

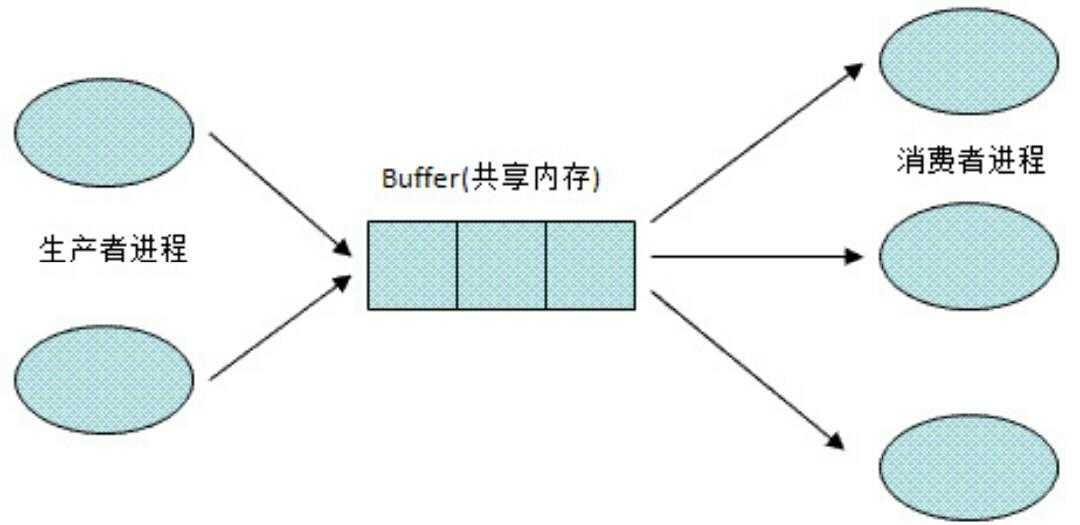
由于工作原因,最近碰上一个大数据量的操作(主要的操作是生成上亿条测试数据,提交到索引服务器上),程序慢到不可接受。于是想办法让程序快起来。
说到Java的多线程编程,首先想到继承Thread,重写run方法,新建一个Thread对象,调用start方法。
线程
package com.github.yfor.bigdata.tdg;
/**
* Created by wq on 2017/5/14.
*/
public class TestThread extends Thread {
public TestThread() {
}
public void run() {
}
public static void main(String[] args) {
TestThread tt= new TestThread();
tt.start();
//一些操作
}
}这种方式,已经是并发了,对于线程的生命周期,join ,yield等方法这里就不讲了,还是找本书去看比较靠谱。很多同志多线程的学习到这里可能就结束了。
最原始的方式有一些问题,竟然很多人在生产环境使用,还一脸的自豪感(我也是这样过)。要新建多少线程?管他呢。 如果一直创建线程会大量抢占资源。当然有点经验的同志会建议使用线程池。
线程池的用法。
// Executors.newCachedThreadPool(); //创建一个缓冲池,缓冲池容量大小为Integer.MAX_VALUE
// Executors.newSingleThreadExecutor(); //创建容量为1的缓冲池
// Executors.newFixedThreadPool(int); //创建固定容量大小的缓冲池
class MyTask implements Runnable {
public MyTask() {
}
@Override
public void run() {
//do something
}
}
ExecutorService executor = Executors.newFixedThreadPool(5)
MyTask myTask = new MyTask();
executor.execute(myTask);对于单次提交数据的数量,当然单次数量越少越快,但是次数会变多,总体时间会变长,单次提交过多,执行会非常慢,以至于可能会失败,经过多次测试数据量在几千到一万时是比较能够接受的。
选择那种线程池呢,是固定大小的,还是无限增长的。当线程数量超过限制时会如何呢?这几种线程池都会抛出异常。
有一定经验的同志会不屑的说阻塞的线程池,基本就比较靠谱,例如加上等待队列,等待队列用一个阻塞的队列。小的缺点是一直创建线程,感觉也不是非常的合理。
带队列的线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue(5));由于前几天正好看到多线程的书籍,突然想起了,我的程序明显可以使用生产者消费者模式,于是对程序进行了改进。
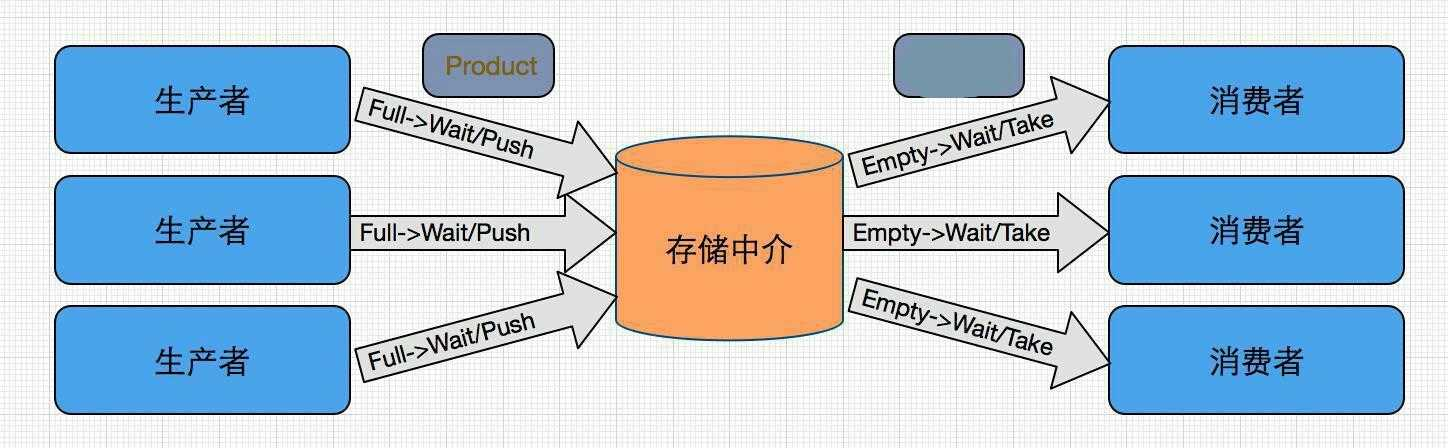
主程序
package com.github.yfor.bigdata.tdg;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* Created by wq on 2017/5/14.
*/
public class Main {
public static void main(String[] args) throws InterruptedException {
int threadNum = Runtime.getRuntime().availableProcessors() * 2;
ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<String>(100);
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < threadNum; i++) {
executor.execute(new Consumerlocal(queue));
}
Thread pt = new Thread(new Producerlocal(queue));
pt.start();
pt.join();
for (int i = 0; i < threadNum; i++) {
queue.put("poisonpill");
}
executor.shutdown();
executor.awaitTermination(10L, TimeUnit.DAYS);
}
}生产者
package com.github.yfor.bigdata.tdg;
import java.util.concurrent.ArrayBlockingQueue;
/**
* Created by wq on 2017/5/14.
*/
public class Producerlocal implements Runnable {
ArrayBlockingQueue<String> queue;
public Producerlocal(ArrayBlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
try {
for (int i = 0; i < 1000; i++) {
queue.put("s" + i);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}消费者
package com.github.yfor.bigdata.tdg;
import java.util.concurrent.ArrayBlockingQueue;
/**
* Created by wq on 2017/5/14.
*/
public class Consumerlocal implements Runnable {
ArrayBlockingQueue<String> queue;
public Consumerlocal(ArrayBlockingQueue<String> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
final String take = queue.take();
if ("poisonpill".equals(take)) {
return;
}
//do something
System.out.println(take);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}程序使用了阻塞队列,队列设置一定的大小,加入队列超过数量会阻塞,队列空了取值也会阻塞,感兴趣的同学可以查看jdk源码。消费者线程数是CPU的两倍,对于这些类的使用需要查看手册和写测试代码。对于何时结束线程也有一定的小技巧,加入足够数量的毒丸。
对于代码使用了新的模式,程序明显加快了,到这里生产者消费者模式基本就结束了。如果你下次想起你的程序也需要多线程,正好适合这种模式,那么套用进来就是很好的选择。当然你现在能做的就是撸起袖子,写一些测试代码,找到这种模式的感觉。
因为程序的大多数时间还是在http请求上,程序的运行时间仍然不能够接受。于是想到了利用异步io加快速度,而不用阻塞的http。但是问题是这次的http客户端为了安全验证进行了修改,有加密验证和单点登录,新的客户端能适配起来有一定难度估计需要一定的时间,还是怕搞不定。异步的非阻塞io,对于前面数据结果选择的经验,非阻塞不一定就是好!其实是没太看懂怎么在多线程中使用,而对于所得到的效果就不得而知了。
maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpasyncclient</artifactId>
<version>4.1.3</version>
</dependency>异步http
/*
* ====================================================================
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
* ====================================================================
*
* This software consists of voluntary contributions made by many
* individuals on behalf of the Apache Software Foundation. For more
* information on the Apache Software Foundation, please see
* <http://www.apache.org/>.
*
*/
package com.github.yfor.bigdata.tdg;
import org.apache.http.HttpHost;
import org.apache.http.HttpRequest;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.nio.client.CloseableHttpPipeliningClient;
import org.apache.http.impl.nio.client.HttpAsyncClients;
import org.apache.http.nio.IOControl;
import org.apache.http.nio.client.methods.AsyncCharConsumer;
import org.apache.http.nio.protocol.BasicAsyncRequestProducer;
import org.apache.http.protocol.HttpContext;
import java.io.IOException;
import java.nio.CharBuffer;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Future;
/**
* This example demonstrates a pipelinfed execution of multiple HTTP request / response exchanges
* with a full content streaming.
*/
public class MainPhttpasyncclient {
public static void main(final String[] args) throws Exception {
CloseableHttpPipeliningClient httpclient = HttpAsyncClients.createPipelining();
try {
httpclient.start();
HttpHost targetHost = new HttpHost("httpbin.org", 80);
HttpGet[] resquests = {
new HttpGet("/"),
new HttpGet("/ip"),
new HttpGet("/headers"),
new HttpGet("/get")
};
List<MyRequestProducer> requestProducers = new ArrayList<MyRequestProducer>();
List<MyResponseConsumer> responseConsumers = new ArrayList<MyResponseConsumer>();
for (HttpGet request : resquests) {
requestProducers.add(new MyRequestProducer(targetHost, request));
responseConsumers.add(new MyResponseConsumer(request));
}
Future<List<Boolean>> future = httpclient.execute(
targetHost, requestProducers, responseConsumers, null);
future.get();
System.out.println("Shutting down");
} finally {
httpclient.close();
}
System.out.println("Done");
}
static class MyRequestProducer extends BasicAsyncRequestProducer {
private final HttpRequest request;
MyRequestProducer(final HttpHost target, final HttpRequest request) {
super(target, request);
this.request = request;
}
@Override
public void requestCompleted(final HttpContext context) {
super.requestCompleted(context);
System.out.println();
System.out.println("Request sent: " + this.request.getRequestLine());
System.out.println("=================================================");
}
}
static class MyResponseConsumer extends AsyncCharConsumer<Boolean> {
private final HttpRequest request;
MyResponseConsumer(final HttpRequest request) {
this.request = request;
}
@Override
protected void onResponseReceived(final HttpResponse response) {
System.out.println();
System.out.println("Response received: " + response.getStatusLine() + " -> " + this.request.getRequestLine());
System.out.println("=================================================");
}
@Override
protected void onCharReceived(final CharBuffer buf, final IOControl ioctrl) throws IOException {
while (buf.hasRemaining()) {
buf.get();
}
}
@Override
protected void releaseResources() {
}
@Override
protected Boolean buildResult(final HttpContext context) {
System.out.println();
System.out.println("=================================================");
System.out.println();
return Boolean.TRUE;
}
}
}虽然可以放在服务器上进行运行,减少io,发挥16核CPU的威力( 多消费者线程 ),但还是不理想。
后来找同事请教,我的程序还是单机版,而我们接收服务器是集群的形式,程序改成了从zookeeper查询服务器集群多个节点的IP进行发送请求( 多消费者接收节点 ),而且在请求参数中加大提交时间,进行软提交,而不是实时的commit,程序至此明显加快,达到了可以接受范围。
我们还有一版的程序是利用kafak,这个分布式队列,将我们的生产者消费者进行到底。
配置
package com.github.yfor.bigdata.tdg;
/**
* Created by wq on 2017/4/29.
*/
public interface KafkaProperties {
final static String zkConnect = "localhost:2181";
final static String groupId = "group21";
final static String topic = "topic4";
final static String kafkaServerURL = "localhost";
final static int kafkaServerPort = 9092;
final static int kafkaProducerBufferSize = 64 * 1024;
final static int connectionTimeOut = 20000;
final static int reconnectInterval = 10000;
final static String clientId = "SimpleConsumerDemoClient";
}kafka的配置需要一定的时间,可以阅读官方文档进行安装并运行。
生产者线程
package com.github.yfor.bigdata.tdg;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class Producer extends Thread {
private final KafkaProducer<Integer, String> producer;
private final String topic;
private final Boolean isAsync;
private final int size;
public Producer(String topic) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093");
props.put(ConsumerConfig.CLIENT_ID_CONFIG, "DemoProducer");
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<Integer, String>(props);
this.topic = topic;
this.isAsync = true;
this.size = producer.partitionsFor(topic).size();
}
@Override
public void run() {
int messageNo = 1;
while (messageNo < 100) {
try {
sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String messageStr = "Message_" + messageNo;
long startTime = System.currentTimeMillis();
if (isAsync) { // Send asynchronously 异步
producer.send(new ProducerRecord<>(topic, messageNo % size, messageNo, messageStr),
new DemoCallBack(startTime, messageNo, messageStr));
} else { // Send synchronously 同步
try {
producer.send(new ProducerRecord<>(topic, messageNo, messageStr)).get();
System.out.println("Sent message: (" + messageNo + ", " + messageStr + ")");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
++messageNo;
}
}
}
class DemoCallBack implements Callback {
private final long startTime;
private final int key;
private final String message;
public DemoCallBack(long startTime, int key, String message) {
this.startTime = startTime;
this.key = key;
this.message = message;
}
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
long elapsedTime = System.currentTimeMillis() - startTime;
if (metadata != null) {
System.out.println(
"message(" + key + ", " + message + ") sent to partition(" + metadata.partition() +
"), " +
"offset(" + metadata.offset() + ") in " + elapsedTime + " ms");
} else {
exception.printStackTrace();
}
}
}消费者线程
package com.github.yfor.bigdata.tdg;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaConsumer extends Thread {
private final ConsumerConnector consumer;
private final String topic;
private final int size;
public KafkaConsumer(String topic) {
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
this.topic = topic;
this.size = 5;
}
private static ConsumerConfig createConsumerConfig() {
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
try {
sleep(2000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(size));
ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic);
ExecutorService executor = Executors.newFixedThreadPool(size);
for (final KafkaStream stream : streams) {
executor.submit(new KafkaConsumerThread(stream));
}
}
}
class KafkaConsumerThread implements Runnable {
private KafkaStream<byte[], byte[]> stream;
public KafkaConsumerThread(KafkaStream<byte[], byte[]> stream) {
this.stream = stream;
}
public void run() {
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
MessageAndMetadata<byte[], byte[]> mam = it.next();
System.out.println(Thread.currentThread().getName() + ": partition[" + mam.partition() + "],"
+ "offset[" + mam.offset() + "], " + new String(mam.message()));
}
}
}这里的示例代码借鉴了几篇博客中的写法,能够实现多个消费者的处理。
生产者客户端
package com.github.yfor.bigdata.tdg;
public class MainP {
public static void main(String[] args) {
Producer producerThread = new Producer(KafkaProperties.topic);
producerThread.start();
}
}消费者客户端
package com.github.yfor.bigdata.tdg;
public class MainC {
public static void main(String[] args) {
KafkaConsumer consumerThread = new KafkaConsumer(KafkaProperties.topic);
consumerThread.start();
}
}示例代码为了容易理解,减少了代码量,去除了相关的业务逻辑,希望大家能看到通用的模式设计,而不是看到玩具的模式。建议大家进行测试执行实验,把分布式消息队列加入到自己的工具箱,对求职的竞争力也有一定的提升。
如果不是很理解,也不用担心,因为对于其中的部分细节我也没有很好的掌握,经过应用才感觉能有一点体会。
参考资料
- 七周七并发模型
- solr参考手册
- http异步客户端文档
- kafak官网文档
- 网上的文章
