

- 原文地址:A crash course in just-in-time (JIT) compilers
- 原文作者:Lin Clark
- 译文出自:掘金翻译计划
- 译者:zhouzihanntu
- 校对者:Tina92、Germxu
本文是 WebAssembly 系列文章的第二部分。如果你还没有阅读过前面的文章,我们建议你 从头开始.
JavaScript 刚面世时运行速度是很慢的,而 JIT 的出现令其性能快速提升。那么问题来了,JIT 是如何运作的呢?
JavaScript 在浏览器中的运行机制
作为一名开发者,当你向网页中添加 JavaScript 代码的时候,你有一个目标和一个问题。
目标: 你想要告诉计算机做什么。
问题: 你和计算机使用的是不同的语言。
你使用的是人类语言,而计算机使用的是机器语言。即使你不愿承认,对于计算机来说 JavaScript 甚至其他高级编程语言都是人类语言。这些语言是为人类的认知设计的,而不是机器。
所以 JavaScript 引擎的作用就是将你使用的人类语言转换成机器能够理解的东西。
我认为这就像电影 降临 里人类和外星人试图互相交谈的情节一样。

在电影中,人类和外星人在尝试交流的过程里并不只是做逐字翻译。这两个群体对世界有不同的思考方式,人类和机器也是如此(我将在下一篇文章中详细说明)。
既然这样,那转化是如何发生的呢?
在编程中,我们通常使用解释器和编译器这两种方法将程序代码转化为机器语言。
解释器会在程序运行时对代码进行逐行转义。
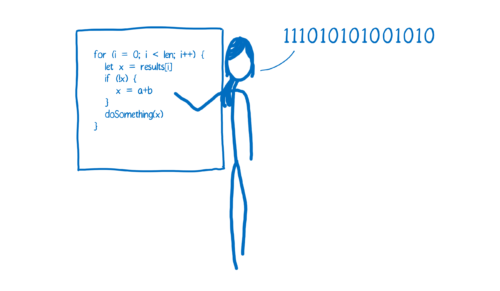
相反的是,编译器会提前将代码转义并保存下来,而不是在运行时对代码进行转义。
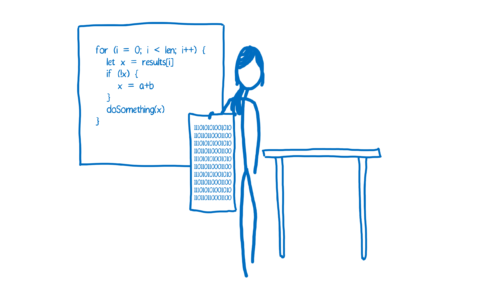
以上两种转化方式都各有优劣。
解释器的优缺点
解释器可以迅速开始工作。在运行代码之前,你不必等待所有的汇编步骤完成,只要开始转义第一行代码就可以运行程序了。
因此,解释器看起来自然很适用于 JavaScript 这类语言。对于 Web 开发者来说,能够快速运行代码相当重要。
这就是各浏览器在初期使用 JavaScript 解释器的原因。
但是当你重复运行同样的代码时,解释器的劣势就显现出来了。举个例子,如果在循环中,你就不得不重复对循环体进行转化。
编译器的优缺点
编译器的优缺点恰恰和解释器相反。
使用编译器在启动时会花费多一些时间,因为它必须在启动前完成编译的所有步骤。但是在循环体中的代码运行速度更快,因为它不需要在每次循环时都进行编译。
另一个不同之处在于编译器有更多时间对代码进行查看和编辑,来让程序运行得更快。这些编辑我们称为优化。
解释器在程序运行时工作,因此它无法在转义过程中花费大量时间来确定这些优化。
两全其美的解决办法 —— JIT 编译器
为了解决解释器在循环时重复编译导致的低效问题,浏览器开始将编译器混合进来。
不同浏览器的实现方式稍有不同,但基本思路是一致的。它们向 JavaScript 引擎添加了一个新的部件,我们称之为监视器(又名分析器)。监视器会在代码运行时监视并记录下代码的运行次数和使用到的类型。
起初,监视器只是通过解释器执行所有操作。
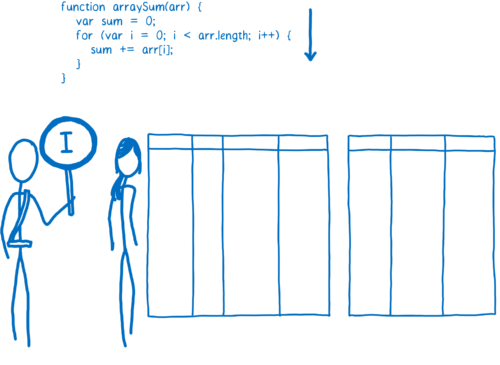
如果一段代码运行了几次,这段代码被称为 warm code;当这段代码运行了很多次时,它就会被称为 hot code。
基线编译器
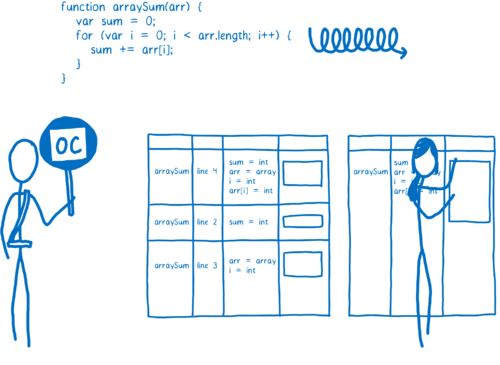
当一个函数运行了数次时,JIT 会将该函数发送给编译器编译,然后把编译结果保存下来。
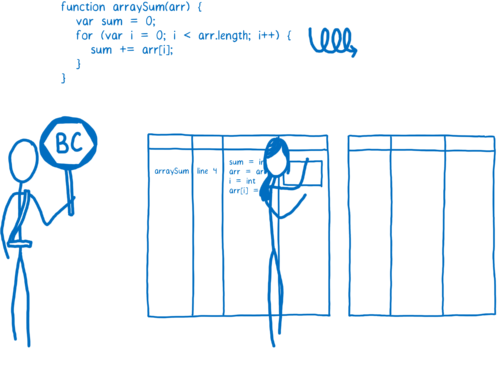
该函数的每一行都被编译成一个“存根”,存根以行号和变量类型为索引(这很重要,我后面会解释)。如果监视器监测到程序再次使用相同类型的变量运行这段代码,它将直接抽取出对应代码的编译后版本。
这有助于加快程序的运行速度,但是像我说的,编译器可以做得更多。只要花费一些时间,它能够确定最高效的执行方式,即优化。
基线编译器可以完成一些优化(我会在后续给出示例)。不过,为了不阻拦进程过久,它并不愿意在优化上花费太多时间。
然而,如果这段代码运行次数实在太多,那就值得花费额外的时间对它做进一步优化。
优化编译器
当一段代码运行的频率非常高时,监视器会把它发送给优化编译器。然后得到另一个运行速度更快的函数版本并保存下来。
为了得到运行速度更快的代码版本,优化编译器会做一些假设。
举例来说,如果它可以假设由特定构造函数创建的所有对象结构相同,即所有对象的属性名相同,并且这些属性的添加顺序相同,然后它就可以基于这个进行优化。
优化编译器会依据监视器监测代码运行时收集到的信息做出判断。如果在之前通过的循环中有一个值总是 true,它便假定这个值在后续的循环中也是 true。
但在 JavaScript 中没有任何情况是可以保证的。你可能会先得到 99 个结构相同的对象,但第 100 个就有可能缺少一个属性。
所以编译后的代码在运行前需要检查假设是否有效。如果有效,编译后的代码即运行。但如果无效,JIT 就认为它做了错误的假设并销毁对应的优化后代码。
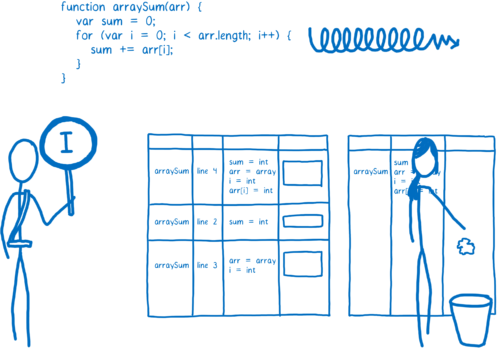
进程会回退到解释器或基线编译器编译的版本。这个过程被称为去优化(或应急机制)。
通常优化编译器会加快代码运行速度,但有时它们也会导致意外的性能问题。如果你的代码被不断的优化和去优化,运行速度会比基线编译版本更慢。
为了防止这种情况发生,许多浏览器添加了限制,以便在“优化-去优化”这类循环发生时打破循环。例如,当 JIT 尝试了 10 次优化仍未成功时,就会停止当前优化。
优化示例: 类型专门化
优化的类型有很多,但我只演示其中一种以便你理解优化是如何发生的。优化编译器最大的成功之一来自于类型专门化。
JavaScript 使用的动态类型系统在运行时需要多做一些额外的工作。例如下面这段代码:
function arraySum(arr) {
var sum = 0;
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
}执行循环中的 += 一步似乎很简单。看起来你可以一步就得到计算结果,但由于 JavaScript 的动态类型,处理它所需要的步骤比你想象的多。
假定 arr 是一个存放 100 个整数的数组。在代码执行几次后,基线编译器将为函数中的每个操作创建一个存根。sum += arr[i] 将会有一个把 += 依据整数加法处理的存根。
然而我们并不能保证 sum 和 arr[i] 一定是整数。因为在 JavaScript 中数据类型是动态的,有可能在下一次循环中的 arr[i] 是一个字符串。整数加法和字符串拼接是两个完全不同的操作,因此也会编译成非常不同的机器码。
JIT 处理这种情况的方法是编译多个基线存根。一段代码如果是单态的(即总被同一种类型调用),将得到一个存根。如果是多态的(即被不同类型调用),那么它将得到分别对应各类型组合操作的存根。
这意味着 JIT 在确定存根前要问许多问题。
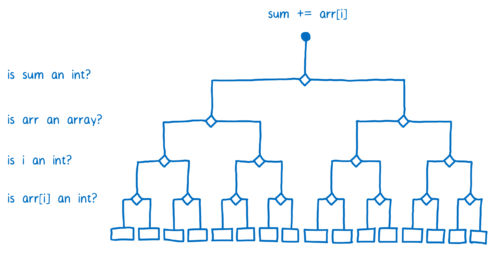
在基线编译器中,由于每一行代码都有各自对应的存根,每次代码运行时,JIT 要不断检查该行代码的操作类型。因此在每次循环时,JIT 都要询问相同的问题。
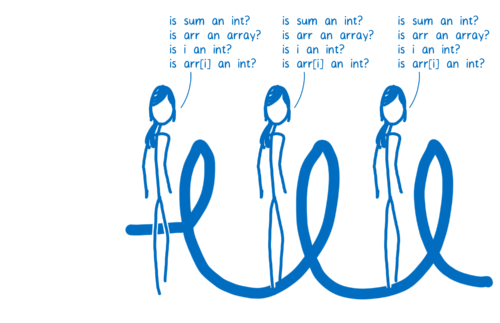
如果 JIT 不需要重复这些检查,代码运行速度会加快很多。这就是优化编译器的工作之一了。
在优化编译器中,整个函数会被一起编译。所以类型检查可以在循环开始前完成。
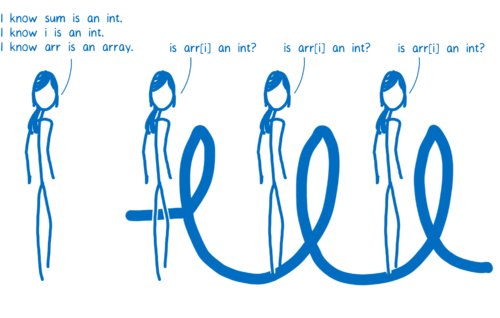
一些 JIT 编译器做了进一步优化。例如,在 Firefox 中为仅包含整数的数组设立了一个特殊分类。如果 arr 是在这个分类下的数组,JIT 就不需要检查 arr[i] 是否是整数了。这意味着 JIT 可以在进入循环前完成所有类型检查。
总结
简而言之,这就是 JIT。它通过监控代码运行确定高频代码,并进行优化,加快了 JavaScript 的运行速度,因此令大多数 JavaScript 应用程序的性能提高了数倍。
即使有了这些改进,JavaScript 的性能仍是不可预测的。为了加速代码运行,JIT 在运行时增加了以下开销:
- 优化和去优化
- 用于存储监视器纪录和应急回退时的恢复信息的内存
- 用于存储函数的基线和优化版本的内存
这里还有改进空间:除去以上的开销,提高性能的可预测性。这是 WebAssembly 实现的工作之一。
在下一篇文章中,我将对汇编做更多说明并解释编译器与它是如何工作的。
