

事件概述
北京时间5月12日晚开始,名为Wanna Decrypt0r的蠕虫勒索软件爆发,袭击全球网络,目前已有近百个国家的用户受到攻击。 Wanna Decrypt0r会加密受害者计算机中的文件,需要支付比特币赎金,才可以解密还原文件。国内高校教育网成为重灾区,其他行业如一些政府和企业内网也受到影响。
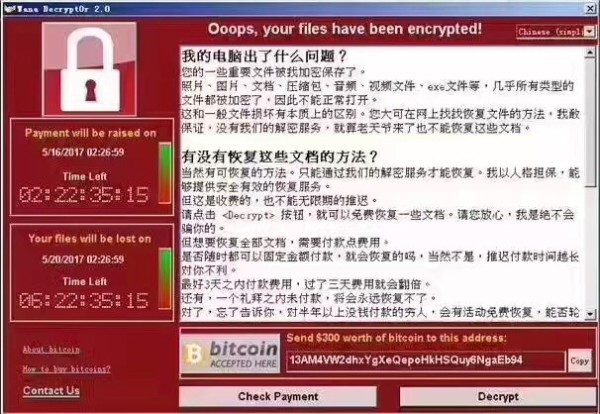
Wanna Decrypt0r勒索软件是什么?
• Wanna Decrypt0r通过加密受害计算机中的数据文件,向受害者敲诈金钱(使用比特币形式),这种加密强度非常大,所以除非有对应的解密工具,否则基本不可能成功解密。
• 该勒索软件带有蠕虫传播性质,可以通过MS17-010漏洞来自动攻击和感染同一网络上的其他Windows计算机。
事件时间轴
- 2016 年 8 月,一个名为“Shadow Brokers” 的黑客组织声称入侵了另一个黑客组织Equation Group(译名:方程式组织),方程式组织据称是NSA(美国国家安全局)下属的黑客组织,其所拥有的技术无论是从复杂程度还是从其先进程度来看,都已经超越了目前绝大多数的黑客团体,该黑客组织已经持续活跃了二十多年。Shadow Brokers在互联网上放出了大量的据称是NSA用于网络监控和攻击的工具程序,同时还保留了部分文件,打算公开拍卖。
- 2017 年 4 月 8 日,“Shadow Brokers” 公布了保留部分的一部分解压密码。
- 2017 年 4 月 14 日,“Shadow Brokers”放出了第二波保留文件,包括新的23个黑客工具,其中一个工具利用了微软的MS17-010漏洞,也就是本次Wanna Decrypt0r勒索软件所使用的漏洞。
- 2017 年 4 月 14 日当天,微软MSRC发布公告,声明大部分的漏洞均已修复发布对应补丁,其中MS07-010是在3月份的补丁中已经修复。
- 2017年5月12日,利用MS17-010漏洞的Wanna Decrypt0r勒索软件爆发,截至目前已经有接近100个国家的用户受到攻击。
还没有中招,我该做什么预防?
- 如果你使用的是正版操作系统,打补丁是最好的选择。微软已经在3月份发布了该漏洞的补丁,使用自动更新安装即可。根据最新消息,微软在北京时间今天(5月13日)刚刚决定,为已经停止维护的Windows XP和部分服务器版本Windows Server 2003发布针对本次攻击的特别安全补丁。
- 如果你使用的是盗版操作系统,不支持自动更新,可以尝试使用各类第三方安全软件安装补丁。
- 如果你确实无法安装补丁,比如安装补丁后会死机,无法启动之类的,使用windows自带的系统防火墙关闭445端口的访问。具体步骤可以根据自己的操作系统版本,参考一些网上教程,例如jingyan.baidu.com/article/d62…。看了教程也不知道怎么操作的同学,可以使用一些安全公司推出的免疫工具,例如: t.cn/RX6FcHb
- 对于企业服务器用户,除了安装补丁外,在确保业务不需要使用445端口后,还可以使用防火墙关闭445端口的访问。使用了第三方安全服务或产品的企业,可以咨询为您提供安全服务或产品的公司。
- 使用国内公有云(阿里云,UCloud等)的用户,由于国内此前爆发过多次利用139,445等端口传播的蠕虫事件,运营商已经封锁了445端口(没有封锁的教育网和各企业内网成为了
由来
知乎上的一个问题:Django 分表 怎么实现?
这个问题戳到了Django ORM的痛点,对于多数据库/分库的问题,Django提供了很好的支持,通过using和db router可以很好的完成多数据库的操作。但是说到分表的问题,就有点不那么友好了。但也不是那么难处理,只是处理起来不太优雅。
解析
在Django中,数据库访问的逻辑基本上是在Queryset中完成的,一个查询请求,比如:
User.objects.filter(group_id=10)。其中的
objects其实就是models.Manager,而Manager又是对QuerySet的一个包装。而QuerySet又是最终要转换为sql的一个中间层(就是ORM种,把Model操作转换为SQL语句的部分)。所以当我们写下User.objects的时候,就已经确定了要访问的是哪个表了,这是由class Meta中的db_table决定的。class User(models.Model): username = models.CharField(max_length=255) class Meta: db_table = 'user'理论上讲,我们可以通过在运行时修改db_table来完成分表CRUD的逻辑,但是the5fire在看了又看源码之后,还是没找到如何下手。还是上面的问题,当执行到
User.objects的时候,表已经确定了,当执行到User.objects.filter(group=10)的时候只不过是在已经生成好的sql语句中增加了一个where部分语句。所以并没有办法在执行filter的时候来动态设置db_table。对于问题中说的get也是一样,因为get本身就是在执行完filter之后从_result_cache列表中获取的数据(_result_cache[0])。
方案一
根据the5fire上面的分析,要想在执行具体查询时修改db_table已经是不可能了(当然,如果你打算去重写Model中Meta部分的逻辑以及Queryset部分的逻辑,就当我没说,我只能表示佩服)。
所以只能从定义层面下手了。也就是我需要定义多个Model,同样的字段,不同的db_table。大概是这样。
class User(models.Model): username = models.CharField(max_length=255) class Meta: abstract = True class User1(User): class Meta: db_table = 'user_1' # 默认情况下不设置db_table属性时,Django会使用``<app>_<model_name>``.lower()来作为表名 class User2(User): class Meta: db_table = 'user_2'这样在
User.objects.get(id=3)的时候,如果按照模2计算,那就是User01.objects.get(id=3),笨点的方法就是写一个dict:user_sharding_map = { 1: User1, 2: User2 } def get_sharding_model(id): key = id % 2 + 1 return user_sharding_map[key] ShardingModel = get_sharding_model(3) ShardingModel.objects.get(id=3)如果真的这么写那Python作为动态语言,还有啥用,你分128张表试试。我们应该动态创建出User01,User02,....UserN这样的表。
class User(models.Model): @classmethod def get_sharding_model(cls, id=None): piece = id % 2 + 1 class Meta: db_table = 'user_%s' % piece attrs = { '__module__': cls.__module__, 'Meta': Meta, } return type(str('User%s' % piece), (cls, ), attrs) username = models.CharField(max_length=255, verbose_name="the5fire blog username") class Meta: abstract = True ShardingUser = User.get_sharding_model(id=3) user = ShardingUser.objects.get(id=3)嗯,这样看起来似乎好了一下,但是还有问题,id=3需要传两次,如果两次不一致,那就麻烦了。Model层要为上层提供统一的入口才行。
class MyUser(models.Model): # 增加方法 BY the5fire @classmethod def sharding_get(cls, id=None, **kwargs): assert id, 'id is required!' Model = cls.get_sharding_model(id=id) return Model.objects.get(id=id, **kwargs)对上层来书,只需要执行MyUser.sharding_get(id=10)即可。不过这改变了之前的调用习惯
objects.get。不管怎么说吧,这也是个方案,更完美的方法就不继续探究了,在Django的ORM中钻来钻去寻找可以hook的点实在憋屈。
我们来看方案二吧
方案二
ORM的过程是这样的,Model——> SQL ——> Model,在方案一中我们一直在处理Model——> SQL的部分。其实我们可以抛开这一步,直接使用raw sql。
QuerySet提供了raw这样的接口,用来让你忽略第一层转换,但是有可以使用从SQL到Model的转换。只针对SELECT的案例:
class MyUser(models.Model): id = models.IntegerField(primary_key=True, verbose_name='ID') username = models.CharField(max_length=255) @classmethod def get_sharding_table(cls, id=None): piece = id % 2 + 1 return cls._meta.db_table + str(piece) @classmethod def sharding_get(cls, id=None, **kwargs): assert isinstance(id, int), 'id must be integer!' table = cls.get_sharding_table(id) sql = "SELECT * FROM %s" % table kwargs['id'] = id condition = ' AND '.join([k + '=%s' for k in kwargs]) params = [str(v) for v in kwargs.values()] where = " WHERE " + condition try: return cls.objects.raw(sql + where, params=params)[0] # the5fire:这里应该模仿Queryset中get的处理方式 except IndexError: # the5fire:其实应该抛Django的那个DoesNotExist异常 return None class Meta: db_table = 'user_'大概这么个意思吧,代码可以再严谨些。
总结
单纯看方案一的话,可能会觉得这么大量数据的项目,就别用Django了。其实the5fire第一次尝试找一个优雅的方式hack db_table时,也是一头灰。但是,所有的项目都是由小到大的,随着数据/业务的变大,技术人员应该也会更加了解Django,等到一定阶段之后,可能发现,用其他更灵活的框架,跟直接定制Django成本差不多。

----EOF-----
扫码关注,或者搜索微信公众号:码农悟凡
点击{阅读原文}进入教程
本次事件的重灾区,同情一下毕业论文被加密的同学),所以来自公网的攻击基本可以不用担心,但仍建议使用云厂商提供的防火墙,封锁139,445等端口。
已经中招了,我该怎么办?
- 对于已经中招的同学,表示深深的同情。据称有受害者支付了赎金,但仍然没有获得解密程序,建议不要支付比特币赎金,支付赎金只会让勒索软件产业更加壮大,出现越来越多的勒索事件。
- 保存好被加密的文件,关注各家安全公司或者勒索软件作者是否有解密程序放出
- 重新安装系统,并根据上面的安全建议打好补丁,做好预防措施,保持打补丁的良好安全习惯。
吃一堑长一智,后续应该做些什么?
对个人来说
- 养成良好的安全习惯,及时打补丁,安装安全防护软件,从正规渠道下载软件等,这些小习惯往往在关键时刻,能避免你的损失。
- 最最最有效的手段,找一个做安全行业的男(女)朋友 :)什么?你已经有了还中招了,那需要换一个了,我这里有资源,请私聊。
对企业来说
- 拨出一些预算,成立自己的安全团队,或使用第三方专业的安全服务/产品。
- 国内各公有云的用户,可以使用各云厂商提供的镜像和数据备份服务,即使受到攻击,也可以及时恢复数据。比如 UCloud-中国最大的中立云计算服务商 的数据方舟产品,可以恢复到12小时内任一秒的数据状态。
- 对公司内的安全岗位同学好一点,请他们吃饭,给他们加工资。
本文由『UCloud安全团队』提供。
「UCloud机构号」将独家分享云计算领域的技术洞见、行业资讯以及一切你想知道的相关讯息。
欢迎提问&求关注 o(*////▽////*)q~
以上。
