

上文,介绍了协同过滤中的矩阵分解算法、spark大数据处理框架以及spark分布式矩阵的实现以及相关的运算,请戳蓝色加粗 链接:《如何在spark分布式的基础上实现协同过滤推荐?》。 本文将重介绍最受欢迎的协同过滤算法,以及会在文中实战在spark分布式矩阵的基础上模拟协同过滤推荐。
【推荐系统简介】
个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商业智能平台,以帮助为顾客提供完全个性化的决策支持和信息服务。个性化推荐已经发展出了很多成熟的算法,下面列出一些常用的算法。
▲协同过滤推荐算法
协同过滤推荐是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻用户对商品评价的加权价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户推荐。协同过滤推荐技术分为3种类型,包括基于用户的推荐、基于项目的推荐和基于模型的推荐。
▲基于关联规则的推荐
基于关联规则的推荐是以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。关联规则就是在一个交易数据库中挖掘购买了商品集X的交易中有多大比例的交易同时购买了商品集合Y。
▲基于效用的推荐
基于效用的推荐是建立在对用户使用项目的效用情况上计算的,其核心问题是怎样为每一个用户去创建一个效用函数。因此,用户资料规模很大程度上是由系统所采用的效用函数决定的。
▲基于知识的推荐
基于知识的推荐在某种程度是可以看成是一种推理技术。效用知识是一种关于一个项目如何满足某一特定用户的知识,因此能解释需要和推荐的关系,所以用户资料可以是任何能支持推理的知识结构,它可以是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。
由于各种推荐方法都有优缺点,所以在实际中组合推荐经常被采用。内容推荐和协同过滤推荐的组合是当前工业界和学术界的一个热点。
【协同过滤推荐系统】
协同过滤推荐算法是推荐系统中应用最广泛的推荐算法之一。协同过滤的本质,就是通过预测用户-物品矩阵中缺失的评分,来预测用户对物品的偏好。更加具体地,协同过滤算法主要分为Memery-based CF和Model-based CF,而Memory-based CF包括User-based CF和Item-based CF。
一.基于用户的协同过滤算法User-based CF
基于用户的协同过滤算法是根据相似用户的偏好信息产生对目标用户的推荐。它基于这样一个假设:如果一些用户对某一类项目的打分比较接近,则他们对其他的项目的打分也比较接近。协同过滤推荐系统采用统计计算方式搜索目标用户的相似用户,并根据相似用户对项目的打分来预测目标用户的对指定项目的评分,最后选择相似度较高的前若干个相似用户的评分作为推荐结果,并反馈给用户。
这种算法不仅计算简单且精确度较高,被现有的协同过滤推荐系统广泛采用。User-based协同过滤推荐算法的核心就是通过相似性度量方法计算出最近邻居集合,并将最近邻的评分结果作为推荐预测结果返回给用户。
例如,在下表所示的用户-项目评分矩阵中,行代表用户,列代表电影,表中的数值代表用户对某个电影的评分。现在需要预测用户小李对电影《鬼吹灯》的评分。
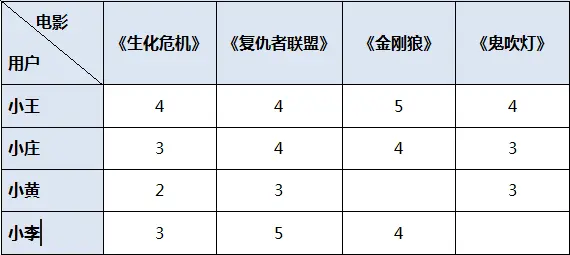
由上表可以看出小庄和小李对电影的评分比价接近,小庄对《生化危机》《复仇者联盟》《金刚狼》的评分分别为3、4、4,小李的评分分别为3、5、4,他们之间的相似度最高,因此小庄和小李是最接近的邻居,他们两个看电影的口味相似,因此小庄对《鬼吹灯》的评分结果对预测值的影响占据最大比例。
在真实的预测中,推荐系统只对前若干个邻居进行搜索,并根据这些邻居的评分为目标用户预测指定项目的评分。
二.基于项目的协同过滤算法Item-based CF
基于项目的协同过滤推荐是根据用户对相似项目的评分数据来预测目标项目的评分。它是建立在如下假设基础上的:如果大部分用户对某些项目的打分比较相近,则当前用户对这些项目的打分也会比较接近。Item-based协同过滤算法主要对目标用户所评价的一组项目进行研究,并计算这些项目与目标之间的相似性,然后从选择前k个相似度最大的项目输出,这是与User-based协同过滤的区别所在。
把之前的用户-项目评分矩阵作为例子,还是预测用户小李对电影《鬼吹灯》的评分。通过数据分析发现,电影《生化危机》的评分与《鬼吹灯》的评分非常相似,前三个用户对《生化危机》的评分分别为4、3、2,对《鬼吹灯》的评分分别为4、3、3,它们二者相似度最高,因此电影《生化危机》是电影《鬼吹灯》的最佳邻居,因此《生化危机》对《鬼吹灯》的评分预测值的影响占据最大比例。在真实的预测中,推荐系统只对前若干个邻居进行搜索,并根据这些邻居的评分为目标用户预测指定项目的评分。
Item-based协同过滤推荐算法的主要工作内容是最近邻居查询和产生推荐。因此Item-based协同过滤推荐算法可以分为最近邻查询和产生推荐两个阶段。最近邻查询阶段是要计算项目与项目之间的相似性,搜索目标项目的最近邻居;产生推荐阶段是根据用户对目标项目的最近邻居的评分信息预测目标项目的评分,最后产生前N个推荐信息。
三.基于模型的协同过滤推荐Model-based CF
现实中的用户-项目矩阵极大,而用户的兴趣和消费能力有限,对单个用户来说消费的物品,产生评分记录的物品是极少的。这样造成了用户-项目矩阵含有大量的空值,数据极为稀疏。假设用户的兴趣只受少数几个因素的影响,因此稀疏且高维的用户-项目评分矩阵可以分解为两个低维矩阵,分别表示用户的特征向量和项目的特征向量。
用户的特征向量代表了用户的兴趣,物品的特征向量代表了物品的特点,且每一个维度相互对应,两个向量的内积表示用户对该物品的喜好程度。矩阵分解是Model-based协同过滤推荐中最为关键的技术之一,就是通过用户特征矩阵U和物品特征矩阵V来重构低维矩阵预测用户对物品的评分。 常用的协同过滤矩阵分解算法包括奇异值分解、正则化矩阵分解、带偏置的矩阵分解。
【基于Spark分布式矩阵构建协同过滤推荐算法】
一.实现User-based协同过滤的示例Spark的data/mllib/als/test.data文件提供了用于协同过滤推荐测试的评分数据,文件的每一行都是一项评分,其格式为:[用户ID],[项目ID],[评分]。基于该测试数据,展示如何使用Spark实现Item-based协同过滤。
1.将评分数据读取到坐标矩阵CoordinateMatrix中。
//读取文件

//格式化数据

//创建坐标矩阵

2.将CoordinateMatrix转换为RowMatrix计算两两用户的相似度。
由于RowMatrix只能就是那列的相似度,而用户数量是有行表示,因此CoordinateMatrix需要先计算转置:
//计算转置矩阵并转为行矩阵

//求相似度

3.假设需要预测用户1对项目1的评分,那么预测结果就是用户1的平均评分加上其他用户对项目1评分的按相似度的加权平均。
//计算用户1的平均评分


//计算其他用户对项目1的加权平均分

//求和输出预测结果

二.实现Item-based协同过滤的示例
类似于User-based的协同过滤算法,下面给出Spark在测试数据集上实现Item-based协同过滤的示例:
//读取评分数据

//格式化数据

//创建坐标矩阵

//计算Item相似度

//计算项目1的平均评分

//计算用户1对其他项目的加权平均分

//求和输出预测结果

三.实现Model-based协同过滤的示例
奇异值分解是Model-based协同过滤最简单的一种方法。利用Spark中的矩阵分解奇异值分解操作,可以很容易的实现基于奇异值分解的协同过滤算法,示例如下:
1.首先将评分数据读取到CoordinateMatrix中:
//读取文件数据

//格式化数据

//创建坐标矩阵

2.将CoordinateMatrix转换为RowMatrix,并调用computeSVD计算评分矩阵的秩为2的奇异值分解:

3.假设需要预测用户1对项目1的评分:

4.输出预测结果:

全文首先简单介绍了矩阵和spark分布式矩阵的实现和相关算法,利用案例实战了Spark分布式矩阵的基础上模拟实现协同过滤推荐。其实Spark的MLlib库中已经提供了一个基于ALS交替最小二乘法实现的协同过滤矩阵分解推荐算法,它通过观察到的所有用户给产品打分,来推断每个用户的喜好并向用户推荐合适的产品。其模型可以理解为用户评分矩阵是由用户特征矩阵乘以物品特征矩阵得到,MLlib提供的ALS模型采用一种高效的矩阵分解计算,在海量数据中计算性能非常好,如果使用协同推荐算法,建议直接使用MLlib提供的ALS协同推荐算法。
