

请输入标题 bcdef
一个简易非全自动的私人微信公众号文章爬虫,爬取文章标题、作者、封面、链接等相关资料
请输入标题 abcdefg

First
第一次写Python项目,选择从爬虫这个相对入门简单的方向入手,从中午开始写直到现在晚上9点整,花了将近9个小时琢磨,语法的不熟悉及对正则的模糊印象耽误了时间,经常写几行得查下字典、队列、元组的用法,不过还算顺利。
这个项目仅作为个人爬取私人公众号文章用,所有没有去爬IP库做动态IP,试着爬了一下某个个IP网站,但是后来把我本机IP给封了😅😅😅。于是没做这块了。
在微信爬取这块,调试代码的时候也是一开始把数据爬下来存在本地,从本地读取。
稍微复杂一点的地方是更多页加载的url参数拼接,及爬虫返回数据的正则匹配以及cookie的保存。
请输入标题 abcdefg

用到技术栈如下:
-
Python3.5
-
BeautifulSoup
-
Mysql5.7
-
pyenv(环境版本控制)
下面是一些细节方面
拼接请求URL参数
| param | value |
|---|---|
| uin | from response |
| key | from response |
| f | josn |
| frommsgid | commmsginfo->id |
| count | 10 |
| uin | 首次URL的uin |
| key | from response |
| pass_ticket | 首次URL的pass_ticket把%替换成%2525 |
| wxtoken | (此项为空) |
| x5 | 0 |
请输入标题 bcdef
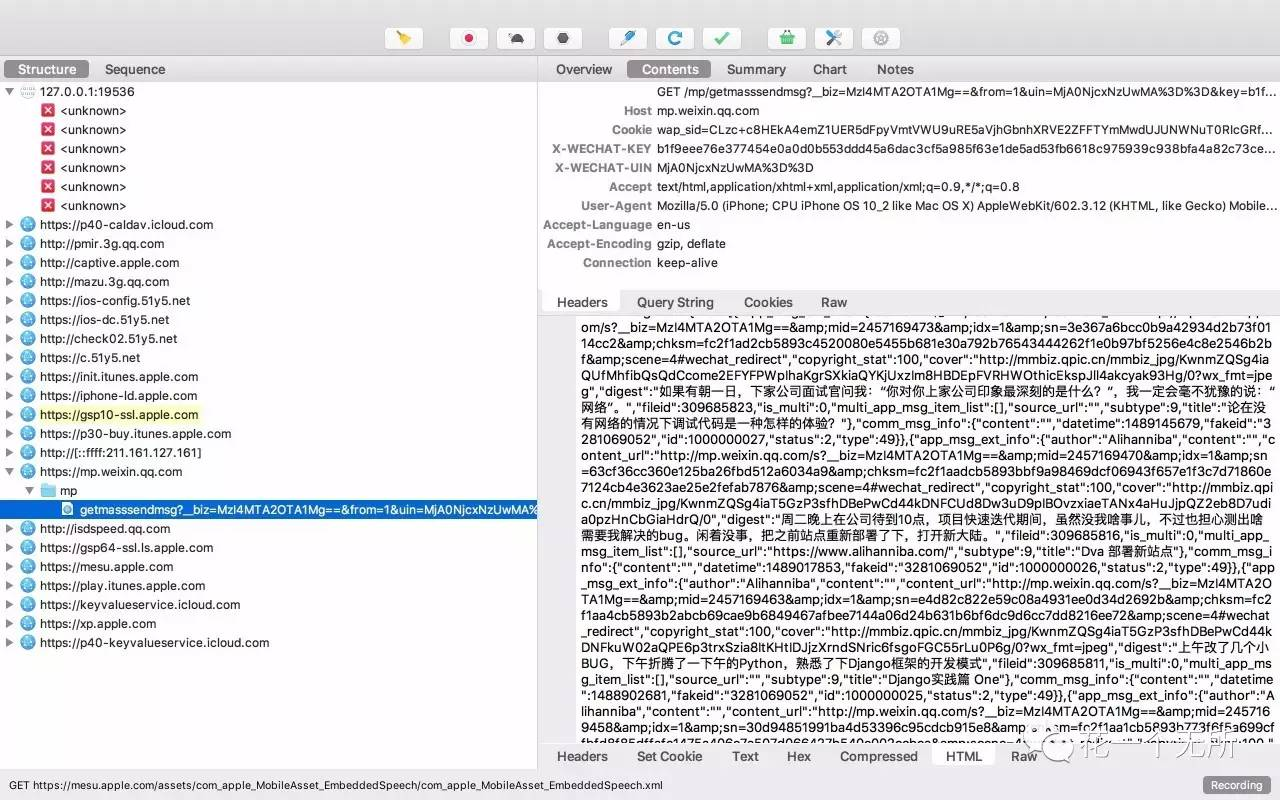
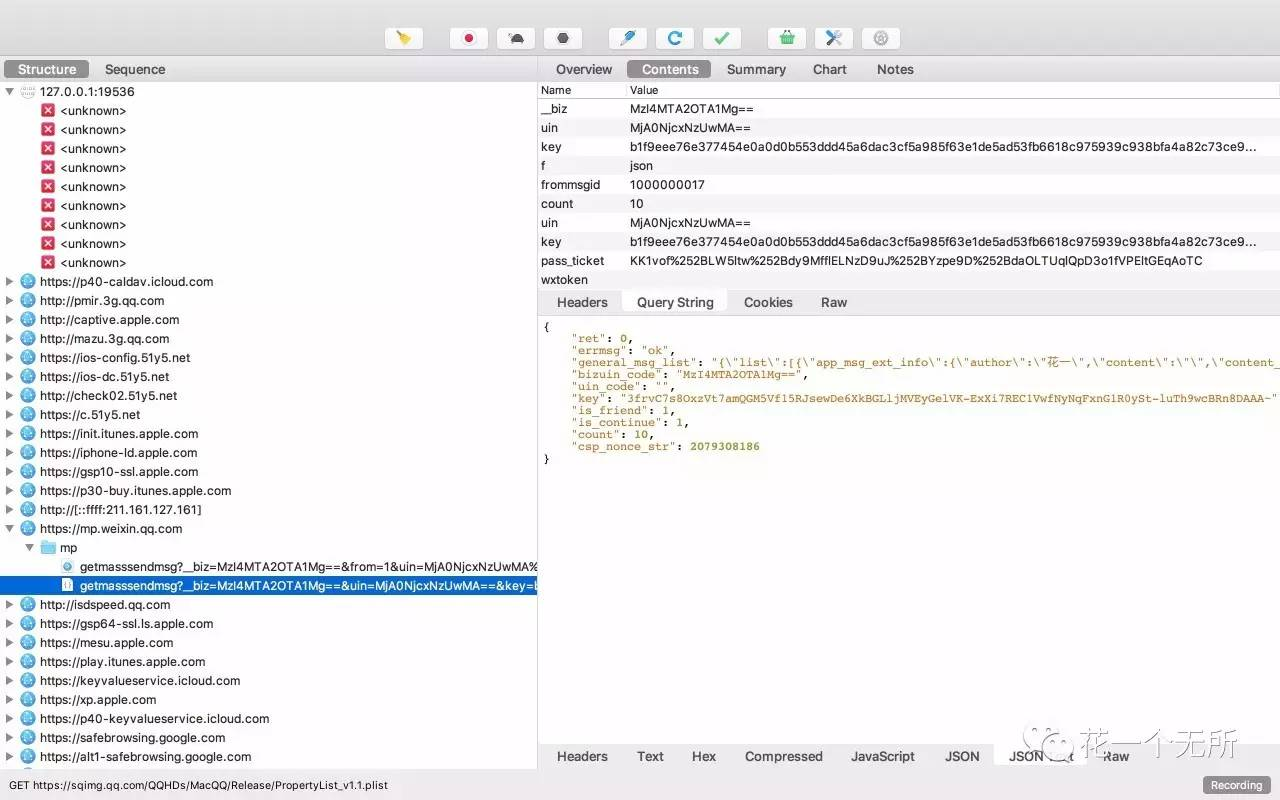
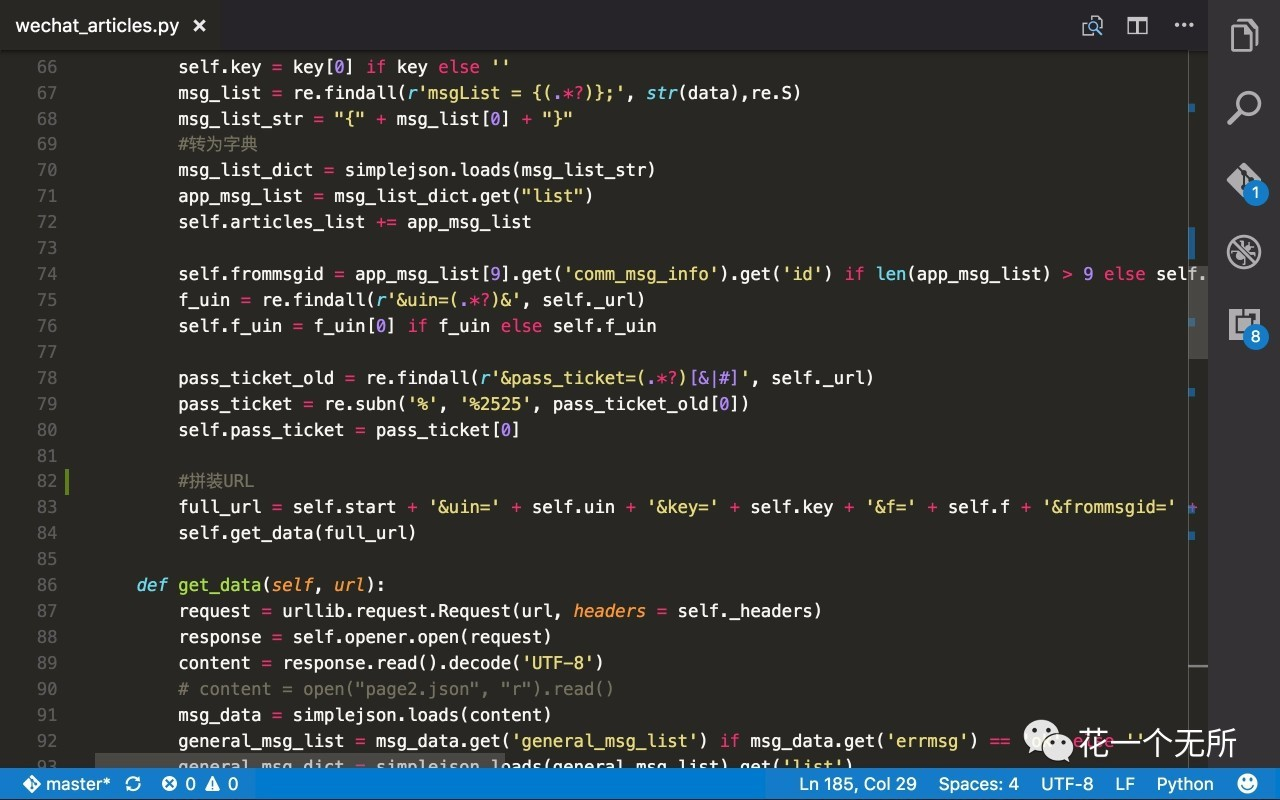
我是直接拿到我公众号历史记录链接用Charles抓包,拿到首页10条的请求链接,再用 Python 自带的request库去拿页面数据,根据返回数据,提取在script里面的关键信息,拼装第二页10条信息的请求链接,试了一下想一次拿20条不行,就算参数传20,微信固定只返回10条数据,除首页外请求其他页面都要带上cookie,否则请求会不通过,然后递归操作,直到数据拿完。再针对文章数据做分析。最后存库。
请输入标题 abcdefg

踩坑的地方是:
-
首页链接有效时长大概在15-30分钟左右,过了有效时长得重新抓包
-
请求需携带cookie
-
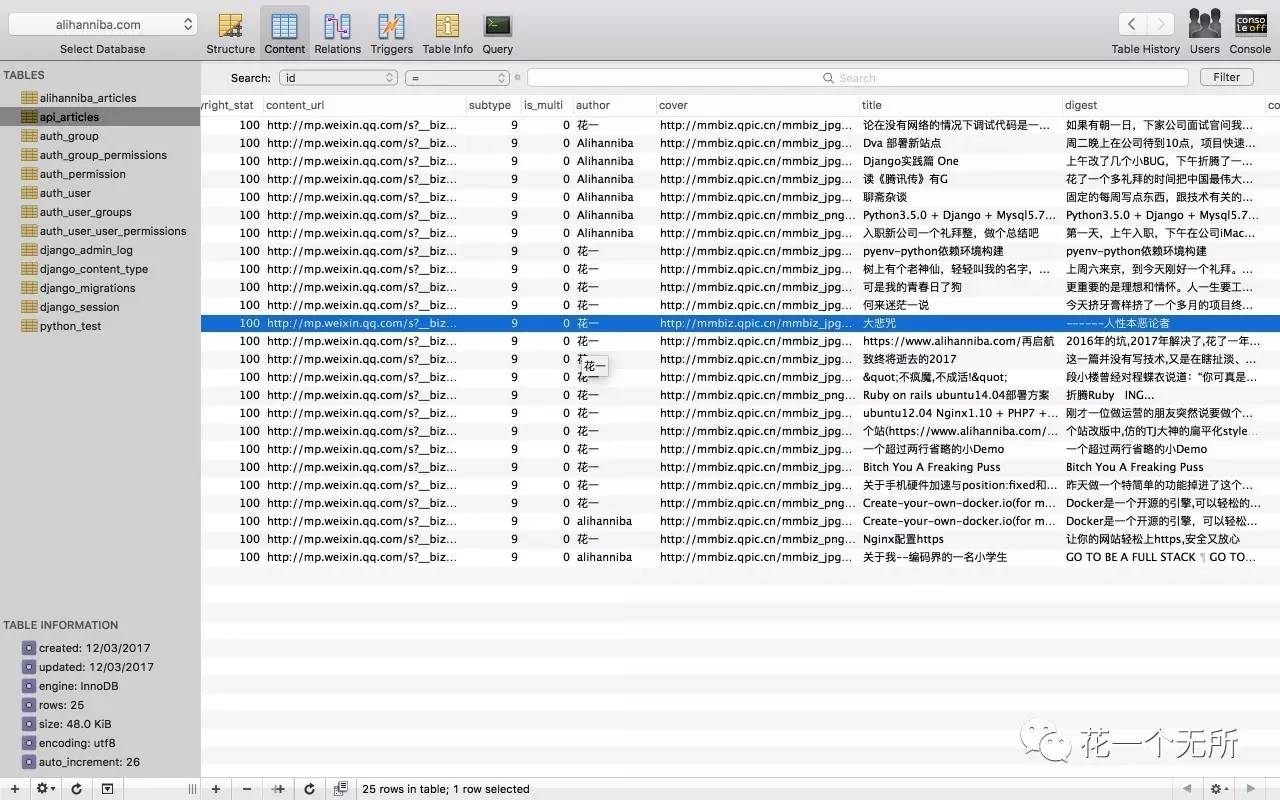
Mysql存库时无法自动识别数据里特殊字符,需自己做处理
-
数据库链接要设定字符编码
-
批量插入字段个数一定要数对😭😭😭
以下是抓包过程及存库
首页抓包
其他页抓包
主要代码
数据库数据
下一步想爬下view、star及评论数,代码在github,第一次写Python,请多指教!
