

- 原文地址:How I wrote the world's fastest JavaScript memoization library
- 原文作者:Caio Gondim
- 译文出自:掘金翻译计划
- 译者:薛定谔的猫
- 校对者:GangsterHyj,sunui
我是如何实现世界上最快的 JavaScript 记忆化的
在本文中,我将详细介绍如何实现 fast-memoize.js,它是世界上最快的 JavaScript 记忆化(memoization)实现,每秒能进行 50,000,000 次操作。
我们会详细讨论实现的步骤和决策,并且给出代码实现和性能测试作为证明。
fast-memoize.js 是开源项目,欢迎大家给我留言和建议。
不久前,我尝试了 V8 中一些即将发布的特性,以斐波那契算法为基础做了一些基准测试实验。
实验之一就是比较斐波那契算法的记忆化版本和普通实现,结果表明记忆化版本有着巨大的性能优势。
意识到这一点,我又翻阅了不同的记忆化库的实现,并比较了它们的性能(因为……呃,为什么不呢?)。记忆化算法本身非常简单,然而我震惊地发现不同实现之间性能差异巨大。
这是什么原因呢?
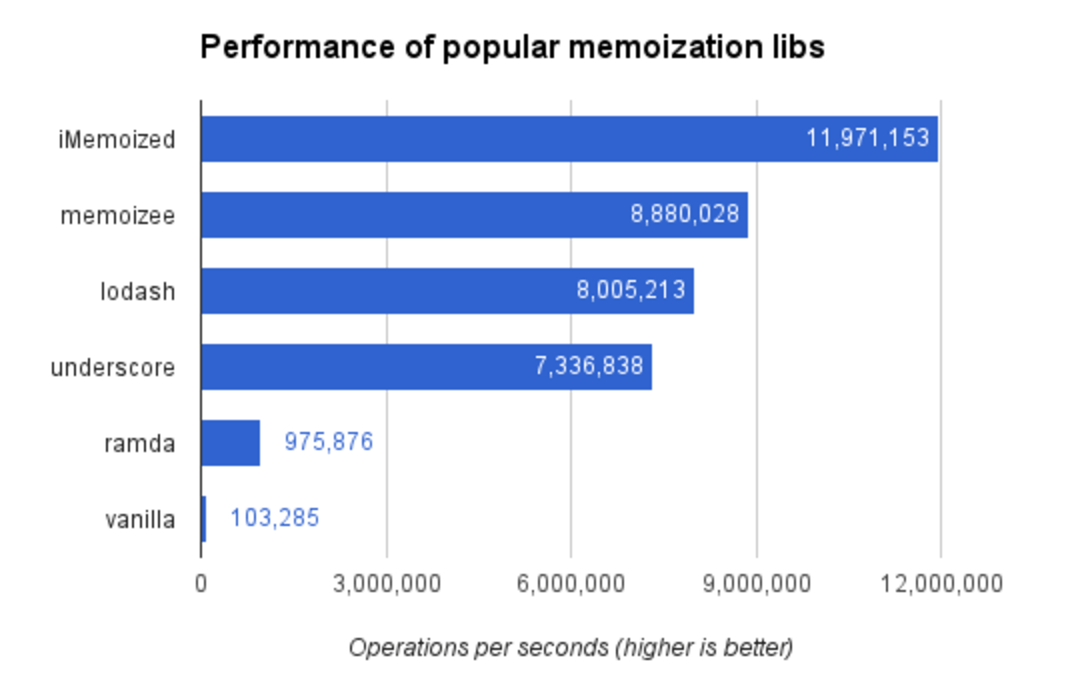
在翻阅 lodash 和 underscore 的源码时,我发现默认情况下,它们只能记忆化接受一个参数的函数。于是我就很好奇,能否实现一个足够快并且可以接受多个参数的版本呢?(或许可以开发出 npm 包给全世界的开发者使用呢?)
下文中,我将详细介绍实现它的步骤,以及实现过程中所做的决策。
理解问题
『记忆化是保存函数执行结果,而不是每次重新计算的一种技术。』
换句话说,记忆化就是对于函数的缓存。 它只适用于确定性算法,对于相同的输入总是生成相同的输出。
为了便于理解和测试,我们把这个问题拆分成几个小问题。
分解 JavaScript 记忆化问题
我将这个算法分解为 3 个小问题:
- 缓存:保存上一次计算结果。
- 序列化:输入为参数,输出一个字符串用于表示相应的输入。可以将它视作参数的唯一标识。
- 策略:将缓存和序列化组合起来,输出记忆化函数。
现在我们就要分别以不同的方式实现这 3 个部分,测试它们的性能,选择其中最快的方式,最后将它们结合起来就是我们最终的算法了。
这样做的目标就是让计算机为我们解除重担!
#1 - 缓存
如前文所述,缓存保存了之前的计算结果。
接口
为了抽象实现细节,我们需要创建一个类似于 Map 的接口:
- has(key)
- get(key)
- set(key, value)
- delete(key)
通过(定义接口)这种方式,只要我们实现了这个接口,就可以修改缓存内部的实现,而不影响外部使用。
实现
每次执行记忆化函数,我们需要做的就是:检查对应输入的输出是否已经被计算过。
因此最合理的数据结构是哈希表。它能够在 O(1) 时间复杂度检查某个值是否存在。 从底层看,一个 JavaScript 对象就是一个哈希表(或类似的结构),所以我们可以将输入作为哈希表的 key,将输出作为它的 value。
// Keys 代表斐波那契函数的输入
// Values 代表函数执行结果
const cache = {
5: 5,
6: 8,
7: 13
}为实现缓存,我分别尝试了:
以下是这些实现的性能测试。本地运行,请执行命令 npm run benchmark:cache。不同版本实现的源码可以在项目的 GitHub 页面找到。
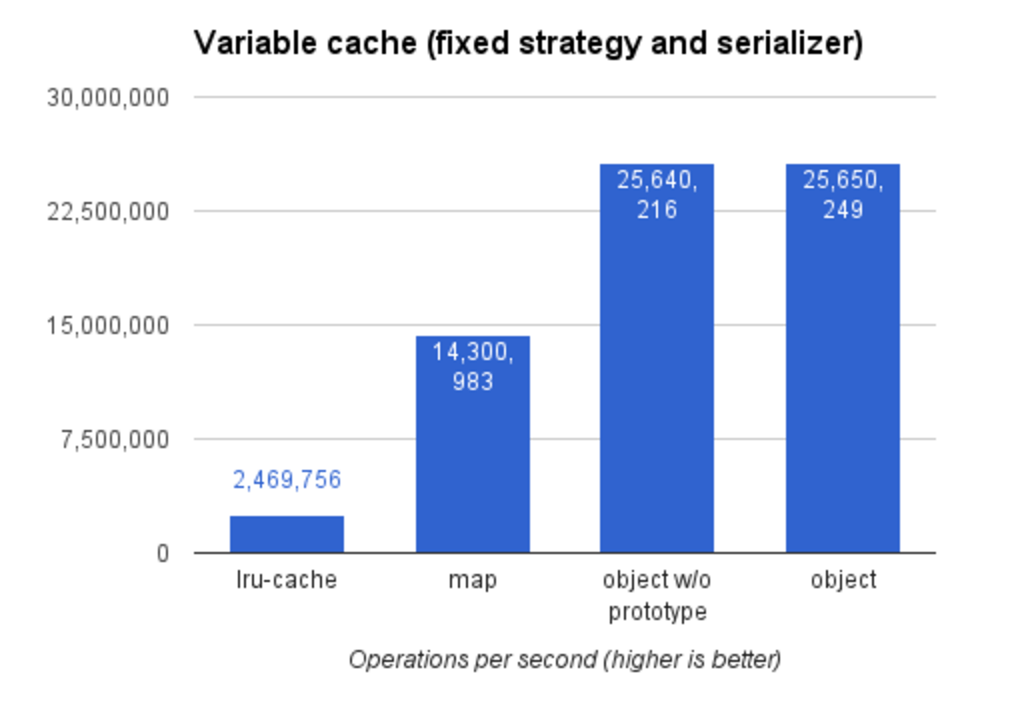
还需要一个序列化器
在参数是非字面量时,这个版本会有问题,因为转化为字符串时并不唯一。
functionfoo(arg) { returnString(arg) }
foo({a: 1}) // => '[object Object]'
foo({b: 'lorem'}) // => '[object Object]'这就是为什么我们还需要一个序列化器,用它来生成参数的指纹(唯一标识,译者注)。它的速度越快越好。
#2 - 序列化器
序列化器基于给定的输入输出一个字符串。它必须是一个确定性算法,意味着对相同的输入,总是给出相同的输出。
序列化器生成的字符串用作缓存的key,代表记忆化函数的输入。
JSON.stringify 是实现它性能最佳的方式,比其它方式的都好 -- 这也很容易理解,因为 JSON.stringify 是原生的。
我尝试使用 bound JSON.stringify(bar = foo.bind(null),此时 bar.name 为 bound foo,译者注),希望通过减少一次变量查找来提高性能,但很遗憾没有效果。
想在本地执行,可以执行命令 npm run benchmark:serializer,实现的具体代码可以在项目的 GitHub 页面找到。
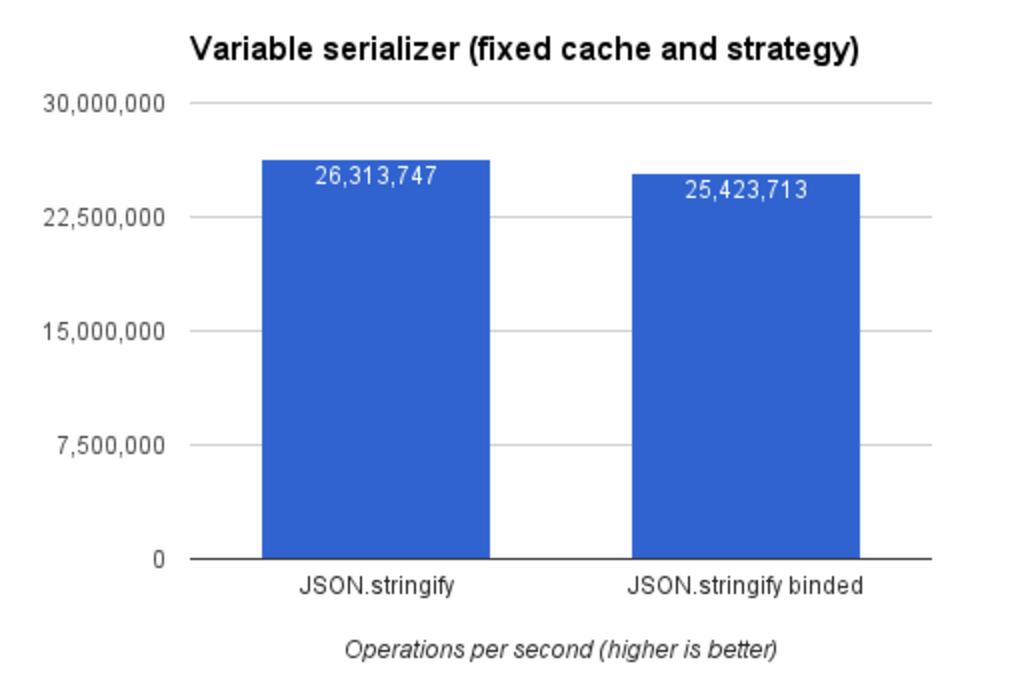
还剩最后一个部分:策略。
#3 - 策略
策略使用了序列化器和缓存,将两者结合起来。对 fast-memoize.js 来说,策略是我花时间最多的部分。即使非常简单的算法,每一个版本迭代都有一些性能提升。
以下是我先后尝试的方式:
- 普通方式 (初始版本)
- 针对单个参数优化
- 参数推断
- 偏函数
我们来逐个介绍它们。我会以尽量简化的代码,来介绍每种方式背后的想法。如果某些细节我没有解释清楚,你想要深入探究一下,可以在项目的 GitHub 页面中找到每个版本的代码。
本地运行,请执行命令 npm run benchmark:strategy。
普通方式
这是我第一次尝试,也是最简单的版本。步骤是:
- 序列化参数
- 检查给定输入的输出是否已经计算过
- 如果
true,从缓存中读取结果 - 如果
false,计算,并且将结果保存到缓存中
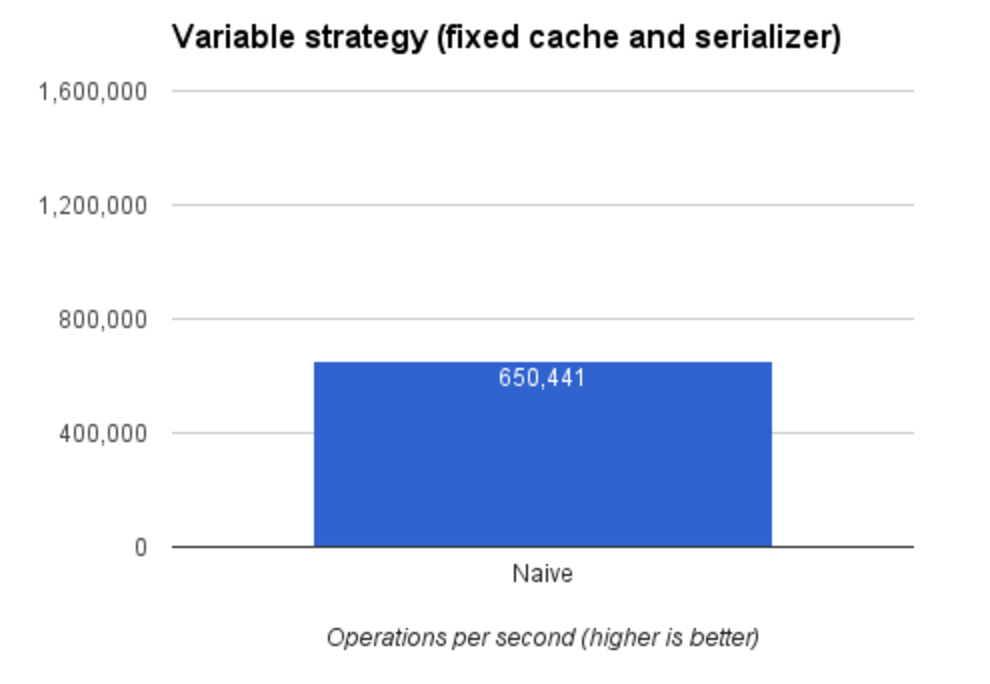
使用第一个版本,我们可以达到每秒 650,000 次操作。这个版本是后面优化版本的基础。
针对单个参数优化
改善性能的一个有效方法是优化热路径(hot path,指执行频率最高的路径,译者注)。对我们的代码来说,热路径就是接受一个基本类型参数的函数,这种情况下我们不需要对参数序列化。
- 检查
arguments.length === 1&& 参数为基本类型 - 如果
是,无需序列化参数,因为基本类型本身就可以作为缓存的key - 检查给定输入的输出是否已经计算过
- 如果
true,从缓存中读取结果 - 如果
false,计算,并且将结果保存到缓存中
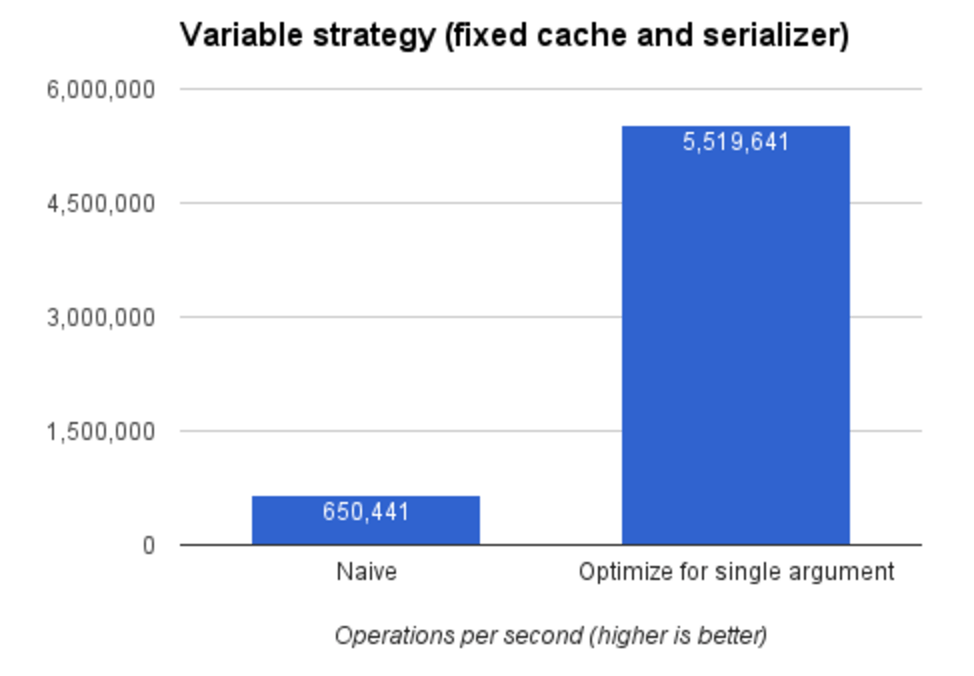
通过避免执行不必要的序列化操作,我们可以得到更快的执行结果(对热路径而言)。现在可以达到每秒 5,500,000 次了。
参数推断
function.length 返回一个已定义函数的形参个数,我们可以利用这个性质避免动态检查函数的实参个数(即避免 arguments.length === 1 的条件判断,译者注),并为单参数函数和非单参数函数分别提供不同的策略。
functionfoo(a, b) {
return a + b
}
foo.length // => 2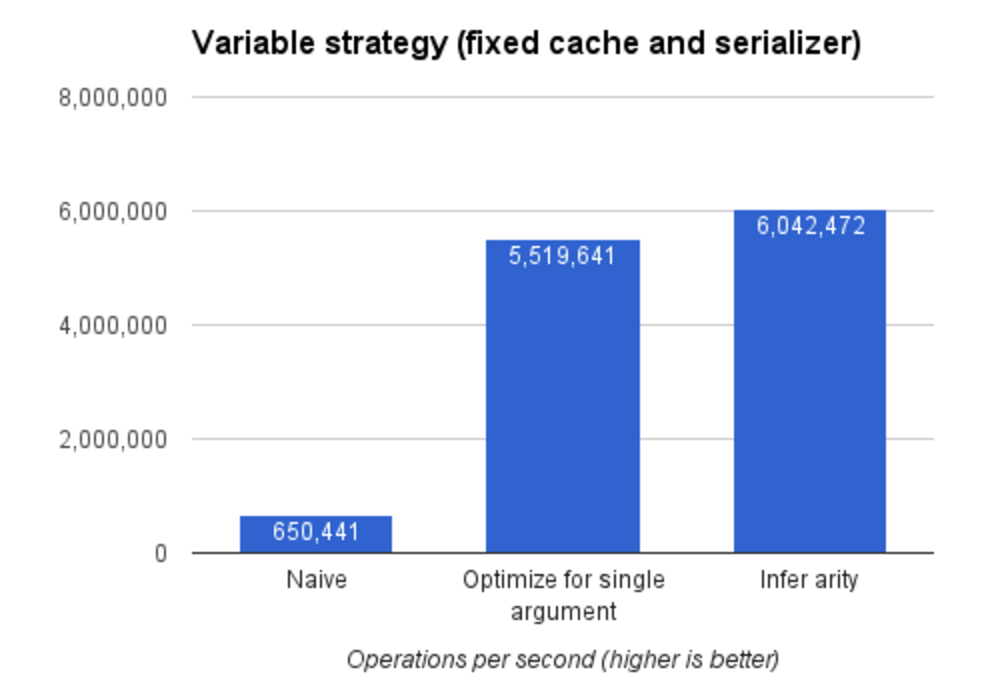
省去了这一次条件判断,我们(的实现)性能又有了一点提升,可以达到每秒 6,000,000 次操作。
偏函数(Partial application)
我觉得大多数时间都花费在了变量查找上(但没有量化数据支持),起初我也没有好的想法去改善。灵机一动,我突然想到可以使用 bind 方法,通过偏函数应用的方法将变量注入到函数中。
functionsum(a, b) {
return a + b
}
const sumBy2 = sum.bind(null, 2)
sumBy2(3) // => 5这种方式可以将函数的某些参数固定下来。我用就它把原函数,缓存,和序列化器固定下来。就用它来试试吧!
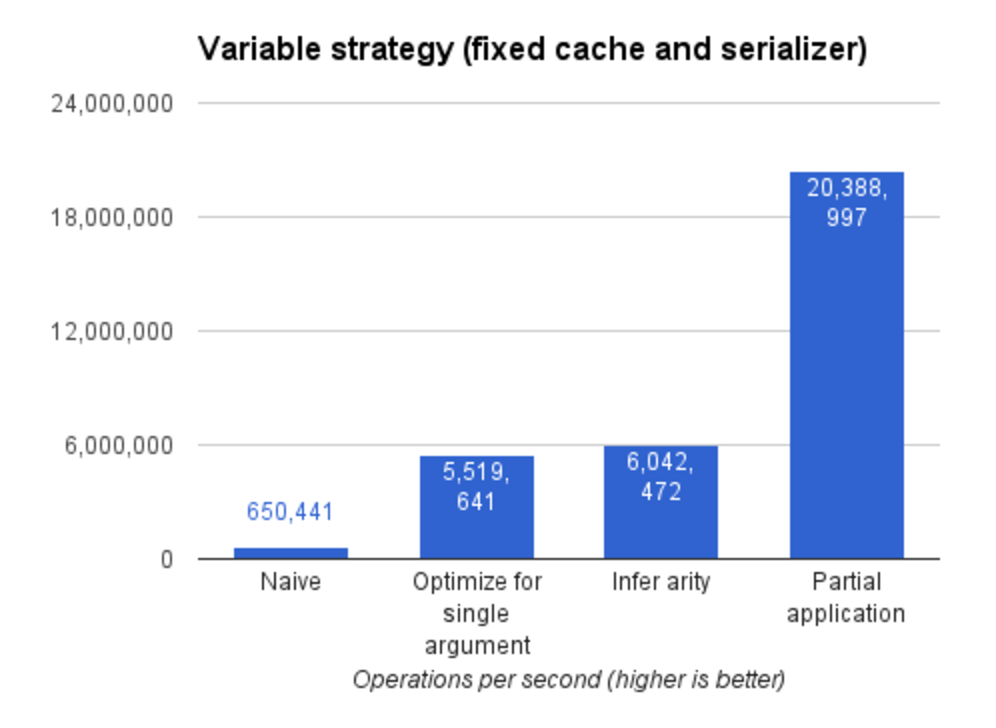
哇!效果非常好。我不知道如何进一步改进,但我对这个版本的测试结果已经很满意了。这个版本可以达到每秒 20,000,000 次操作。
最快的 JavaScript 记忆化组合
上面我们把记忆化分解为了 3 个部分。
对每个部分,我们将其中 2 个部分固定,更换其余一个测试其性能。通过这种单变量测试,我们能更加确信每次改变的效果--由于 GC 造成的不确定性停顿,JS代码的性能并不完全确定。
V8 会更根据函数的调用频率、代码结构等因素,做很多运行时优化。
为了确保我们将这 3 部分组合起来时不会错过大量性能优化的机会,我们尝试所有可能的组合。
一共 4 种策略 x 2 种序列化器 x 4 种缓存 = 32 种不同的组合。本地运行,请执行命令 npm run benchmark:combination。下面是性能最好的 5 种组合:
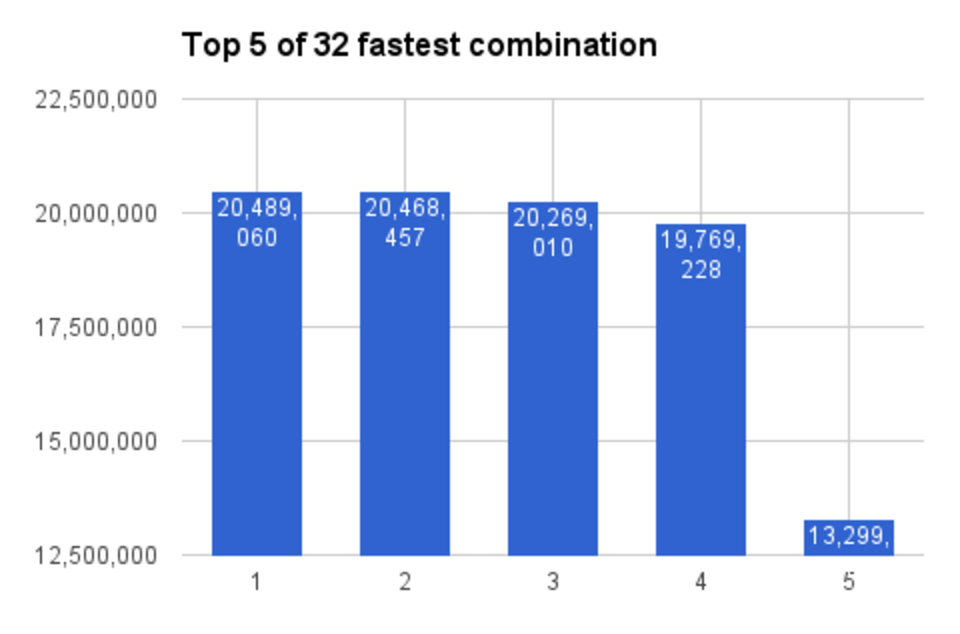
图例:
- 策略: 偏函数, 缓存: 普通对象, 序列化器: json-stringify
- 策略: 偏函数, 缓存: 无原型对象, 序列化器: json-stringify
- 策略: 偏函数, 缓存: 无原型对象, 序列化器: json-stringify-binded
- 策略: 偏函数, 缓存: 普通对象, 序列化器: json-stringify-binded
- 策略: 偏函数, 缓存: Map, 序列化器: json-stringify
事实证明我们上面的分析是对的。最快的组合是:
- 策略: 偏函数
- 缓存: 普通对象
- 序列化器: JSON.stringify
与流行库的性能对比
有了上面的算法,是时候把它同最流行的库做一个性能上的比较了。本地运行,请执行命令 npm run benchmark。结果如下:
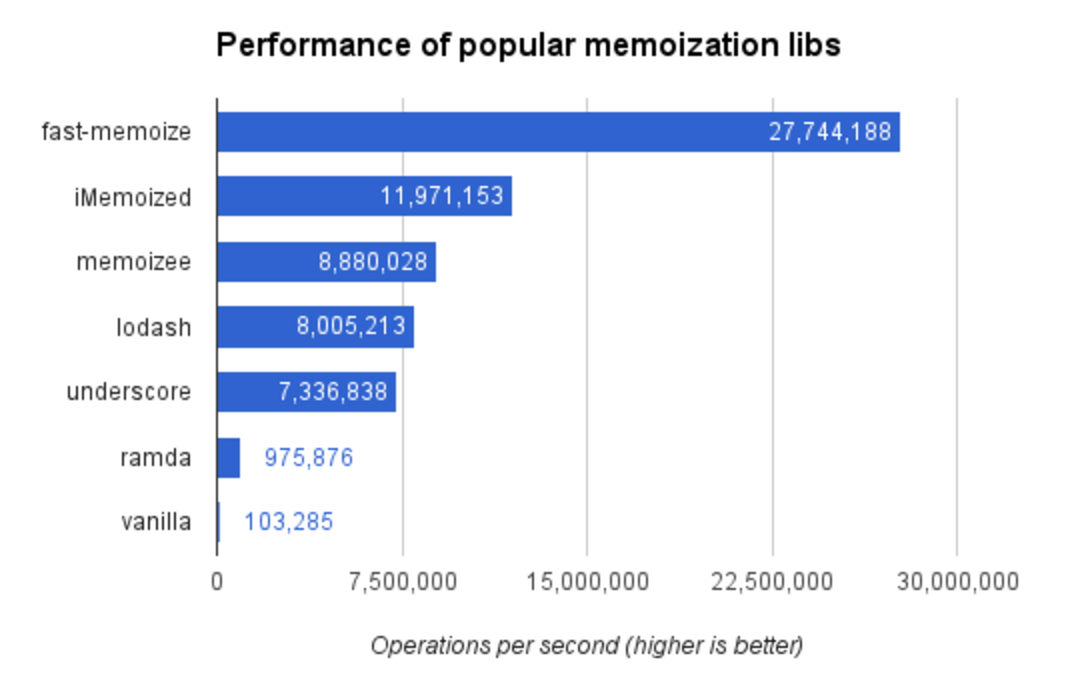
fast-memoize.js是最快的,几乎是第二名的 3 倍,每秒 27,000,000次操作。
面向未来
V8有一个很新的、未发布的优化编译器 TurboFan。
我们现在就应该用它测试一下,因为 TurboFan(极有可能)很快就会添加到 V8 中。通过给 Node.js 设置 flag --turbo-fan 就可以启用它。本地运行,请执行命令npm run benchmark:turbo-fan。以下是启用后的测试结果:
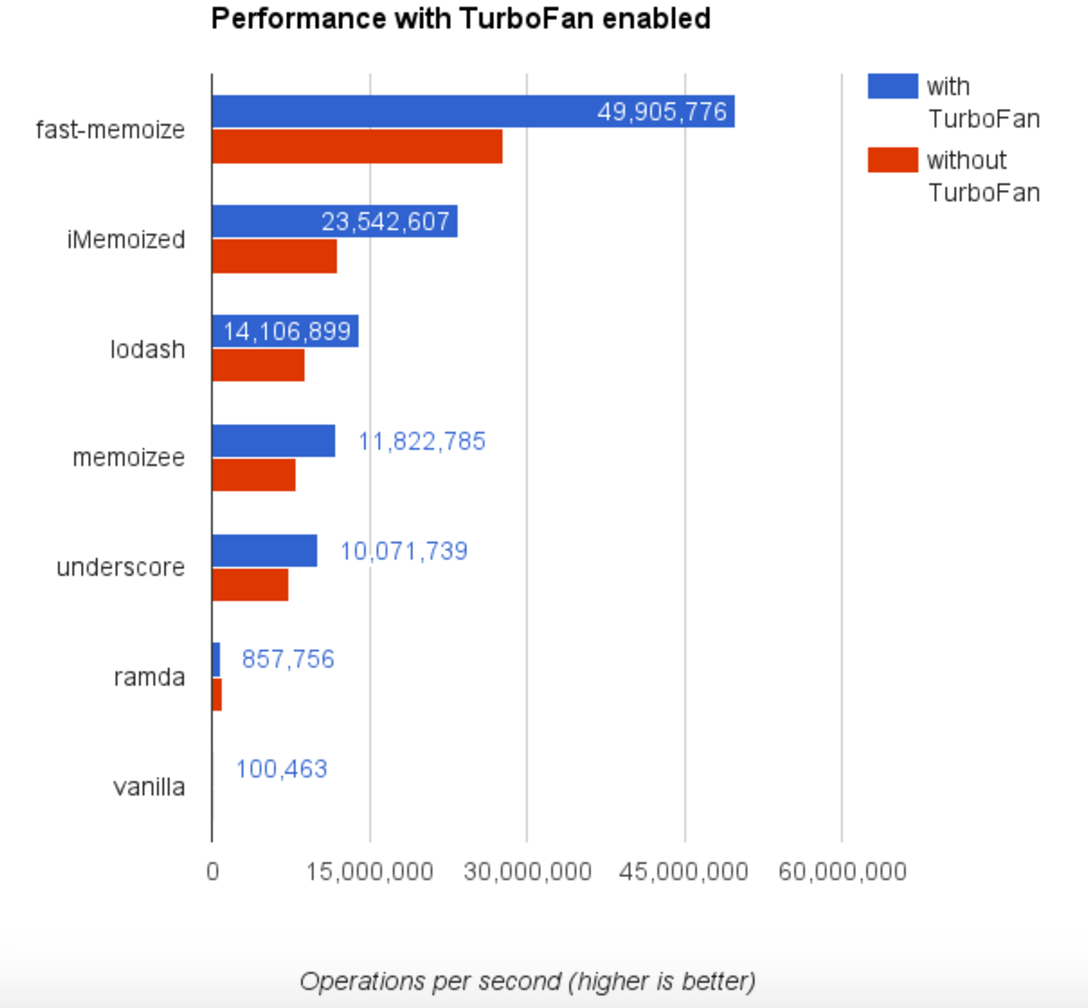
性能几乎翻倍,现在达到接近每秒 50,000,000 次。
看起来最新的 TurboFan 编译器可以极大的优化我们最终版本的 fast-memoize.js。
结论
以上就是我创建这个世界上最快的记忆化库的过程。分别实现各个部分,组合它们,然后统计每种组合方案的性能数据,从中选择最优的方案。(使用 benchmark.js )。
希望这个过程对其他开发者有所帮助。
fast-memoize.js 是目前最好的 #JavaScrip 库, 并且我会努力让它一直是最好的。
并非是因为我聪明绝顶, 而是我会一直维护它。 欢迎给我提交 Pull requests。
正如前 V8 工程师 Vyacheslav Egorov 所言,在虚拟机上测试算法性能非常棘手。如果你发现测试中的错误,请在 GitHub 上提交 issue。
这个库也一样,如果你发现任何问题请提交 issue(如果带上错误用例我会很感激)。带有改进建议的 Pull Requests 我将感激不尽。
如果你喜欢这个库,欢迎 star。这是对我们开源开发者的鼓励哦。
参考文献
- JavaScript & Hashtable
- Firing up ignition interpreter
- Big-O cheat sheet
- GOTO 2015 • Benchmarking JavaScript • Vyacheslav Egorov
有任何问题,欢迎评论!
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、React、前端、后端、产品、设计 等领域,想要查看更多优质译文请持续关注 掘金翻译计划。
