

SQLAdvisor 是由美团点评公司北京 DBA 团队开发维护的 SQL 优化工具:输入SQL,输出索引优化建议,现已开源。 它基于 MySQL 原生词法解析,再结合 SQL 中的 where 条件以及字段选择度、聚合条件、多表 Join 关系等最终输出最优的索引优化建议。开发团队称目前 SQLAdvisor 在美团内部大量使用,较为成熟、稳定,且开源版本和内部使用版本保持完全一致,希望与业内有类似需求的团队,一起打造一款优秀的 SQL 优化产品。
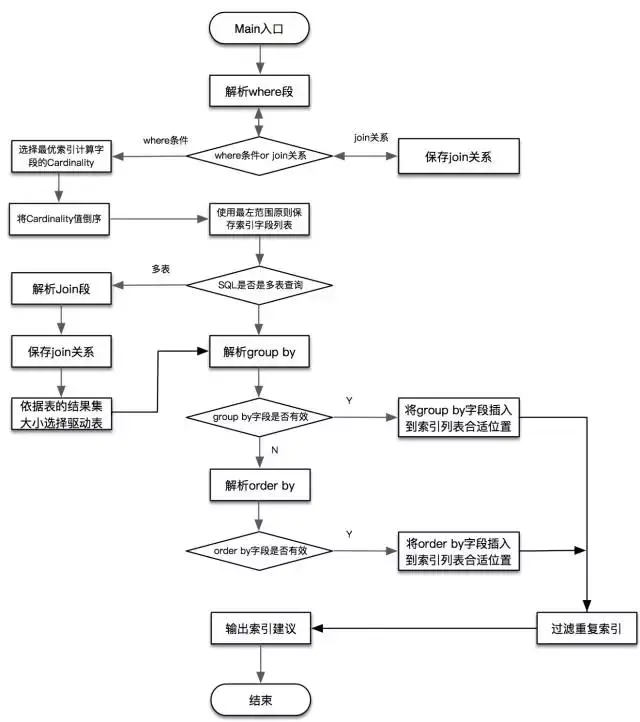
SQLAdvisor 架构流程图:
SQLAdvisor 使用举例
sql: SELECT id FROM crm_loan WHERE id_card = '1234567'
cmd: ./sqladvisor -h xx -P xx -u xx -pxx -d xx -q "SELECT id FROM crm_loan WHERE id_card = '1234567'"
SQLAdvisor输出: alter table crm_loan add index idx_id_card(id_card)SQLAdvisor 的优点
-
基于 MySQL 原生词法解析,充分保证词法解析的性能、准确定以及稳定性;
-
支持常见的 SQL(Insert/Delete/Update/Select);
-
支持多表 Join 并自动逻辑选定驱动表;
-
支持聚合条件 Order by 和 Group by;
-
过滤表中已存在的索引。
SQLAdvisor 原理介绍
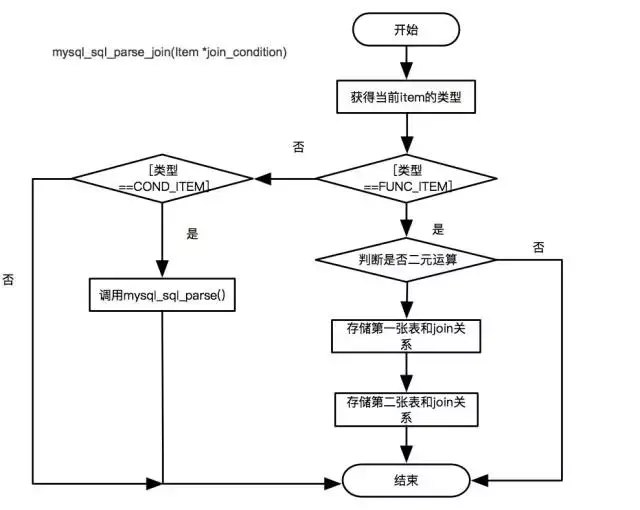
Join 处理
-
Join语法分为两种:Join on 和 Join using,且 Join on 有时会存在 where 条件中。
-
分析 Join 条件首先会得到一个 nested_join 的 table list,通过判断它 join_using_fields 字段是否为空来区分 Join on 与 Join using。
-
生成的 table list 以二叉树的形式进行存储,以后序遍历的方式对二叉树进行遍历。
-
生成内部解析树时,right Join 会转换成 left Join。
-
Join 条件会存在当层的叶子节点上,如果左右节点都是叶子节点,会存在右叶子节点。
-
每一个非叶子节点代表一次 Join 的结果。
上述实现时,涉及的函数为:mysql_sql_parse_join(TABLE_LIST join_table) mysql_sql_parse_join(Item join_condition) ,主要流程图如下:
where 处理
-
主要是提取 SQL 语句的 where 条件。where 条件中一般由 AND 和 OR 连接符进行连接,因为 OR 比较难以处理,所以忽略,只处理 AND 连接符。
-
由于 where 条件中可以存在 Join 条件,因此需要进行区分。
-
依次获取 where 条件,当条件中的操作符是 like,如果不是前缀匹配则丢弃这个条件。
-
根据条件计算字段的区分度按照高低进行倒序排,如果小于30则丢弃。同时使用最左原则将 where 条件进行有序排列。
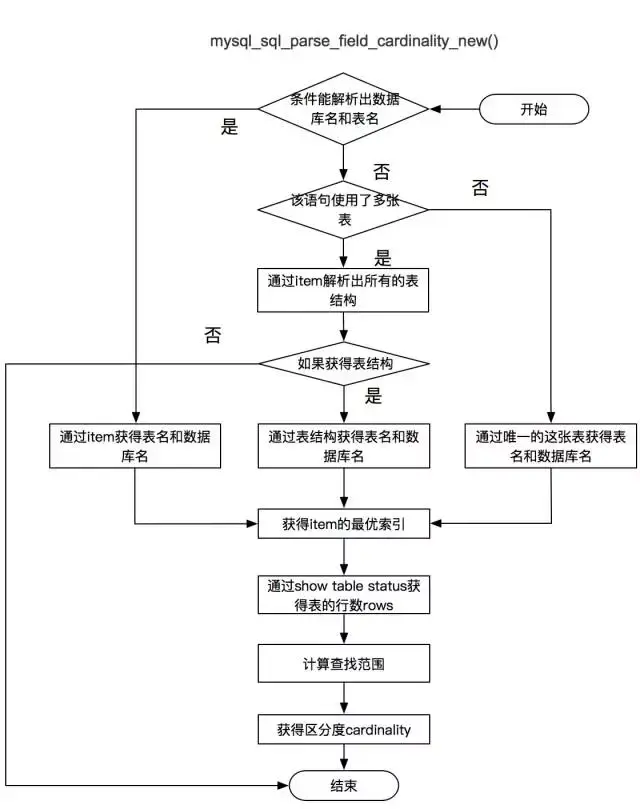
计算区分度
-
通过 “show table status like” 获得表的总行数 table_count。
-
通过计算选择表中已存在的区分度最高的索引 best_index,同时Primary key > Unique key > 一般索引。
-
通过计算获取数据采样的起始值offset与采样范围rand_rows:
-
offset = (table_count / 2) > 10W ? 10W : (table_count / 2)
-
rand_rows =(table_count / 2) > 1W ? 1W : (table_count / 2)
-
使用select count(1) from (select field from table force index(best_index) order by cl.. desc limit rand_rows) where field_print 得到满足条件的rows。
-
cardinality = rows == 0 ? rand_rows : rand_rows / rows;
-
计算完成选择度后,会根据选择度大小,将该条件添加到该表中的备选索引中。
主要涉及的函数为:mysql_sql_parse_field_cardinality_new() 计算选择度。
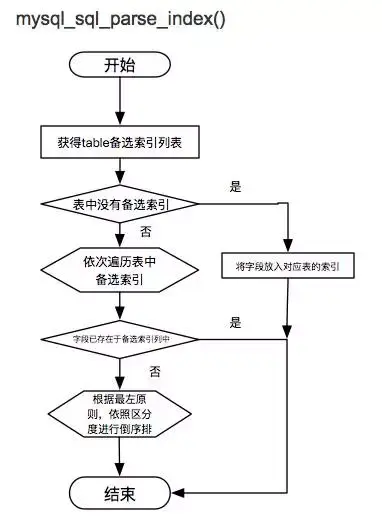
添加备选索引
-
mysql_sql_parse_index()将条件按选择度添加到备选索引链表中。
-
上述两函数的流程图如下所示:
Group 与 Order 处理
-
Group 字段与 Order 字段能否用上索引,需要满足如下条件:
-
涉及到的字段必须来自于同一张表,并且这张表必须是确定下来的驱动表。
-
Group by 优于 Order by, 两者只能同时存在一个。
-
Order by 字段的排序方向必须完全一致,否则丢弃整个 Order by 字段列。
-
当 Order by 条件中包含主键时,如果主键字段为 Order by。 字段列末尾,忽略该主键,否则丢弃整个 Order by 字段列。
-
整个索引列排序优先级:等值>(group by | order by )> 非等值。
-
该过程中设计的函数主要有:
-
mysql_sql_parse_group() 判断 Group 后的字段是否均来自于同一张表。
-
mysql_sql_parse_order() 判断 Order 后的条件是否可以使用。
-
mysql_sql_parse_group_order_add() 将字段依次按照规则添加到备选索引链表中。
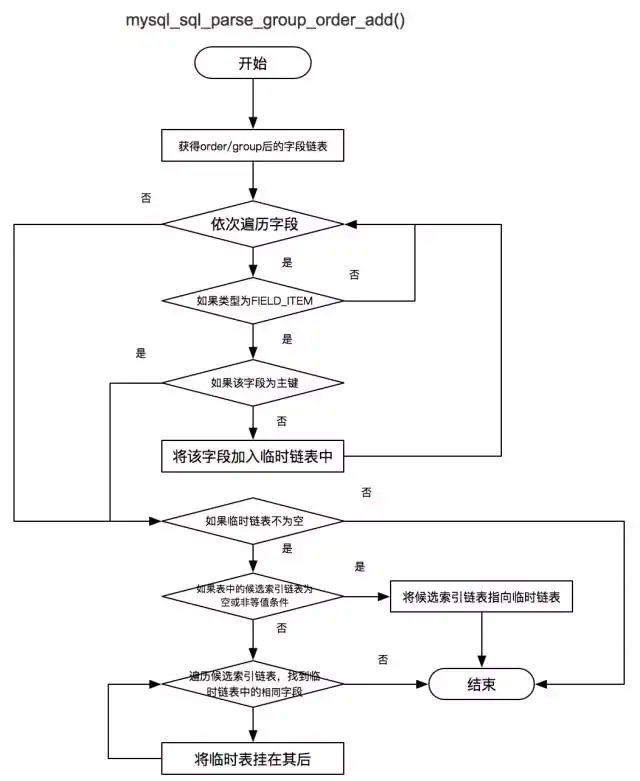
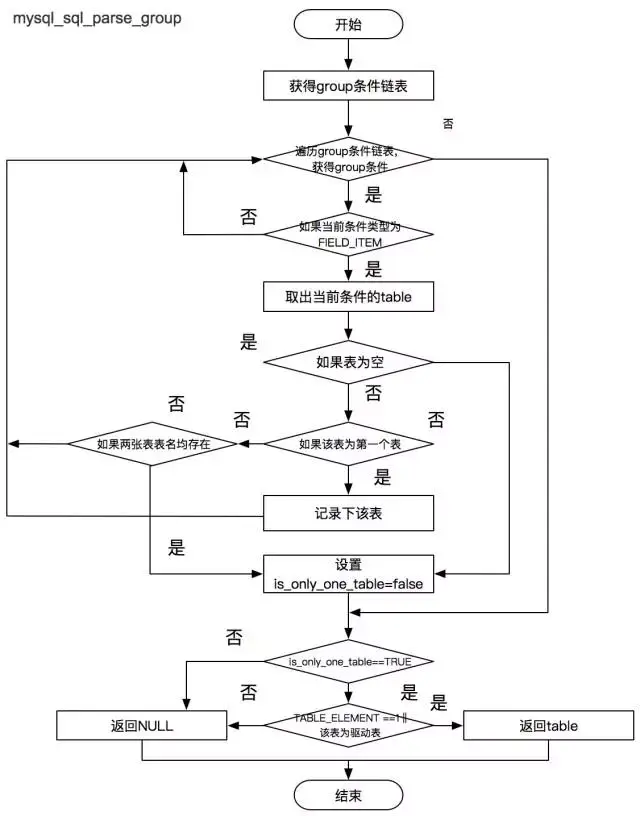
驱动表选择
-
经过前期的 where 解析、Join 解析,已经将 SQL 中表关联关系存储起来,并且按照一定逻辑将候选驱动表确定下来。
-
在侯选驱动表中,按照每一张表的侯选索引字段中第一个字段进行计算表中结果集大小。
-
使用 explain select * from table where field 来计算表中结果集。
-
结果集小最小的被确为驱动表。
-
步骤中涉及的函数为:final_table_drived(),在该函数中,调用了函数 get_join_table_result_set() 来获取每张驱动候选表的行数。
添加被驱动表备选索引
-
通过上述过程,已经选择驱动表,也通过解析保存了语句中的条件。
-
由于选定了驱动表,因此需要对被驱动表的索引,根据 Join 条件进行添加。
-
该过程涉及的函数主要是:mysql_index_add_condition_field(),流程如下:
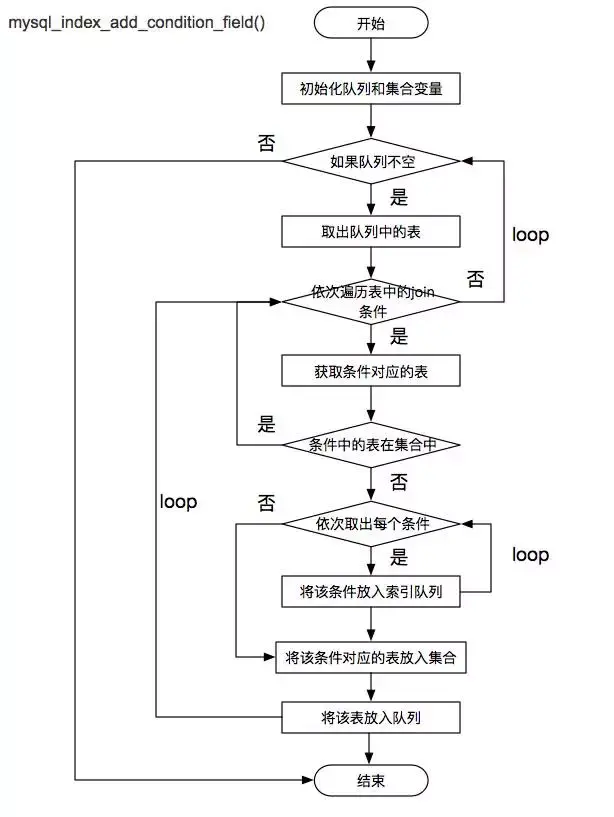
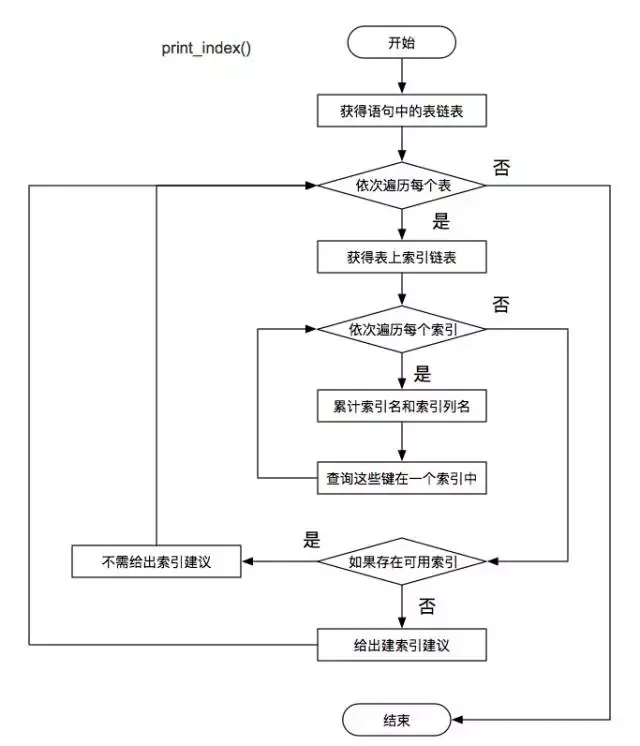
输出建议
-
通过上述步骤,已经将每张表的备选索引键全部保存。此时,只要判断每张表中的候选索引键是否在实际表中已存在。没有索引,则给出建议增加对应的索引。
-
该步骤涉及的函数是:print_index() ,主要的流程图为:
来源:美团点评技术团队
