

这是系列文章,每篇文章末尾均附有源代码地址。目的是通过模拟集合框架的简单实现,从而对常用的数据结构和
java集合有个大概的了解。当然实现没有java集合的实现那么复杂,功能也没有那么强大,但是可以通过这些简单的实现窥探到底层的一些共性原理。
一.单链表的存储结构
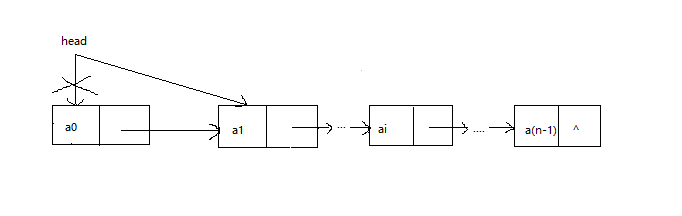
单链表是用若干在地址上面分散的存储单元来存储数据,在逻辑上面相邻的数据元素在物理位置上面不一定相邻。因此,对于每个数据元素本身,除了需要存储自身的元素值之外,还需要一个指向其后继元素的地址。数据元素的结构如下:
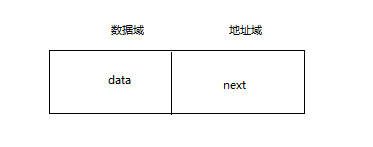
上面的数据元素结构通常称为节点,一个数据元素称为一个节点。它由数据域和地址域组成,其中,data存储数据元素本身的值,称为数据域;next存储后继元素的地址,称为地址域。通过节点的地址域把节点连接起来,单链表的结构如下所示:
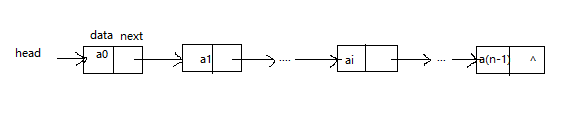
上面的单链表中,head是链表的第一个结点的地址,称为链表的头结点;最后一个节点的地址域为null,用^表示,表示其后不再有节点。从head开始,沿着链表的方向前进,可以遍历单链表中的每个节点。
二.单链表的实现
单链表之间是通过节点链接起来的,所以可以通过定义单链表节点类和单链表类来实现单链表。
1.定义单链表节点类
单链表节点类Node的定义如下所示:
package org.light4j.dataStructure.linearList.linkList;
/**
* 链表节点类
*
* @author longjiazuo
*/
public class Node<E> {
public E data;// 链表数据域,保存数据元素
public Node<E> next;// 链表地址域,引用后继节点
public Node(E data, Node<E> next) {// 构造节点,指定数据元素和后继节点
this.data = data;
this.next = next;
}
public Node(E data) {
this(data, null);
}
public Node() {
this(null, null);
}
}
代码解释:
①
Node类有两个成员变量,data表示节点的数据域,存储数据元素本身的值,数据类型是泛型E;next表示节点的地址域,存储数据元素后继节点的地址。②
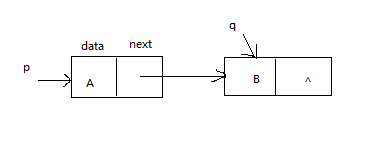
Node类的一个对象表示链表中的一个节点,通过next地址域把节点之间链接起来,p.next=q,如下图所示:
2.定义单链表类
单链表类SinglyLinkedList的定义如下,head成员变量表示单链表的头结点。
package org.light4j.dataStructure.linearList.linkList;
import org.light4j.dataStructure.linearList.LList;
public class SinglyLinkedList<E> implements LList<E> {
protected Node<E> head;// 单链表头结点,指向单链表第一个结点
/**
* 构造空单链表
*/
public SinglyLinkedList() {
this.head = null;
}
/**
* 构造指定头结点的单链表
*
* @param head
*/
public SinglyLinkedList(Node<E> head) {
this.head = head;
}
}
代码解释:
① 单链表
SinglyLinkedList类实现接口LList,所以必须实现该接口的相关方法,具体实现在下面会拆分列出。② 定义了两个构造函数,一个默认的构造函数,指定单链表的头结点为空。另一个构造函数可以指定单链表的头结点。
3. 判断单链表是否为空
/**
* 判断单链表是否为空
*/
@Override
public boolean isEmpty() {
return this.head == null;
}
4. 求单链表的长度
/**
* 遍历单链表返回单链表长度
*/
@Override
public int length() {
Node<E> p = this.head;// p从head指向的节点开始
int i = 0;
while (p != null) {// 若单链表未结束
i++;
p = p.next;// p到达后继节点
}
return i;
}
代码解释:
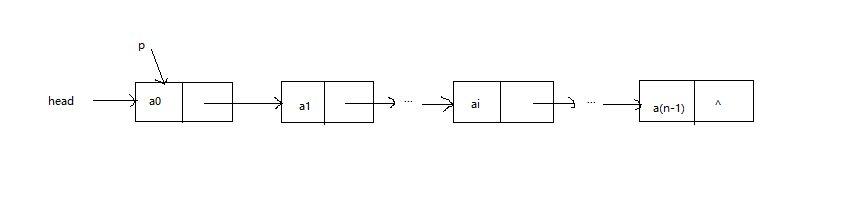
① 求单链表的长度需要遍历单链表。遍历单链表是指从单链表的第一个结点开始,沿着结点链的方向,依次访问单链表中的每一个节点,并且每个节点只能访问一次。遍历过程如下图所示:
② 遍历单链表的时候不应该改变单链表的头结点,所以需要定义一个变量p指向当前节点,p从head所指向的节点开始,依次访问每个节点,直到最后一个节点,这样就完成一次遍历操作。
5. 获取单链表指定索引处的对象
/**
* 返回序号为index的的对象,如果链表为空或者序号错误则返回null
*/
@Override
public E get(int index) {
Node<E> p = this.head;
int i = 0;
while (p != null && i < index) {
i++;
p = p.next;
}
if (p != null) {
return p.data;
}
return null;
}
代码解释:
① 获取单链表指定索引处的对象需要遍历单链表找到该索引,其实就是单链表的遍历操作。
6. 为单链表指定索引处的对象赋值
/**
* 设置序号为index的对象的值为element,如果操作成功则返回原对象,操作失败返回null
*/
@Override
public E set(int index, E element) {
if (this.head != null && index >= 0 && element != null) {
Node<E> p = this.head;
int i = 0;
while (p != null && i < index) {
i++;
p = p.next;
}
if (p != null) {
E old = p.data;
p.data = element;
return old;// 操作成功返回原对象
}
}
return null;// 操作失败则返回null
}
① 为单链表指定索引赋值,需要先遍历单链表找到该索引,然后赋值,其实也就是单链表的遍历操作。
7. 单链表的插入
对单链表进行插入操作非常方便,只需要改变节点间的链接关系即可,不需要移动元素。代码如下:
/**
* 插入elment元素,插入后对象序号为index,如果操作成功则返回true
*/
@Override
public boolean add(int index, E element) {
if (element == null) {
return false;
}
Node<E> q = new Node<E>(element);// 创建要插入的结点
if (this.head == null || index <= 0) {// 在头结点后面插入
q.next = this.head;
this.head = q;
} else {// 中间或者尾结点后面插入
Node<E> p = this.head;
int i = 0;
while (p.next != null && i < index - 1) {// 寻找插入位置
i++;
p = p.next;
}
q.next = p.next;// q插入在p结点之后
p.next = q;
}
return true;
}
/**
* 在单链表最后插入对象
*/
@Override
public boolean add(E element) {
return add(Integer.MAX_VALUE, element);
}
代码解释:
单链表中插入一个节点,根据插入的位置可以分为空表插入,头插入,中间插入,尾插入四种情况。
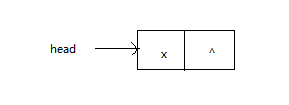
① 空表插入和头插入
1.1 空表插入
空表插入是指单链表为空,插入一个节点,head指向被插入的节点。如下图所示:
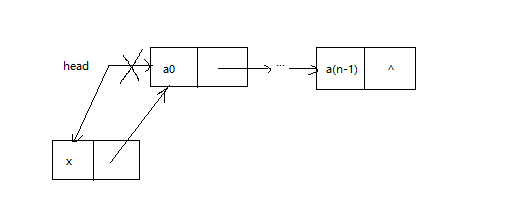
1.2 头插入
头插入是指如果单链表非空,在head节点之前插入节点q,插入后q节点成为单链表的第一个节点,head节点指向该节点。如下图所示:
这两种插入都将改变单链表的头结点head的指向。语句如下:
if(head==null){
head=new Node(x);
}else{
Node q = new Node(x);
q.next=head;
head=q;
}② 中间插入/尾插入
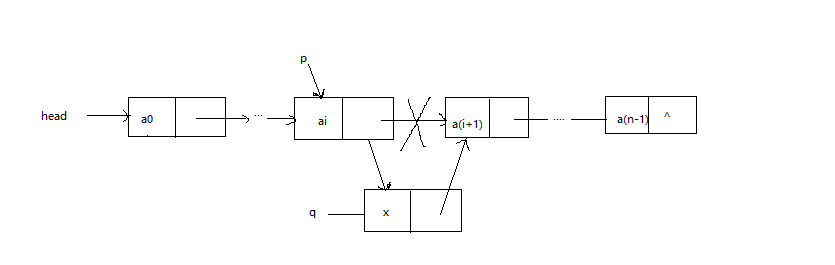
2.1 中间插入
中间插入是指把要插入的节点插入非空链表中间某节点的后面。如下图所示:
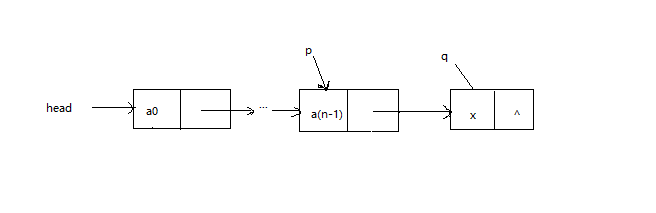
2.2 尾插入
尾插入是指把要插入的节点插入单链表当前尾节点的后面,成为新的尾节点。如下图所示:
这两种插入不会改变单链表的头结点head的指向。设p指向非空链表中的某个结点(也可能是链表的最后一个结点),在p结点之后插入q结点的语句如下:
Node q = new Node(x);
q.next=p.next;
p.next=q;
8. 单链表的删除
在单链表中删除节点只需要改变某些链接,不需要移动节点数据元素。根据被删除元素节点的位置,可以分为头删除,中间删除,尾删除三种情况。代码如下:
/**
* 移除序号为index的对象,如果操作成功则返回被移除的对象,操作失败则返回null
*/
@Override
public E remove(int index) {
E old = null;
if (this.head != null && index >= 0) {
if (index == 0) {// 头删除
old = this.head.data;
this.head = this.head.next;
return old;
} else {// 中间删除或者尾删除
Node<E> p = this.head;
int i = 0;
while (p != null && i < index - 1) {// 定位到待删除节点的前驱节点
i++;
p = p.next;
}
if (p != null && p.next != null) {
old = p.next.data;// 操作成功返回被移去对象
p.next = (p.next).next;// 删除p的后继节点
}
}
}
return old;
}
代码解释:
① 头删除
头删除如下图所示:
删除单链表第一个节点,只需要使head节点指向其后继节点即可。实现语句如下所示:
head=head.next;
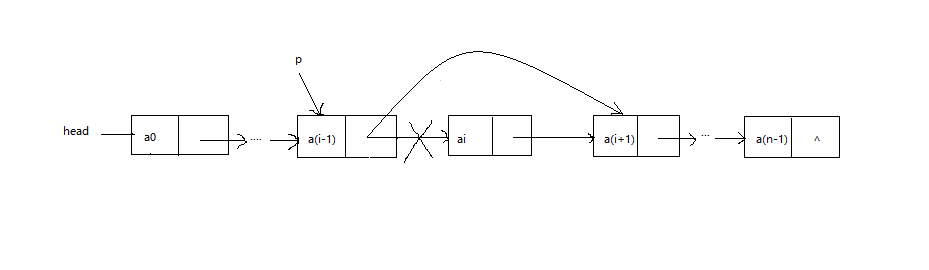
单链表如果只有一个结点,那么删除该节点之后单链表为空表,也即执行上面的语句之后,head变为null。② 中间删除或者尾删除
中间删除或者尾删除如下图所示:
中间删除指删除单链表中间的某个节点,尾删除指删除单链表的最后一个节点。设p指向单链表中最后一个结点之外的其他结点,删除p的的后继结点的语句如下所示:
if(p.next != null){
p.next = p.next.next;
}
Java的垃圾回收机制会自动释放不再使用的对象,回收其占用的内存空间,因而我们不需要写释放被删除节点存储单元的代码。
9. 清空单链表
@Override
public void clear() {// 清空单链表
this.head = null;
}
代码解释:
① 单链表的清空只需要把单链表的头结点
head置为null即可。
10. 重写toString()方法
@Override
public String toString() {// 返回所有元素值对应的字符串
String str = "(";
Node<E> p = this.head;
while (p != null) {
str += p.data.toString();
p = p.next;
if (p != null) {
str += ", ";
}
}
return str + ")";
}
三.测试
测试代码如下所示:
package org.light4j.dataStructure.linearList.linkList;
import org.light4j.dataStructure.linearList.LList;
public class Test {
public static void main(String[] args) {
LList<String> linkedList = new SinglyLinkedList<String>();
// 添加A,B,C三个元素
linkedList.add("A");
linkedList.add("B");
linkedList.add("C");
// 输出元素个数
System.out.println("元素个数是:"+linkedList.length());
}
}
运行效果如下图所示:

四.单链表操作效率分析
单链表是顺序存取结构,不是随机存取结构,所以访问单链表的某个节点,必须从头结点head开始沿着链表的方向逐个节点查找,所以get()和set()方法的时间复杂度是O(n)。
isEmpty()方法的时间复杂度是O(1);length()方法要遍历整个单链表,所以时间复杂度是O(n)。
在单链表的指定节点之后插入节点非常方便,时间复杂度是O(1)。如果需要在指定单链表的指定节点之前插入节点,那么首先需要找到指定节点的前驱节点,然后将该节点插入到该节点之后,这个操作需要遍历部分单链表,花费的时间依据插入的位置来定,最坏情况是将节点插入在链表最后,时间复杂度是O(n)。
在单链表中删除一个指定节点同样要从head开始查找它的前驱节点,最坏情况的时间复杂度是O(n)。
对单链表进行插入和删除操作,不需要移动节点,只需要改变节点的链接即可。单链表的存储空间是在插入和删除过程中动态申请和释放的,不需要预先给单链表申请存储空间,从而避免了单链表因存储空间不足需要扩充空间和复制元素的过程,提高了运行效率和储存空间的利用率。
另外,如果在单链表中增加某些成员变量可以提高某些操作的操作效率。例如,增加成员变量n表示单链表的长度,当插入一个元素时,同时进行n++操作;当删除一个元素时,同时进行n--操作,则可使length()方法的时间复杂度为O(1)。同样,如果增加成员变量rear作为单链表的尾节点,指向单链表的最后一个节点,则在单链表最后进行插入操作的时间复杂度是O(1)。
五.源代码示例
打赏
 微信扫一扫,打赏作者吧~
欢迎关注人生设计师的微信公众账号
微信扫一扫,打赏作者吧~
欢迎关注人生设计师的微信公众账号公众号ID:longjiazuoA

未经允许不得转载:人生设计师 » 自己实现集合框架(三):单链表的实现
