

同步自我的博客
开门见山,由于我们项目的前端代码只有一个bundle,所有代码都在一个js文件里,随着功能不断的堆叠,体积已经到无法忍受的地步了(gzip后即将突破300k),导致首屏的时间不停的涨啊涨,最近一周富裕了一点人力赶紧做一次优化,暂时缓住了势头。
react+webapck的优化文章现在一搜一大把,这次只说说我的技术方案,以及我是如何分析和优化的。
技术方案
首先,我先说下,gzip,cdn等等前端优化手段我们都是有的,这次主要是为了解决bundle过大的问题。
我们项目的总体架构很简单易懂,react全家桶:react+redux,哈哈。共有三个系统,每个系统有自己单独的工程。由于是Hybrid应用,为了尽可能贴合APP内的切页效果,每个工程又都是采用的是单页+多页的形式。
由于系统多+单页多页混合,导致我们的路由比较混乱,本来打算上react-router进行一次大的改版,但是时间不够充裕,综合时间,开发成本角度来看,我定了一个简单并可以快速实施的方案:
- 抽取出三个工程的公共代码打包出一个
bundle。比如react,redux,redux-thunk以及一些polyfill,因为这些都是长时间不会变动的代码,所以可以最大程度的命中缓存,并且每次发布不需要重新下载这部分代码,在项目中就用externals的方案去引用这些代码。 code split,每个工程按照多页的路由做代码切割,每个多页路由都有自己的bundle。- 异步加载,每个多页路由都会对应各自的辅助页面和组件代码,都使用异步加载的方式。
如何优化bundle体积
code split+异步加载
这个很简单,使用webpack的requre.ensure就可以了
addPage(cb){
require.ensure([], function () {
cb({
Page1: require('../../pages/Page1'),
Page2: require('../../pages/Page2')
})
});
}这里Page1和Page2的代码都是异步加载的,具体的部分涉及到路由的设计,我们目前的方案非常的简单和随便,就不细说了。我也看了react-router的解决方案,觉得写起来复杂了一些,后续可能会在寻找更好的方案或者自己撸一个。
这里需要注意,虽然我们的js代码做了拆分,css文件还是希望打包成一个,所以需要给ExtractTextPlugin增加allChunks的配置。
new options.ExtractTextPlugin('[name]@[contenthash].css', {allChunks: true})externals
我将react,redux等等公用的代码打包成一个lib.js,然后暴露在全局变量上。每个工程里都会先去引用这个lib.js,在webpack的配置里就只需要配置上externals就可以了
其他插件
我们还用了一些其他插件来尽可能的优化体积
UglifyJsPlugin不多说了,代码混淆压缩DedupePlugin消除重复引用的模块,好像webpack2已内置,使用webpack2的可以忽略OccurrenceOrderPlugin让依赖次数多的模块靠前分到更小的id来达到输出更多的代码CommonsChunkPlugin这个我们没有用,但是大家可以去看看,对于多页应用它可以帮助你将一些公共代码打包
如何分析bundle过大的问题
在做代码拆分的时候我曾遇到过一个问题,如何确认我的代码已经是最优的了,如何确认我无法继续优化了?这就需要我们去查看,这个bundle究竟打包了哪些代码,是否这些都是我们需要的。
首先我推荐一个网址,这里介绍了很多webpack优化的工具。
我自己推荐两个bundle体积的可视化分析工具
具体如何使用我就不介绍了,它们的文档写的很清楚大家可以去文档上看,他们都可以很清楚的看到每个bundle分别打包了哪些代码,哪些占据了最大的体积,也可以观察哪些代码其实是无用的可以优化掉的。
这里我还遇到过一个问题,比如我在detail.chunk.js里发现引入了一个loading组件,但是我映象里详情页并没有引入loading组件呀,这时候就需要去寻找loading是被谁依赖了。之前我都是用webstorm的find usages一点点的去看引用关系,其实可以用webpack提供的一个官方工具来做这件事。
首先,你需要这么启动webpack
webpack --profile --json > stats.json此时会生成一个stats.json文件,之后在官方分析工具里上传文件即可对你的bundle进行分析。
这里我用官方的例子简单说下
上传你的
json文件,长传后会看到这么一个界面,会简单描述你的webpack的版本,有多少modules,多少chunks等等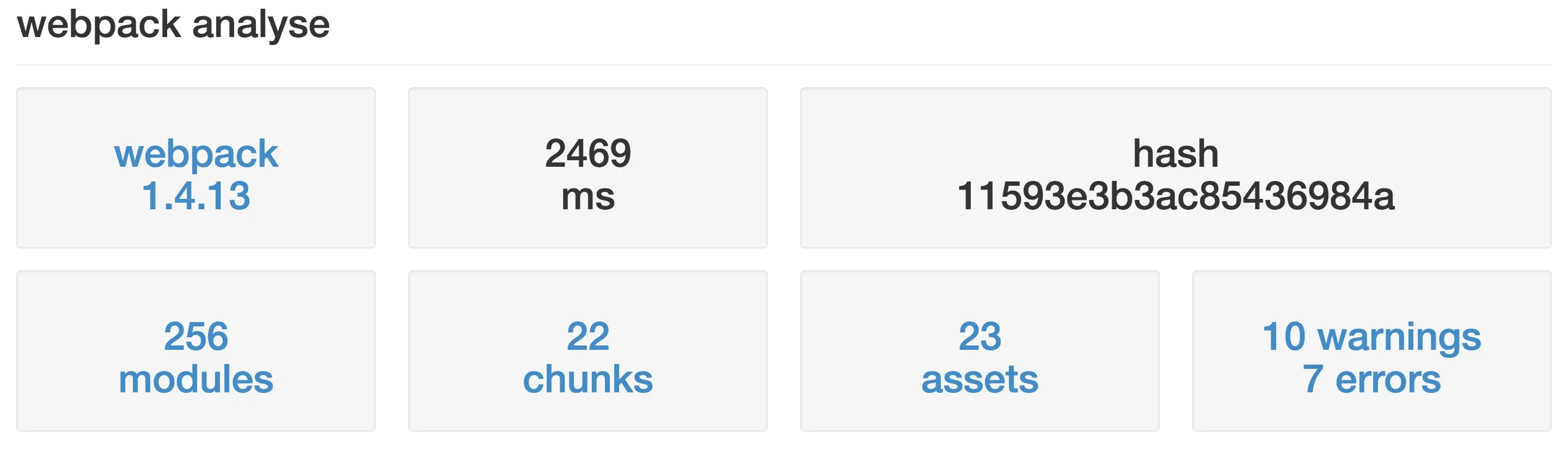
1 点击
chunks,可以看到所有chunks的描述,左边是chunks的id,然后有namse,有多少modules,大小,引用它的chunks是谁、即parents,假如我们需要分析id为1的chunk,只需要点击左边的id
2 这里你可以看到更详细的信息,这里最重要的是两个,
reasons是引用这个chunks的模块,modules是这个chunks所引用的modules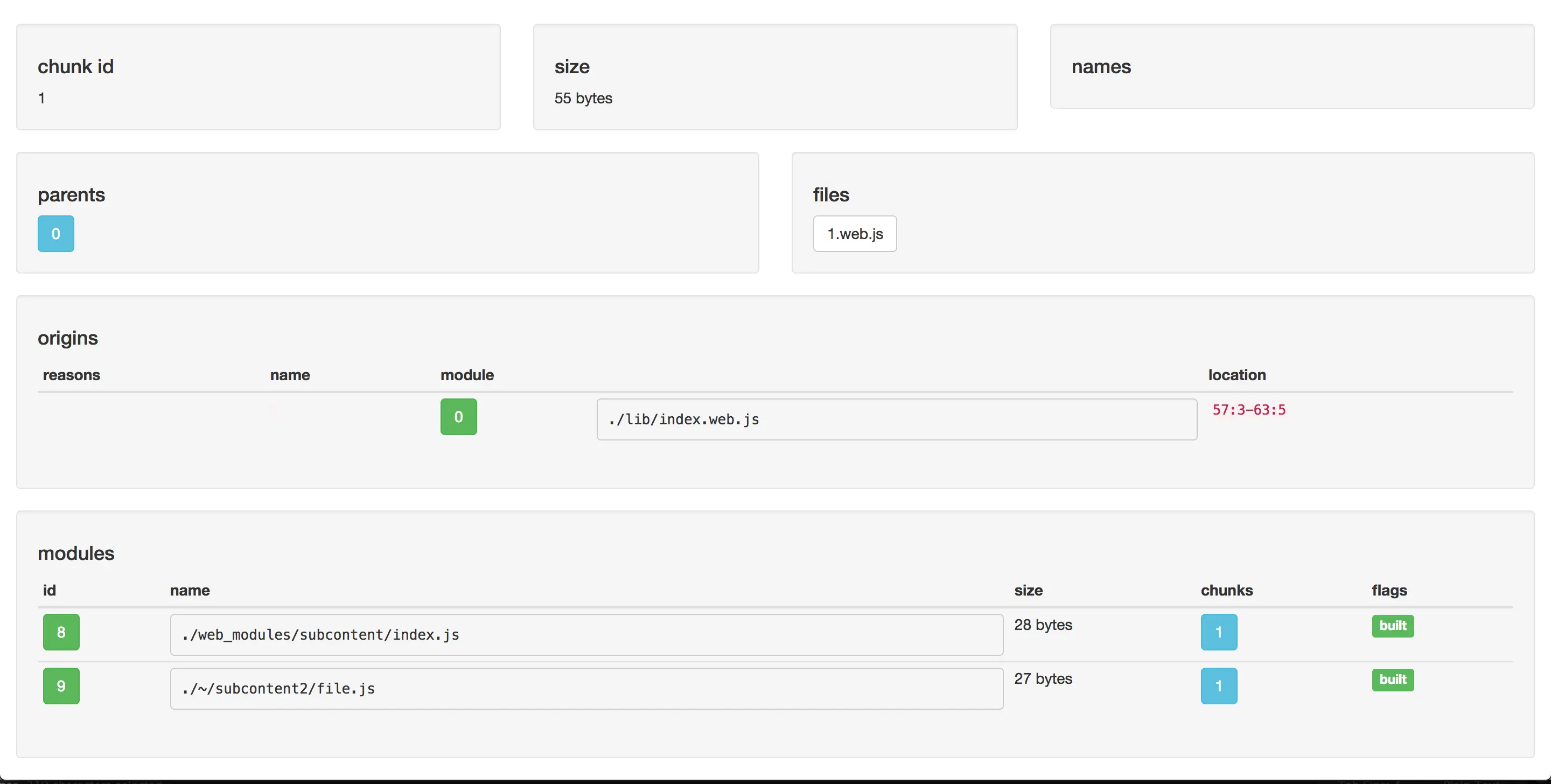
3 这里你发现有一个模块不是你想要的
modules,你只需要点击这个模块的id,再去查看reasons就可以看到这个模块是被谁引入的
如何优化本地开发体验和打包速度
webpack吐槽的常态 —— 打包慢,这里说一下我们这边做过的优化。
缩小文件搜索范围
将resolve.modules配置为node_modules,像使用 impot _ from "lodash"这种时webpack遍历向上递归查到node_modules,但通常只有一个node_modules,为了减少可以直接写明node_modules的地址
loader也可以设置需要生效的目录地址
比如babel的loader可以只对src目录里的代码进行编译,忽略庞大的node_modules
{
test:/\.js$/,
loader:'babel-oader',
include:path.resolve(__dirname,'src')
}使用alias
发布到npm的库大多包含两个目录,一个是放cmd模块化的lib目录,一个是所有文件合并成的dist目录,多数入口文件是指向lib的。默认情况下webpack会去读lib目录下的入口文件再去递归加载其他以来的文件,这个过程非常耗时,alias可以让webpack直接使用dist目录的整体文件减少递归
使用noParse
有些库是自成一体,不需要依赖别的库的,webpack无需解析他们的依赖,可以配置这些文件脱离Webpack解析。
happyPack
happyPack的文档也写的很好,就不复制粘贴了,大家可以自行去阅读文档,简单地说,它主要是利用多进程+缓存使得build更快,这大幅减少了我们在编译机上编译的时间。
后评估
先说说优化完后的结果,由于react的体积过大,lib就有60k+,基本已经不能继续优化了,加上我们的路由设计的很不好,首屏的bundle依然有70k+,总的来说,首屏从280k降低到140k左右。
但是,根据监控的效果来看,页面js下载的总体时间和白屏时间都只降低了30%左右,这并不符合我的心理预期,想了想除了http请求变多以外并没有别的副作用,后续会继续深入的分析一下为什么优化的效果没达到预期。
