在数据传输大小与次数上都有自己的考虑,这时候与后端的工作就有关联。
因此,现代前端也更倾向于将抹平这一层差异的工作放到『中间层』来做。为了做更极致的前后端解耦与性能优化。
前端自我连接
回到最后前端自身的连接。从蒸汽时代的工业革命到今天信息时代,经历了工具的演变。从工作效率、稳定性上提升了几个层级。今天的前端界的工程革命,对于知识的半衰期来说,大概只有2-3年时代。同样经历了标准的创新,工具的创新等。
在这个时代下我们怎么做自我连接呢。
架构选型
前端从过去的页面级发展到今天的应用级,我们看待系统的复杂度也在与日俱增。技术架构与团队息息相关,对于技术架构定义两个关键词 面向未来 和 面向场景。
如果今天业务面向场景几乎是静态页面,那么我架构的选择重点会在重模板语言设计上,可以方便作自动化构建。
而今天,我们的产品是重展示的模块化界面,我的技术架构基础是 React,React 代表了今天趋向于应用级的发展的前端需要完整的聚合组件概念。但上层会有两套模板,一套是以 flux 为基础理念,保证在复杂状态下的数据流的控制,一套以 observable 为基础理念,保证了其使用简单,方便后端工程师上手。在不同场景和规模下使用。
当然,架构的变化对于前端来说只有几年时间,我们应对的是高速发展的互联网和其人机交互的形式。如果说我们可以在一套系统中针对不同的技术架构作共存,以及迭代方案。技术本身就有了流动性,技术发展不会在团队中停滞。
因此,在框架能力差不多的情况,我不会混用,只会用其一,但也不会排斥未来转型。我考虑的是如何来控制它们的迭代。
流程标准化
经历过那个工具匮乏年代的前端工程师,前端工程项目通常没有构建、调试、测试工具,只会涉及到简单的脚手架和压缩打包功能。可以提供给前端最常见的是在工程下新建 makefile 设定一些命令,脚本语言通常会选择 shell 或 python。
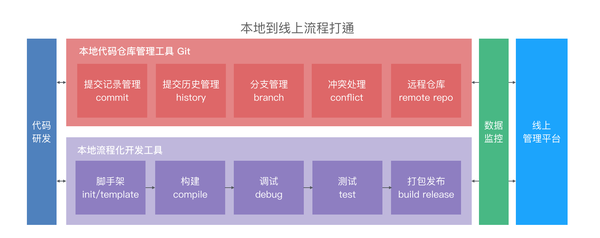
直到 Node 兴起了之后,前端工程化算是真正开启了大门。我们看到了从 grunt 开始基于 node 环境的流程化工具的兴起,直到发展到今天大行其道的 webpack。我们一直会紧跟时代变化对流程工具做改变,但流程本身的逻辑 **脚手架、构建、调试、测试到打包发布** 这些从来没有变过,或一直在我们的预想之中。
对于今天的本地流程化工具,我所需要的功能可能一直是这些,但背后一定需要它具有可扩展性,本地线上打通的能力,以及数据监控。
1. 可扩展性
命令行工具天性就非常容易封装,我们常用的 git 就有流程扩展 gitflow。那么流程化工具的扩展能力在于它每一个环节具备重写能力。比如 Web 流程和无线流程本身的工具体系有所不同,但流程是一样的,我们可以通过不同的插件化能力去扩展。
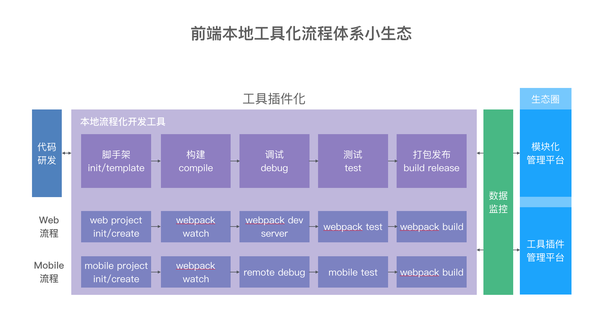
2. 去中心化
去中心化意味着可以本地工作,专注在个人工作上。而线上意味是多人协作的终端,可以看到不同人的结果。
如本地 git 就有一个 repo 来做管理,在没有 push 到 remote 服务器时我们一直可以做到本地管理。到线上,我们有类似于 github 这样的平台,可以做 issue,project 管理,这是一个 team 级别一起来做的事。
对于本地流程化工具来说,打包发布就需要和线上作一个关联,因为发布行为本身是一个团队协作的一部分,我们有必要统一管理,那么作为本地工具,我们知道它具有的便利性,那么线上平台则保证的是团队的协同。
3. 数据监控
对于 git 来说,它本身就是一个数据库。而本地流程化开发工具只是一个命令行工具,数据上报的意义在于在服务端统一每一个环节的效率,我们可以怎么优化这些环节。
自我理解
我们有界面逻辑,属于非逻辑沉淀。我们有数据逻辑,属于逻辑沉淀。我们在处理它们的理解与产品理解之间的误差。最终的人机交互界面展现的是前端的工作,我们的工作有极大的不确定性。把这种不确定性尽可能安定下来,是我们的工作。
总结
全文述说最基本原则是 不同角色之间的连接减少约定,加强标准建设;前端自身则是首要提高流程化管理的能力,同时不断从场景中抽象应用架构的能力。研发流程体现的是效率与稳定的平衡。总体架构的取舍体现在 团队规模与业务的发展速度:
1. 每一个环节都在尽可能小的粒度上,遵从 Unix 原则
2. 每一个环节具备定制能力,有进一步生态化的能力
3. 每一个环节规定输入输出作规范化沉淀
4. 链路连接的工作让系统来完成
5. 全链路都都有数据支持,不断调整其中的取舍
在每一个角色阶段,都会有自己的服务,如 Demo 管理平台,PRD 管理,自动化测试系统等。但它们之间都是分散的,并没有针对项目的角度是整体审视。因此,在整体研发的体系建设上,全链路研发管理集中在流程管理系统之中,会把其中核心的流程抽取出来形成一套系统。
在大规模企业中职能团队就非常之多,这样就面临着职能团队与职能团队,职能团队与上下流团队之间的平衡。我们既要考虑人在环境中的创造性,又要考虑重要建设的成本,所有的架构一定是时时刻刻讲求当前效益最大化。
