

一、背景
ELK Stack 是软件集合 E lasticsearch、 L ogstash、 K ibana 的简称,由这三个软件及其相关的组件可以打造大规模日志实时处理系统。
其中,Elasticsearch 是一个基于 Lucene 的、支持全文索引的分布式存储和索引引擎,主要负责将日志索引并存储起来,方便业务方检索查询。
Logstash 是一个日志收集、过滤、转发的中间件,主要负责将各条业务线的各类日志统一收集、过滤后,转发给 Elasticsearch 进行下一步处理。
Kibana 是一个可视化工具,主要负责查询 Elasticsearch 的数据并以可视化的方式展现给业务方,比如各类饼图、直方图、区域图等。
所谓“大规模”,指的是 ELK Stack 组成的系统以一种水平扩展的方式支持每天收集、过滤、索引和存储 TB 规模以上的各类日志。
通常,各类文本形式的日志都在处理范围,包括但不限于 Web 访问日志,如 Nginx/Apache Access Log 。
基于对日志的实时分析,可以随时掌握服务的运行状况、统计 PV/UV、发现异常流量、分析用户行为、查看热门站内搜索关键词等。
二、架构
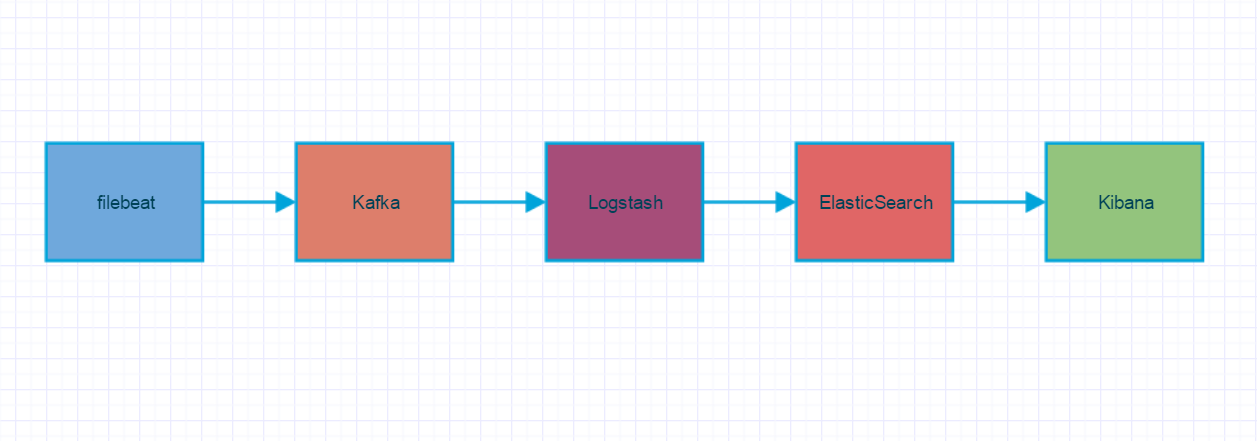
ELK Stack 系统应用架构
上图是 ELK Stack 实际应用中典型的一种架构,其中 filebeat 部署在具体的业务机器上,通过定时监控的方式获取增量的日志,并转发到 Kafka 消息系统暂存。
Kafka 以高吞吐量的特征,作为一个消息系统的角色,接收从 filebeat 收集转发过来的日志,通常以集群的形式提供服务。
然后,Logstash 从 Kafka 中获取日志,并通过 Input-Filter-Output 三个阶段的处理,更改或过滤日志,最终输出我们感兴趣的数据。通常,根据 Kafka 集群上分区(Partition)的数量,1:1 确定 Logstash 实例的数量,组成 Consumer Group 进行日志消费。
最后,Elasticsearch 存储并索引 Logstash 转发过来的数据,并通过 Kibana 查询和可视化展示,达到实时分析日志的目的。
Elasticsearch/Kibana 还可以通过安装 x-pack 插件实现扩展功能,比如监控 Elasticsearch 集群状态、数据访问授权等。
三、实现
我们一步步安装部署 ELK Stack 系统的各个组件,然后以网站访问日志为例进行数据实时分析。
首先,到 ELK 官网 下载需要用到的 Filebeat/Logstash/Elasticsearch/Kibana 软件安装包。(推荐下载编译好的二进制可执行文件,直接解压执行就可以部署)
1、下载并配置 Filebeat,开启日志增量监控
本文使用的版本是 5.2.2,解压 Filebeat ,修改其中 filebeat.yml 的内容为:(详细内容参见本文附录链接)
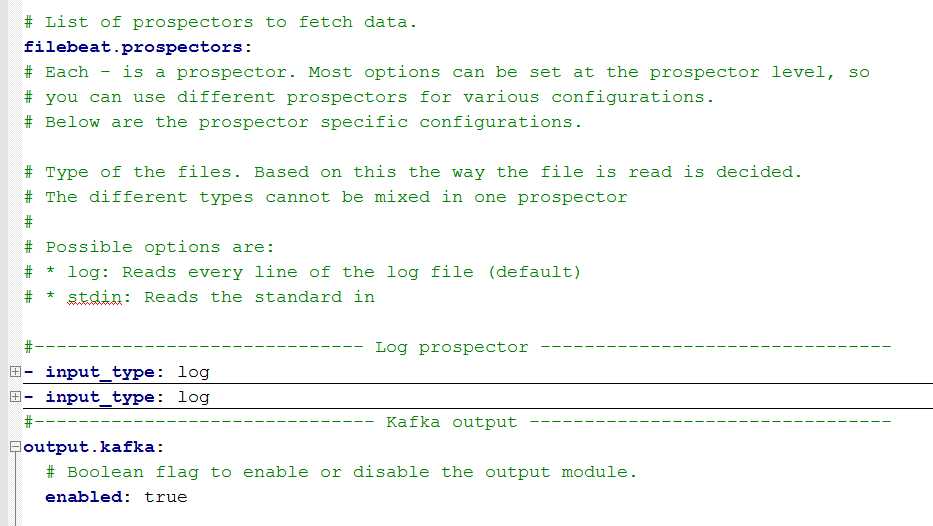
filebeat.yml 配置文件示例
上述配置表示,Filebeat 定期监控:
/path/to/my/nginx/access/*.log
目录下所有以 .log 结尾的文件,并且将增量日志转发到 Kafka 集群。
然后,后台启动 Filebeat 进程:
nohup ./filebeat -c ./filebeat.yml &
这时候,在浏览器上访问 Nginx 服务器并生成访问日志后,Filebeat 会及时的将日志转发到 Kafka 集群。转发的时候,Filebeat 会传输 JOSN 对象,而且原生的 Nginx 日志文本会作为 message 字段,示例如下:

filebeat 传输内容
2、下载并配置 Kafka 集群
到 Kafka 官网 下载安装包,本文使用的版本是 0.10.2.0,确认已安装 java 运行环境
解压后,编辑配置文件 conf/server.properties:(详细内容参见本文附录链接)
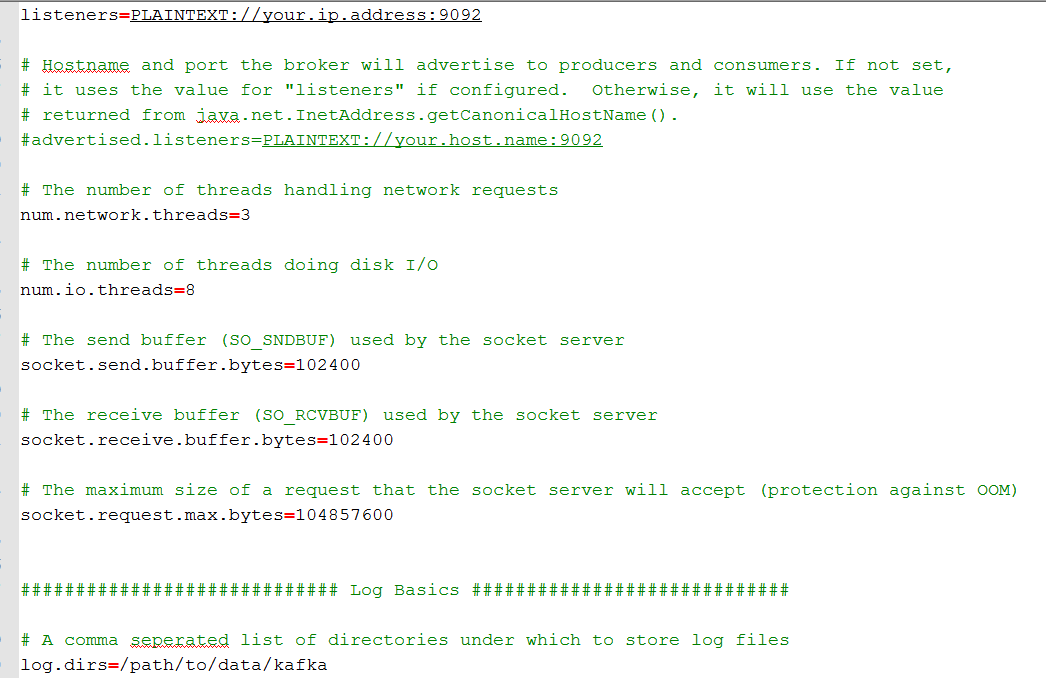
Kafka server configuration
启动 Zookeeper:
nohup ./bin/zookeeper-server-start.sh config/zookeeper.properties &
启动 Kafka Server:(指定 JMX_PORT 端口,可以通过 Kafka-manager 获取统计信息)
JMX_PORT=9001
nohup ./bin/kafka-server-start.sh config/server.properties &
2.1、安装 Kafka-Manager
kafka-manager 是 Yahoo 公司开源的一个 kafka 集群管理工具。
可以在 Github 上下载安装: github.com/yahoo/kafka…
如果你通过 sbt 编译太慢的话,可以直接下载本文附件,这是一个编译好的安装包,解压后,修改配置文件 conf/application.conf 即可运行:
bin/kafka-manager -Dconfig.file=/path/to/application.conf -Dhttp.port=8080
然后,通过浏览器访问:
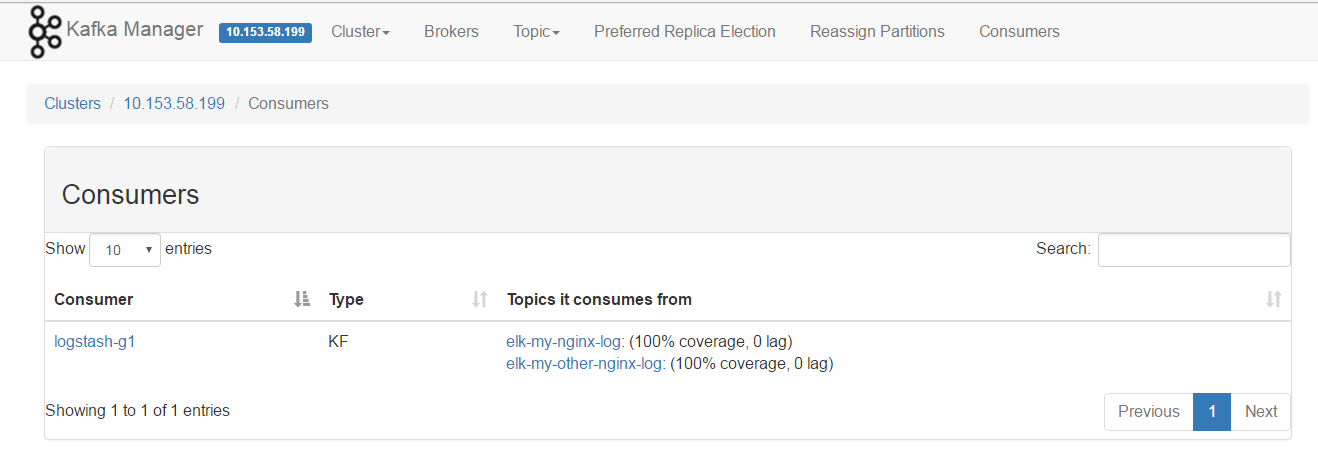
Kafka-manager 界面
3、下载并配置 Logstash
本文使用的版本是 5.2.2,创建 logstash.conf 文件:(详细内容参见本文附录链接)
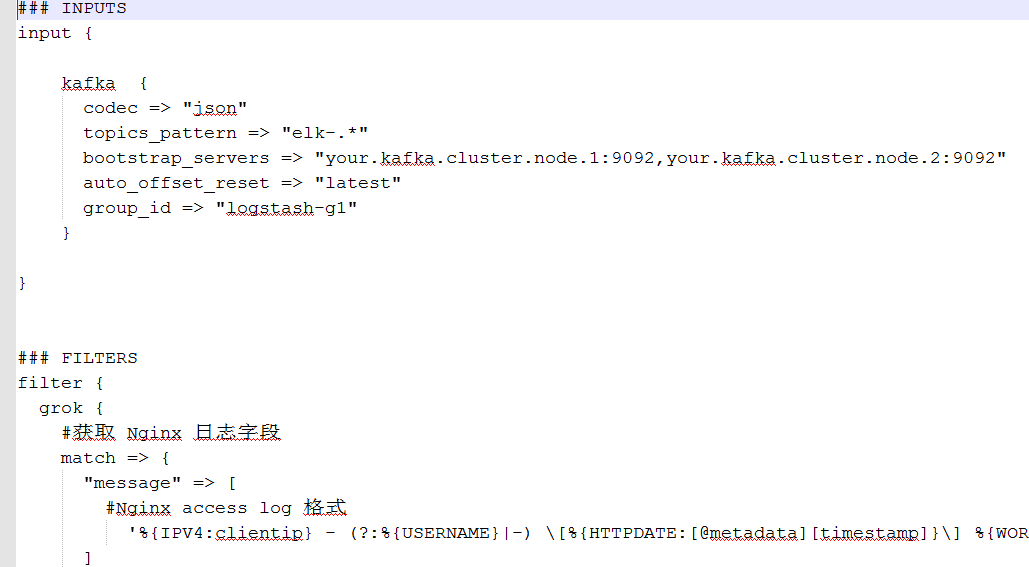
Logstash configuration
配置文件主要分为三大部分: Input / Filter / Output,对应收集、过滤、转发三个阶段。显然,Input 阶段只需要指定 Kafka 集群相关信息即可,Output 阶段只需要指定 Elasticsearch 服务器相关的信息即可,比较复杂的是 Filter 过滤阶段。
可以看到,上述配置中,grok 插件使用正则表达式将 Nginx 日志的各个字段匹配出来,包括访问用户 ip 地址、请求时间和地址、服务器响应字节以及用户标示 User-Agent 等。
关于 Grok 的语法,可以参考: grokdebug.herokuapp.com/
然后,mutate、ruby、useragent、date、kv 等插件配合使用,过滤并获取到感兴趣的字段,最后输出如下示例的 JOSN 对象:

Logstash 转换后输出的 JSON 对象
这就是最终存储在 Elasticsearch 中的文档内容。
接下来,就可以启动 Logstash 进程了:
nohup ./bin/logstash -f ./logstash.conf &
4、配置并启动 Elasticsearch 服务
本文使用的是 5.2.2 版本,下载并解压后,修改 conf/elasticsearch.yml 内容如下:(详细内容参见本文附录链接)
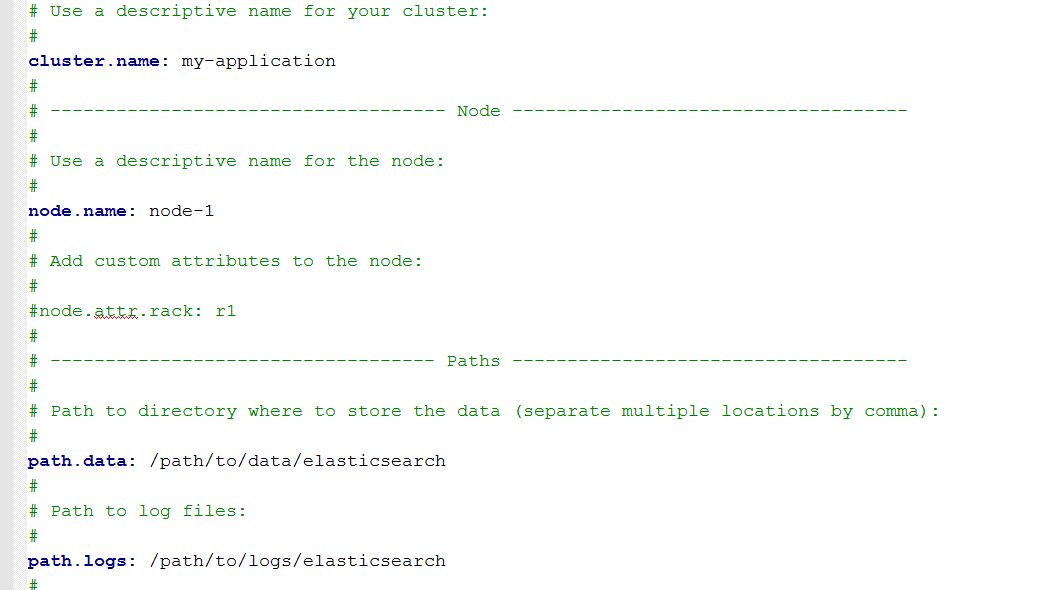
Elasticsearch configuration
指定文档和日志的存储路径以及监听的地址和端口。
注意,应当保证有足够的磁盘空间来存储文档,否则 ES 将拒绝写入新数据。
安装 x-pack 插件:
bin/elasticsearch-plugin install x-pack
另外,不能使用 root 用户启动 Elasticsearch 进程,建议新建账户 elasticsearch。
环境变量 ES_JAVA_OPTS 被读取为 Elasticsearch 的最大内存空间,一般设置为你机器内存的一半即可,启动 ES 服务:
ES_JAVA_OPTS="-Xms4g -Xmx4g"
nohup ./bin/elasticsearch &
如果启动 Elasticsearch 出现以下错误提示:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
那么需要修改系统配置:
vi /etc/sysctl.conf 修改虚拟内存配置:
vm.max_map_count = 262144
对于 Ubuntu 系统需要执行:
sudo sysctl -w vm.max_map_count=262144
可以通过
sudo sysctl -w | grep max_map_count
查看修改结果是否生效
vi /etc/security/limits.conf 修改 文件描述符限制:
elasticsearch soft nofile 65536
elasticsearch hard nofile 65536
然后,退出终端,重新使用 elasticsearch 账户登录,启动 Elasticsearch 后,通过浏览器访问 9200 端口,查看 Elasticsearch 状态:
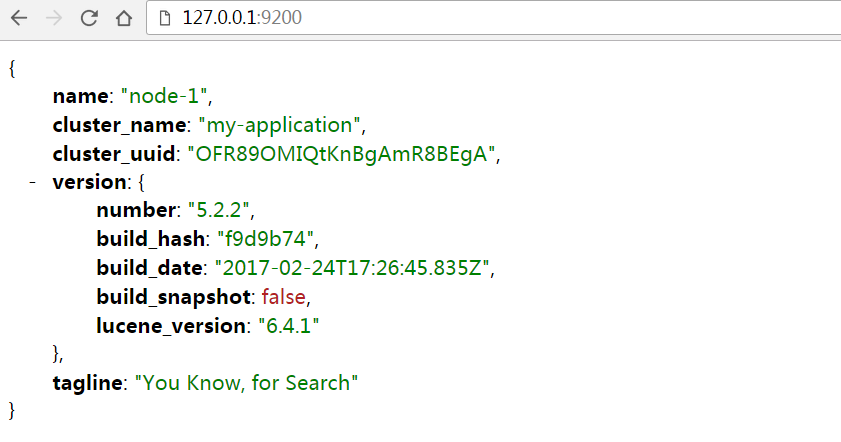
Elasticsearch server
4.1、安装 Cerebro
Cerebro 时一个第三方的 Elasticsearch 集群管理软件,可以方便地查看集群状态:
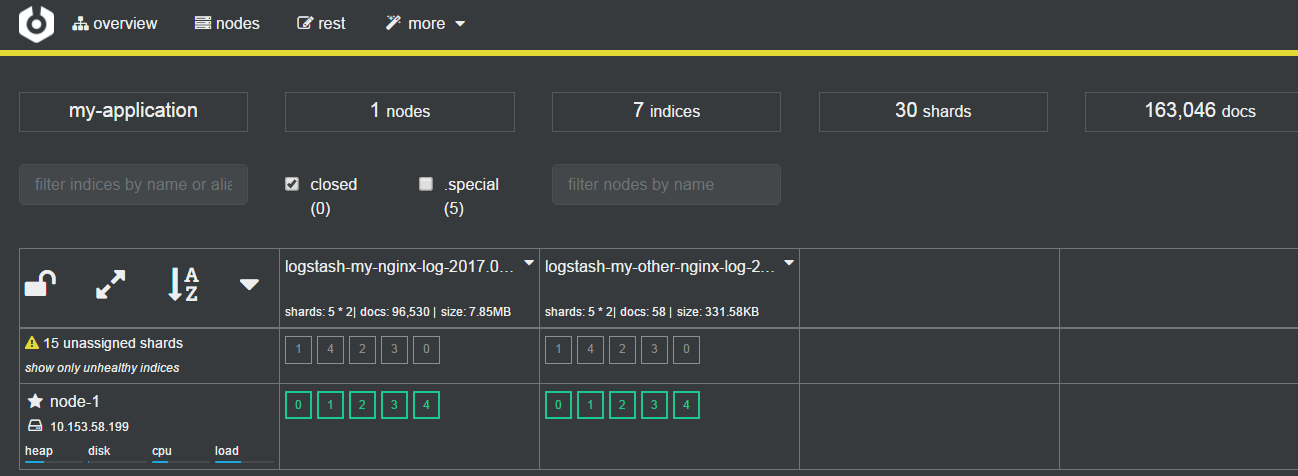
Cerebro 界面
下载地址: github.com/lmenezes/ce…
启动进程后,可以在浏览器查看:
bin/cerebro -Dhttp.port=1234 -Dhttp.address=127.0.0.1
可以在管理后台修改模板,优化索引配置,例如:
关闭备份,节省磁盘空间:"number_of_replicas": "0"
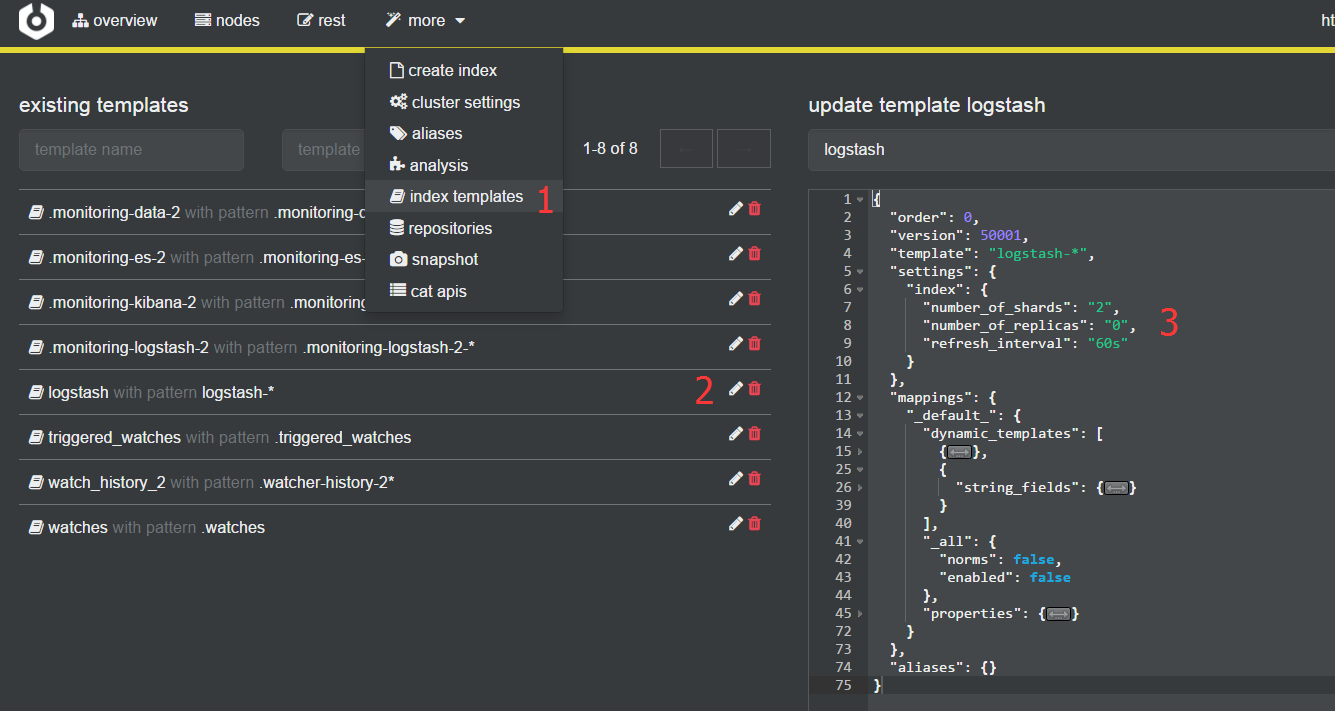
修改索引配置
5、配置并启动 Kibana 服务
本文使用的版本是5.2.2,下载 Kibana ,修改 conf/kibana.yml ,内容为:(详细内容参见本文附录链接)
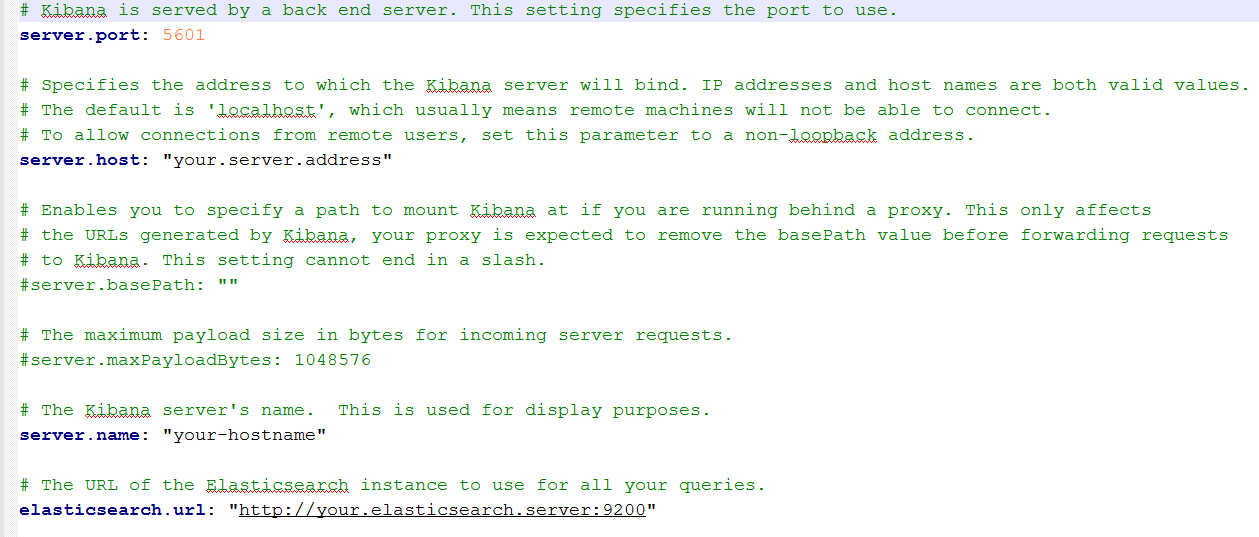
Kibana configuration
安装 x-pack 插件:
bin/kibana-plugin install x-pack
启动 Kibana 进程:
nohup ./bin/kibana &
tips:最好手动退出一下终端
exit
否则,关闭终端后,Kibana 进程可能也停止运行了。
然后,就可以在浏览器访问 Kibana 了:
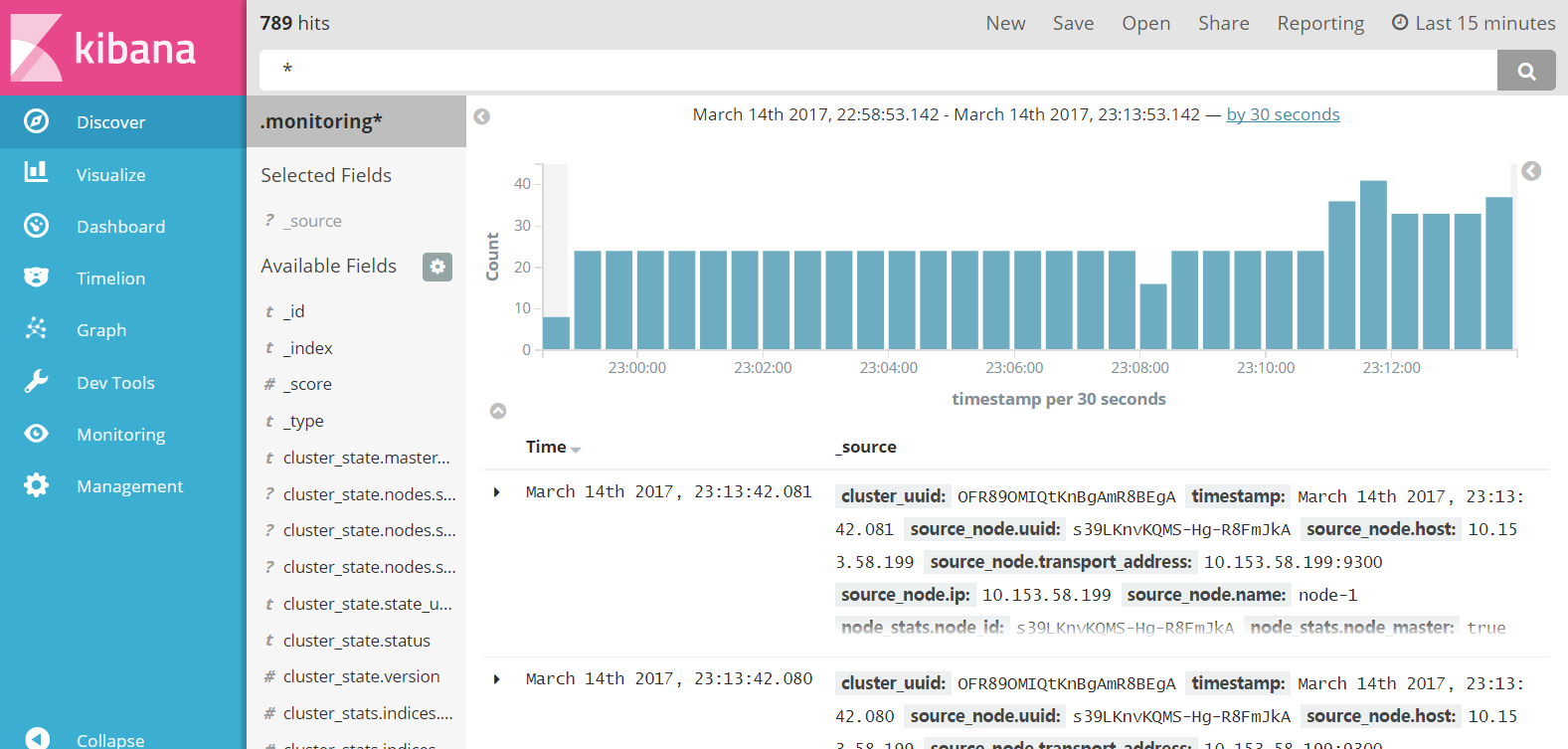
Kibana 界面
注意:
初次访问 Kibana 的时候,需要配置一个默认的 ES 索引,一般填写 .monitoring* 即可,这是因为在上述安装 x-pack 后,会自动开始监控 Elasticsearch 集群的状态,并将监控结果以 .monitoring* 命名索引文件
接下来,就可以使用 Kibana 的可视化功能分析日志了:
Kibana Visualize 功能
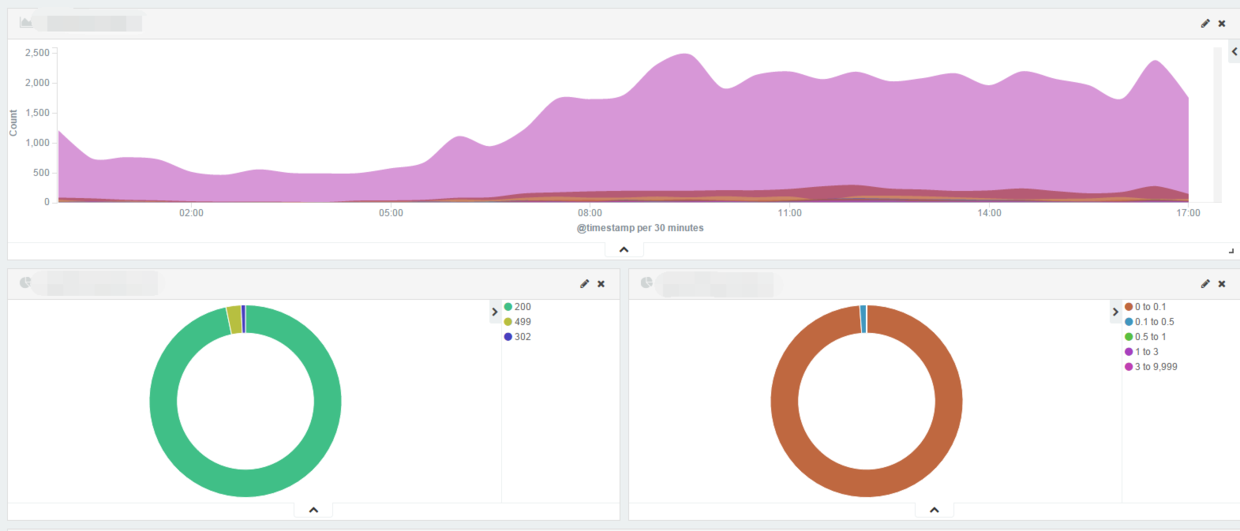
Kibana 可视化数据分析
5.1 分析各个接口的请求量
在 Kibana 管理后台,选择 Visualize >> AreaChart >> logstash-* 索引:
选择 Area chart
选择 logstash-* 索引
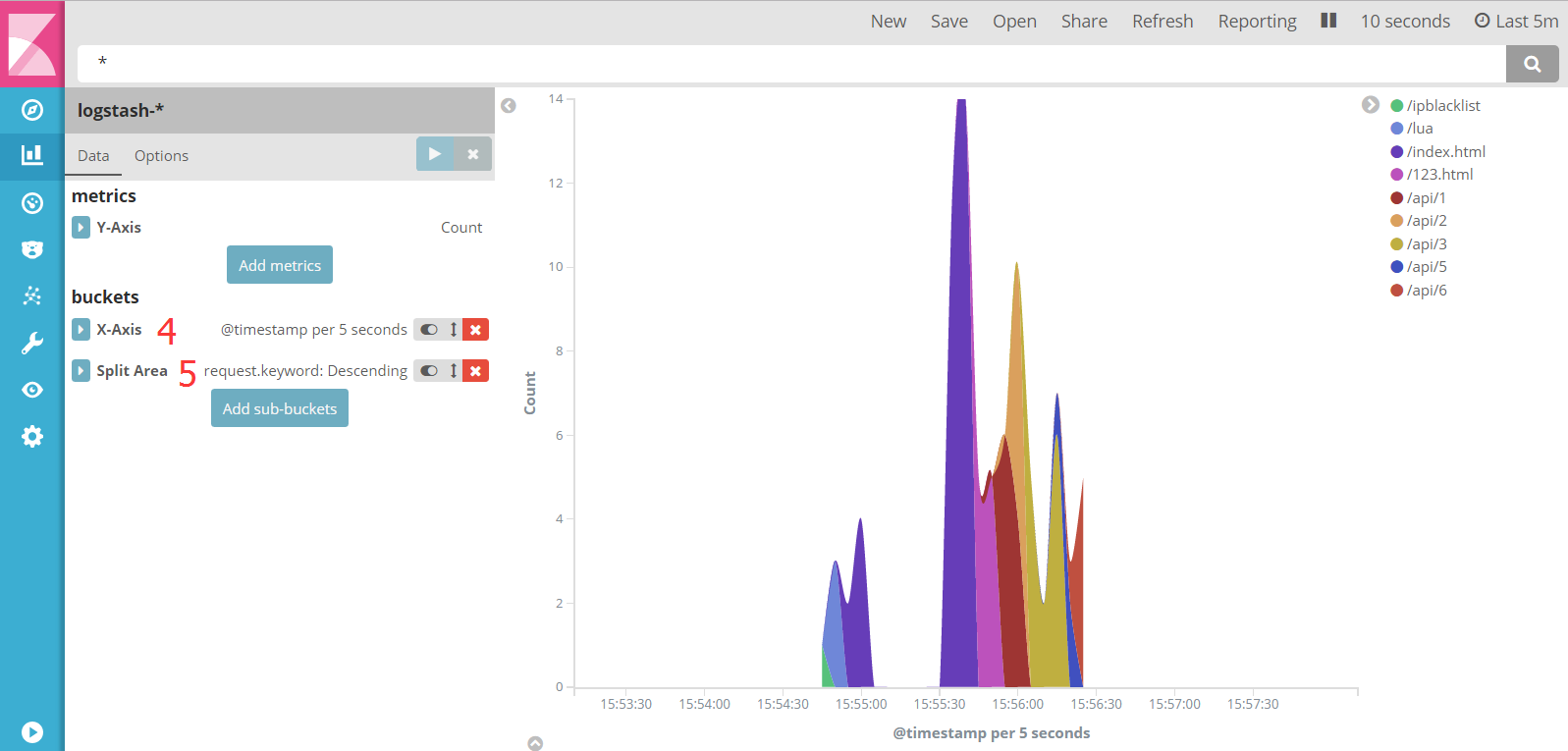
接口请求量分布图
将 x 轴 (X-Axis) 的类型选择为 Date-Histogram,按照参数 request 拆分图形 (Split-Area)
四、总结
综上,我们配置并部署了 ELK Stack 的整套组件,实现了日志收集、过滤、索引和可视化的全部流程,基于这套系统我们就可以实时的分析业务。
五、附录:
1、ELK 各个组件运行过程中会产生大量的日志,所以需要注意日志处理,要么 > /dev/null 全部忽略,要么存储在大磁盘空间,否则可能写满磁盘导致进程被 killed
2、上述安装过程使用的配置文件下载: github.com/Ceelog/elks…
3、通过水平扩展 Kafka、Elasticsearch 集群,可以实现日均几百万到数十亿的日志实时处理
来自:https://juejin.cn/post/6844903469980057608
