

作者简介:

MATTHIJS HOLLEMANS
荷兰人,独立开发者,专注于底层编码,GPU优化和算法研究。目前研究方向为IOS上的深度学习及其在APP上的应用。
邮件地址:mailto:matt@machinethink.net
github地址:github.com/hollance
个人博客:machinethink.net/
在使用深度学习网络(deep learning network)进行预测任务之前,首先要训练它。目前有很多训练神经网络的工具,TensorFlow是大部分人的首选。
你可以使用TensorFlow训练你的机器学习模型,然后使用这些模型来进行预测。训练过程通常是在一台强大的机器或者云上进行,但是TensorFlow也可以运行在IOS上,虽然存在一些限制。
本文中,作者详细介绍了如何使用TensorFlow训练一个简单的分类器并应用在IOS app上。本文将会使用Gender Recognition by Voice and Speech Analysis dataset数据集,项目源码已托管至GitHub。

TensorFlow简介
TensorFlow是一个构建计算图(computational graphs)用来做机器学习的软件库。其他很多工具都以一种高抽象层次(higher level of abstraction)的方式工作着,比如通过Caffe,你能够设计一个不同层(layers)之间相互链接的神经网络(neural network)。 这和IOS上基础神经网络子程序(Basic Neural Network Subroutines, BNNS)和 Metal 渲染(Metal Performance Shaders Convolution Neural Network,BPSCNN)提供的功能很相似。
你可以认为TensorFlow是一个实现新机器学习算法的工具包(toolkit),而其他的深度学习工具则是使用已实现的算法。这意味着你不必从头开始构建一切,TensorFlow拥有很多可复用的构件集(reusable building blocks),以及能够在TensorFlow上层提供便利模块的其他库,如Keras。
使用逻辑斯蒂回归的二值分类
在本文中,我们将会创建了一个使用逻辑斯蒂回归算法(logistic regression)的分类器。该分类器接收输入数据然后返回这条数据所属的类别。项目中只有两个类别:男性(male)和女性(female),因此这是一个二值分类器(binary classifier)。
Note: 二值分类器虽然是最简单的分类器,但是其思想和那些能够区分成百上千类的分类器一样。虽然这篇文章中并没有进行深度学习,但某些理论基础是共同的。
每条输入数据由代表用户声音的声学特征的20个数字组成,后面会详细说明,现在你将其看作是声频和其他信息就可以了。如图所示,20个数字和一个sum块连接,这些连接有不同的权重(weights),对应着这20个代表特征的数字的重要程度。
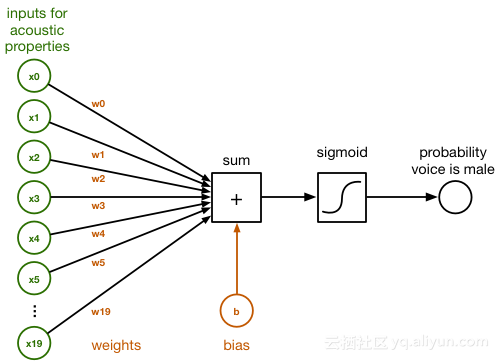
图中,x0 – x19表示输入特征,w0 - w19表示连接的权重,在sum 块中,按如下方式进行运算(就是普通的点乘):
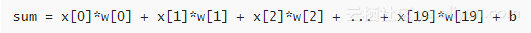
训练分类器就是要找到w和b的正确的数值。初始化时,将w和b全部置0。训练多轮之后,分类器就会使用合适的w和b将男性声音和女性声音区分开。为了将sum转化成0到1之间的概率,我们采用logistic sigmod函数:
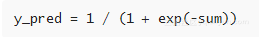
如果sum是一个大的正数,sigmod函数将返回1或者概率100%。如果sum是一个大的负数,sigmod函数会返回0。所以对于大的正数和负数,我们就能得到确定的“是”和“否”的预测结果。然而,如果sum接近0,sigmod函数就会返回一个接近50%的概率。当我们开始训练分类器的时候,初始预测会是50/50,这是因为分类器还没有学到任何东西,对所有的输出并不确定。但是随着训练次数的增加,概率就会越接近1和0,分类结果就会变得更加明确。
y_pred即语音来自男性的概率。如果这个概率大于0.5,我们就认为这是男性的声音,否则,就认为是女性的声音。
使用逻辑斯蒂回归的二值分类器的原理:分类器的输入数据由描述音频记录声学特征的20个数字组成,加权求和再使用sigmod函数,最后输出是男性语音的概率。
在TensorFlow上实现分类器
在TensorFlow上使用该分类器,首先需要创建一个计算图(computational graph)。计算图由表示进行运算的节点(nodes)以及节点之间流动的数据(data)组成。逻辑斯蒂回归的图如下所示:
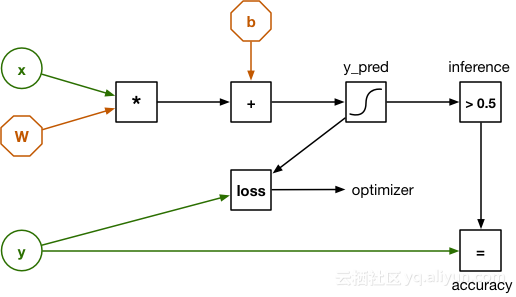
这个图和前面的图看起来有一些区别,输入数据x不再是20个独立的数字,而是一个有20个元素的向量,权重用矩阵w表示,点积用简单的矩阵乘法代替。
这里的输入y用来检验分类器的效果。实验所用的数据集有3168条语音记录,并且我们知道每条记录是男性还是女性的。这些已知的输出(男性/女性)被称为标签(labels),这些标签保存在输入y中。
由于权重初始化时全部置为0,分类器可能会做出错误的预测。所以,我们使用损失函数(loss function)来衡量分类器的分类水平。损失函数会比较预测结果y_pred和正确标签y。计算完训练样本的损失值(loss),我们使用反向传播(back propagation)修正权重w和b的值。训练过程要在所有样本上重复进行,直到计算图得出最佳权重数据。衡量分类器效果的损失值会随时间变得越来越小。
张量简介
上图中数据从左边流向右边,从输入流向输出。这就是TensorFlow中“flow”的来源。图中的数据都是以张量(tensor)的形式流动的。张量其实就是n维数组(n-dimensional array)。前面提到w是权重矩阵,TensorFlow认为它是一个二阶张量(second-order tensor),其实也就是二维数组(two-dimensional array)。如:
1.标量数字就是0阶张量;
2.向量是一阶张量;
3.矩阵是二阶张量;
4.三维数组是三阶张量
深度学习中,比如卷积神经网络(convolutional neural networks, CNN)经常需要处理四维张量,但本文中的逻辑斯蒂分类器比较简单,不会超过二阶张量,即矩阵。之前提到x是一个向量,现在把x和y都当作一个矩阵。如此一来,损失值就可以一次性计算出来。单个样本有20个数据,如果载入全部3168个样本,那么x将变成一个3168 X 20的矩阵。在x和w相乘之后,输出y_pred是一个3168 X 1的矩阵。即为数据集中的每一个样本都进行了预测。总之,用矩阵/张量表示计算图,就可以一次性为多个样本进行预测。
安装TensorFlow
环境:Python3.6
在Mac上使用Homebrew包管理器安装Python 3.6很简单,如果还没有安装Homebrew,可以在线安装。然后打开终端(Terminal)输入如下命令安装最新版Python:brew install python3然后使用Python的包管理器pip来安装所需要的包,在终端输入如下命令:
pip3 install numpy
pip3 install scipy
pip3 install scikit-learn
pip3 install pandas
pip3 install tensorflow除了TensorFlow,我们还安装了Numpy, Scipy, pandas和scikit-learn库,这些包会安装在/usr/local/lib/python3.6/site-packages目录下,你可以随时查看。pip可以自动安装最适合你系统的TensorFlow版本。如果你想安装其它版本,请参照离线安装指南。
下面测试一下所有的东西是否都已被正确安装。创建tryit.py,如下:
import tensorflow as tf
a = tf.constant([1, 2, 3])
b = tf.constant([4, 5, 6])
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(a + b))然后从终端运行这个脚本,就会输出关于设备的一些调试信息,最可能是关于CPU的,如果你的Mac装有NVIDIA GPU,就会输出GPU相关的情况。最后会输出:
[5 7 9]
这是两个向量a和b的和。亦有可能出现如下信息:
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.如果出现上述调试信息,这意味着你的系统上安装的TensorFlow版本并不适合你的CPU。一种解决办法是从源(from source)安装TensorFlow,你可以自行配置所有的选项。
数据的详细分析
在本文的实验中,我们并没有使用TensorFlow教程中常用的MNIST手写数字是被数据集,而是使用了根据语音识别性别的数据集,voice.csv文件如下所示。这些数字代表语音记录不同的声学特征(acoustic properties)。通过脚本从录音中抽取出这些特征,然后转换为这个CSV文件。如果感兴趣的话可以参照R语言源码。
这个数据集包含3168条样本数据,表格中每一行是一条样本,基本上男女各占一半。每条样本数据包含20个声学特征,如图所示:
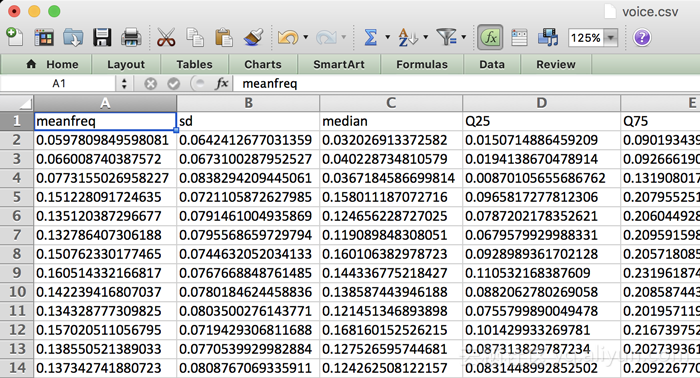
虽然不清楚这些特征代表的含义,但这并不重要,我们关心的仅是从这些数据中训练出一个能够区分男性和女性声音的分类器。如果要在你的APP中检测音频是男性还是女性产生的,你首先需要从这些音频数据中抽取这些声学特征。只要找到了这20个声学特征,就可以使用我们的分类器进行预测。所以,这个分类器并不是直接作用在音频上的,而仅仅是作用在这些抽取出来的特征。
Note: 这里需要指出深度学习和传统算法如逻辑斯蒂回归的区别。我们训练的分类器不能学习非常复杂的东西,需要在数据预处理阶段抽取特征。而深度学习系统可以直接将原始音频数据作为输入,抽取重要的声学特征,然后再进行分类。
创建训练集和测试集
我创建了一个名为split_data.py的Python脚本来分割训练集和数据集,如下:
# This script loads the original dataset and splits it into a training set and test set.
import numpy as np
import pandas as pd
# Read the CSV file.
df = pd.read_csv("voice.csv", header=0)
# Extract the labels into a numpy array. The original labels are text but we convert
# this to numbers: 1 = male, 0 = female.
labels = (df["label"] == "male").values * 1
# labels is a row vector but TensorFlow expects a column vector, so reshape it.
labels = labels.reshape(-1, 1)
# Remove the column with the labels.
del df["label"]
# OPTIONAL: Do additional preprocessing, such as scaling the features.
# for column in df.columns:
# mean = df[column].mean()
# std = df[column].std()
# df[column] = (df[column] - mean) / std
# Convert the training data to a numpy array.
data = df.values
print("Full dataset size:", data.shape)
# Split into a random training set and a test set.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.3, random_state=123456)
print("Training set size:", X_train.shape)
print("Test set size:", X_test.shape)
# Save the matrices using numpy's native format.
np.save("X_train.npy", X_train)
np.save("X_test.npy", X_test)
np.save("y_train.npy", y_train)
np.save("y_test.npy", y_test)
在本例的二分类器中,我们用1表示男性,0表示女性。在终端运行这个脚本文件,最终会生成4个文件:训练数据(X_train.npy)及其标签(y_train.npy),测试数据(X_test.npy)及其标签(y_test.npy)。
构建计算图
下面将使用train.py脚本,用TensorFlow训练逻辑斯蒂分类器,可在GitHub上查看完整代码。
先导入训练数据(X_train和y_train):
下面开始构建计算图。首先使用placeholders定义输入数据x和y:
tf.name_scope()将图的不同部分分成不同域,每个层都是在一个唯一的tf.name_scope()下创建,作为在该作用域内创建的元素的前缀,x的独特名字将会是‘inputs/x-input’,这里将输入数据x和y定义在inputs域下,分别命名为“x_input”和“y_put”,方便后面使用。
每条输入数据是有20个元素的一个向量,并且有一个对应的标签(1表示男性,0表示女性)。如果将所有的训练数据构成矩阵,那么就可以一次性完成计算。所以上面定义x和y为二维张量:x的维度是[None, 20],y的维度是[None, 1]。None表示第一个维度未知。实验中的训练集中有2217条样本,测试集有951条样本。
导入训练数据后,下面开始定义分类器参数(parameters):
with tf.name_scope("model"):
W = tf.Variable(tf.zeros([num_inputs, num_classes]), name="W")
b = tf.Variable(tf.zeros([num_classes]), name="b")张量w是权重矩阵(一个20×1的矩阵),b是偏置。W和b被声明为TensorFlow的变量(variables),会在反向传播的过程中被更新。
下面声明逻辑斯蒂回归分类器的核心公式:
y_pred = tf.sigmoid(tf.matmul(x, W) + b)这里将x和w相乘再加上b,然后输入sigmod函数中,得到预测值y_pred,表示x中音频数据是男性声音的概率。
Note:实际上,这行代码现在还没有计算任何东西,目前只是在构建计算图。这行代码将矩阵乘法和加法的节点,以及sigmod函数(tf.sigmoid)加入图中。当计算图构建完成时,创建一个TensorFlow会话(session),就可以测试真实数据了。
为了训练模型还需要定义一个损失函数(loss function),对于二值逻辑斯蒂回归分类器,TensorFlow已经内置了log_loss函数:
with tf.name_scope("loss-function"):
loss = tf.losses.log_loss(labels=y, predictions=y_pred)
loss += regularization * tf.nn.l2_loss(W)log_loss节点接收样本数据的真实标签y作为输入,与预测值y_pred比较,比较的结果代表损失值(loss)。第一次训练时,在所有的样本上预测值y_pred都会是0.5,因为分类器现在并不知道真实答案。初始损失值为-ln(0.5),即0.693146,。随着不断训练,损失值会变得越来越小。
上面第三行代码加入了L2正则化项防止过拟合。正则项系数regularization 定义在另一个placeholder中:
with tf.name_scope("hyperparameters"):
regularization = tf.placeholder(tf.float32, name="regularization")
learning_rate = tf.placeholder(tf.float32, name="learning-rate") 前面我们使用了placeholder来定义输入x和y,这里又定义了超参(hyperparameters)。这些参数不像权重w和偏置b能够通过模型学习得到,你只能根据经验来设置。另一超参learning-rate定义了步长。
optimizer 进行反向传播运算:以loss作为输入,决定如何更新权重和偏置。TensorFlow中各种优化类提供了为损失函数计算梯度的方法,这里我们选用AdamOptimizer:
with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss)这里添加了操作节点train_op,用于最小化loss,后面会运行这个节点来训练分类器。在训练过程中,我们使用快照技术与准确率确定分类器效果。定义一个计算预测结果准确率的图节点accuracy:
with tf.name_scope("score"):
correct_prediction = tf.equal(tf.to_float(y_pred > 0.5), y)
accuracy = tf.reduce_mean(tf.to_float(correct_prediction), name="accuracy")之前有说过y_pred是0到1之间的概率。通过tf.to_float(y_pred > 0.5),如果预测是女性,返回0;如果是男性,就返回1。通过tf.equal方法可以比较预测结果y_pred与实际结果y是否相等,返回布尔值。先把布尔值转换成浮点数,tf.reduce_mean()计算均值,最后的结果就是准确率。后面在测试集上也会使用这个accuracy节点确定分类器的真实效果。
对于没有标签的新数据,定义inference节点进行预测:
with tf.name_scope("inference"):
inference = tf.to_float(y_pred > 0.5, name="inference")
训练分类器
这个简单的逻辑斯蒂分类器可能很快就能训练好,但一个深度神经网络可能就需要数小时甚至几天才能达到足够好的准确率。下面是train.py的第一部分:
with tf.Session() as sess:
tf.train.write_graph(sess.graph_def, checkpoint_dir, "graph.pb", False)
sess.run(init)
step = 0
while True:
# here comes the training code我们创建了一个session对象来运行图。调用sess.run(init)将w和b置为0。同时,将图保存在/tmp/voice/graph.pb文件。后面测试分类器在测试集上的效果以及将分类器用在IOS app上都需要用到这个图。
在while True:循环内,操作如下:
perm = np.arange(len(X_train))
np.random.shuffle(perm)
X_train = X_train[perm]
y_train = y_train[perm]在每次进行训练时,将训练集中的数据随机打乱,避免让分类器根据样本的顺序来进行预测。下面session将会运行train_op节点,进行一次训练:
feed = {x: X_train, y: y_train, learning_rate: 1e-2,
regularization: 1e-5}
sess.run(train_op, feed_dict=feed)通过sess.run()函数传入feed_dict参数,给使用placeholder中的张量赋值,启动运算过程。
本文所采用的是个简单分类器,每次都采用完整训练集进行训练,所以将x_train数组放入x中,将y_train数组放入y中。如果数据非常多,每次迭代就应该使用一小批数据(100到1000个样本)进行训练。
train_op节点会运行很多次,反向传播机制每次都会对权重w和偏置b进行微调,随着迭代次数增多,w和b就会逐渐达到最优值。为了帮助理解训练过程,在每迭代1000次时,运行accuracy和loss节点,输出相关信息:
if step % print_every == 0:
train_accuracy, loss_value = sess.run([accuracy, loss],
feed_dict=feed)
print("step: %4d, loss: %.4f, training accuracy: %.4f" % \
(step, loss_value, train_accuracy))注意的是,在训练集上高准确率并不意味着在测试集上也能表现良好,但是这个值应该随着训练过程逐渐上升,loss值不断减小。
然后定义可以用来后续恢复模型以进一步训练或评估的检查点(checkpoint)文件。分类器目前学习到的w和b被保存到/tmp/voice/目录下 :

当你发现loss不再下降,当下一个*** SAVED MODEL ***消息出现,这个时候你就可以按 Ctrl+C停止训练。
我选用learning_rate = 1e-2, regularization = 1e-5,在训练集上能够达到97%准确率和0.157左右的损失值。如果feed中regularization = 0,loss值会更低。
分类器效果
分类器训练好之后,就可以在测试数据上检验分类器的实际效果。我们创建一个新的脚本test.py,载入计算图和测试集,然后计算预测准确率。
Note: 测试集上的准确率会比训练集中的准确率(97%)低,但是不应该太低。如果你的训练器出现过拟合,那就需要重新调整训练过程了。
还是先导入包,然后载入测试数据:
import numpy as np
import tensorflow as tf
from sklearn import metrics
X_test = np.load("X_test.npy")
y_test = np.load("y_test.npy")由于现在只是验证分类器的效果,所以并不需要整个图,只需要train_op 和 loss节点。之前已经将计算图保存到graph.pb文件,所以这里只需要载入就可以了:
with tf.Session() as sess:
graph_file = os.path.join(checkpoint_dir, "graph.pb")
with tf.gfile.FastGFile(graph_file, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name="")TensorFlow推荐使用*.Pb保存数据,所以这里只需要一些辅助代码就可以载入这个文件,并导入会话(session)中。再从检查点文件中载入w和b的值:
W = sess.graph.get_tensor_by_name("model/W:0")
b = sess.graph.get_tensor_by_name("model/b:0")
checkpoint_file = os.path.join(checkpoint_dir, "model")
saver = tf.train.Saver([W, b])
saver.restore(sess, checkpoint_file)我们将节点都放在域(scope)中并命名,就可以使用get_tensor_by_name()轻易找到。如果你没有给他们一个明确的命名,那么你只能在整个图中寻找TensorFlow默认名称,这将会很麻烦。还需要引用其他的节点,尤其是输入x和y以及进行预测的节点:
x = sess.graph.get_tensor_by_name("inputs/x-input:0")
y = sess.graph.get_tensor_by_name("inputs/y-input:0")
accuracy = sess.graph.get_tensor_by_name("score/accuracy:0")
inference = sess.graph.get_tensor_by_name("inference/inference:0")现在就可以对测试集中的数据进行预测:
feed = {x: X_test, y: y_test}
print("Test set accuracy:", sess.run(accuracy, feed_dict=feed))使用scikit-learn输出一些其他的信息:
predictions = sess.run(inference, feed_dict={x: X_test})
print("Classification report:")
print(metrics.classification_report(y_test.ravel(), predictions))
print("Confusion matrix:")
print(metrics.confusion_matrix(y_test.ravel(), predictions))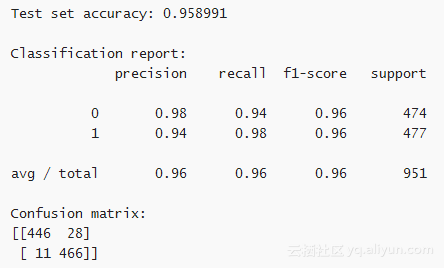
如上图所示,在测试集上的准确率达到了96%,比训练集上的准确率略低。这意味着训练出来的分类器对未知数据也能准确分类。分类结果报告(Classification report)和混淆矩阵( confusion matrix)说明有些样本是预测错误的。混肴矩阵说明女性样本中446个预测正确,28个预测错误。男性样本中466个预测正确,11个预测错误。这说明分类器在预测女性声音时会出现更多错误。
在下一节中,我们将会介绍如何将这个分类器运用到实际的app中。
以上为译文
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Getting started with TensorFlow on iOS》,由Matthijs Hollemans发布。
译者:李烽 ;审校:董昭男
文章为简译,更为详细的内容,请查看原文。中文译制文档见附件。
