

前言
HashMap是我们平时很常用到的集合,但它是非线程安全的,解决方案有Hashtable和Collections.synchronizedMap(hashMap),然而这两种方式太过低效,所以Doug Lea为我们设计了既线程安全性能也相对优秀的ConcurrentHashMap类.下面我们一起学习.
介绍
在jdk1.8中ConcurrentHashMap利用CAS+ Synchronized来确保线程安全,它的底层数据结构依然是数组+链表+红黑树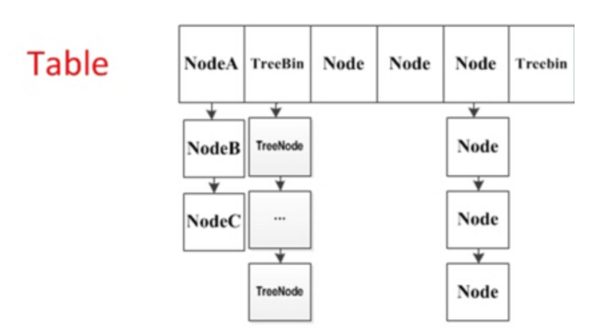 在开始之前先介绍几个概念:
在开始之前先介绍几个概念:  在开始之前先介绍几个概念:
在开始之前先介绍几个概念:
- transient volatile Node<K,V>[] table; 链表数组,默认为空,初始化操作延迟到了第一次执行put,默认大小16 ,执行扩容后,总为2的n次幂
- sizeCtl:默认为0,用来控制table的初始化和扩容操作.它的数值有以下含义
- -1 :代表table正在初始化,其他线程应该交出CPU时间片,退出
- -N: 表示正有N-1个线程执行扩容操作
- >0: 如果table已经初始化,代表table容量,默认为table大小的0.75,如果还未初始化,代表需要初始化的大小
- Node 保存键值对的节点
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next;public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
上面提到,初始化操作发生在第一次put操作,那么多个线程执行put时,如何保证只执行一次初始化呢?先看put方法
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
//开始执行插入操作
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果table为空,执行初始化操作
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//table[i]为空,用CAS在table[i]头结点直接插入,退出插入操作;如果CAS失败,则有其他节点已经插入,继续下一步
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果table[i]不为空,且table[i]的hash值为-1,则有其他线程在执行扩容操作,帮助他们一起扩容,提高性能
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//如果没有在扩容
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
//fh(table[i])的hash>=0,则此时table[i]为链表结构,找到合适位置插入
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//fh(table[i])的hash<0,table[i]为红黑树结构,这个过程采用同步内置锁实现并发
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}//到此时,已将键值对插入到了合适的位置,检查链表长度是否超过阈值,若是,则转变为红黑树结构
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//count+1,如有必要,则扩容
addCount(1L, binCount);
return null;
}
现在对put(putVal)方法做一个总结:
- 如果待插入的键值对中key或value为null,抛出异常,结束.否则执行2
- 如果table为null,则进行初始化操作initTable(),否则执行3
- 如果table[i]为空,则用CAS在table[i]头结点直接插入,如果CAS执行成功,退出插入操作;执行步骤7;如果CAS失败,则说明有其他节点已经插入,执行4
- 此时判断,hash值是否为MOVED(-1),如果是则说明其他有其他线程在执行扩容操作,帮助他们一起扩容,来提高性能.如果没有在扩容,那么执行5
- 判断hash的值,,如果>=0,则在链表合适的位置插入,否则,查看table[i]是否是红黑树结构,如果是,则在红黑树适当位置插入.到此时,键值对已经顺利插入.接下来执行6
- 如果table[i]节点数binCount不为0,判断它此时的状态,是否需要转变为红黑树
- 执行addcount(1L, binCount)
接下来我们一起看看上面提到的初始化操作
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
}如果sizeCtl<0,则说明已经有线程在执行初始化,则其他执行初始化方式的线程应当交出CPU时间片退出;否则,用CAS把sizeCtl设置为-1,告诉其他线程,自己正在执行初始化,此时段其他进入初始化方法的线程将交出时间片.
接下来我们看看求hash的函数spread(key.hashCode())
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
table扩容
当table容量>= sizeCtl时,执行扩容操作:
- 构建一个nextTable,大小为table的两倍
- 把table的数据复制到nextTable中。这步可以让多个线程协助进行
红黑树构造
当链表长度超过8时,转变为红黑树
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
由上可知:并非一开始就构造红黑树,如果当前Node数组长度小于阈值MIN_TREEIFY_CAPACITY,默认为64,先通过扩大数组容量为原来的两倍以缓解单个链表元素过大的性能问题。否则,才执行构造操作(过程1.2是同步的):
1、根据table中index位置Node链表,重新生成一个hd为头结点的TreeNode链表。
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
2、根据hd头结点,生成TreeBin树结构,并把树结构的root节点写到table的index位置的内存中,关于红黑树的具体操作,请阅读 深入学习红黑树
get方法
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
如果table[i].key与key相同,则返回,否则从红黑树或者链表中找到并返回,否则return null.
