

1. 前言
Vue 2.x 、React 都引入了 Virtual Dom 的概念,来更加高效地更新 dom 节点,提升渲染性能。为了能更深入地了解 Virtual Dom 的相关细节,决定将 Matt-Esch/virtual-dom 作为学习对象。这个项目很纯粹,也很清晰地展示了如何利用虚拟节点来更新视图的整个过程。
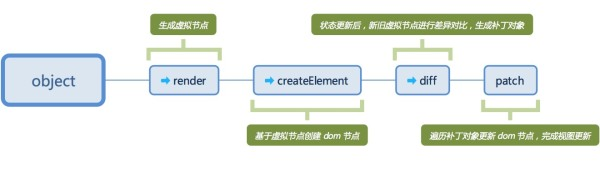
总体来说,大致分为以下几个阶段。
 在依次介绍几个阶段之前,先来明确几个概念,对后续的学习很有帮助。
在依次介绍几个阶段之前,先来明确几个概念,对后续的学习很有帮助。
2. 基本概念
VNode 虚拟节点,它可以代表一个真实的 dom 节点。通过 createElement 方法能将 VNode 渲染成 dom 节点。
VText 虚拟文本节点,代表了一个真实的文本节点。内容中若有 HTML 会被转义。
Hooks 钩子方法,如给节点注册 ev-click 等事件。
Thunk 方法允许开发者参与 diff 过程。如对于某节点,能够预先判断状态不会发生改变,则可以通过此方法,在 diff 过程中直接返回旧 VNode 。
Widget 和 Thunk 的作用有点相似,但它参与的是 patch 的过程。它能定制如何渲染成最终的 dom 节点。如要求某个状态只为偶数时,重新渲染等。
VPatch
VPatch 权且称之为「补丁对象 」,它描述了对于某个节点的具体操作,比如删除,插入,排序等等。
3. render - 创建虚拟节点
从 render 出发,我们将一步步探索 virtual-dom 的整个过程。 先从 render 实现谈起。
// @virtual-hyperscript/index.js
tag = parseTag(tagName, props);
由于 tagName 支持 #ID , div , .class , div#ID 等形式,第一步需要对其进行解析:
// @virtual-hyperscript/parse-tag.js
var classIdSplit = /([\.#]?[a-zA-Z0-9\u007F-\uFFFF_:-]+)/;
var tagParts = split(tag, classIdSplit);
var tagName = null;
if (notClassId.test(tagParts[1])) {
tagName = 'DIV';
}
这里比较巧妙,通过匹配 class 和 id 的组合正则对 tagName 进行切割,得到一个数组,一次性将标签,类名, id 抽离出来。之后分别对其进行预处理。最后一行:
// @virtual-hyperscript/parse-tag.js
return props.namespace ? tagName : tagName.toUpperCase();
// @virtual-hyperscript/index.js
transformProperties(props);
if (children !== undefined && children !== null) {
addChild(children, childNodes, tag, props);
}
props 中并不全是像 id , class 等可以直接设置到 dom 元素上的属性值,还支持像 ev-click 等事件的注册。 所以需要一个方法对其进行预处理,transformProperties 干了这活。在标签名和属性处理完后,接着对不同类型的子节点进行处理生成相应的虚拟节点,最后组装成 childNodes 数组。
标签、属性、子节点都已就位,主角 VNode 出场:
// @virtual-hyperscript/index.js
return new VNode(tag, props, childNodes, key, namespace);
进入 VNode ,看看里面都发生了啥?
// @vnode/vnode.js
// 部分逻辑简化
for (var propName in properties) {
if (properties.hasOwnProperty(propName)) {
...
var property = properties[propName]
if (isVHook(property) && property.unhook) {
if (!hooks) {
hooks = {}
}
hooks[propName] = property
}
...
}
}
for (var i = 0; i < count; i++) {
var child = children[i]
if (isVNode(child)) {
descendants += child.count || 0
if (...) {
hasWidgets = true
}
if (...) {
hasThunks = true
}
if (...) {
descendantHooks = true
}
} else if (...) {
hasThunks = true
} else if (...) {
hasThunks = true
}
}
这里省略了部分代码,让逻辑看起来更加清晰。过程如下:
- 先将属性中所有 Hook 注册的事件缓存。
- 遍历所有子节点,统计子孙节点的数量,同时打上各种标记,比如子节点是否有 Widget , 是否有 Thunk 等等。
这些标记以及数量统计,现在还看不出什么价值,在后面的几个阶段中,会被用到。不过,按常规来猜测的话,无非是冗余数据,为了后续的一些查找遍历节省时间,提升性能。
4. createElement - 创建 dom 节点
// @vdom/create-element.js
vnode = handleThunk(vnode).a
if (isWidget(vnode)) {
return vnode.init()
} else if (isVText(vnode)) {
return doc.createTextNode(vnode.text)
}
VNode 在上个阶段已经生成,接下来进入 createElement ,负责将 VNode 渲染成 dom 节点。过程如下:
- createElement 由于支持传 Thunk ,所以为了能统一拿到 VNode ,handleThunk 需要在这进行转换。
- 处理掉两个和 dom 生成直接相关的类型 Widget 和 Text 。
特殊 case 处理完了,接着就是处理 VNode 了:
// @vdom/create-element.js
var node = (vnode.namespace === null) ?
doc.createElement(vnode.tagName) :
doc.createElementNS(vnode.namespace, vnode.tagName)
var props = vnode.properties
applyProperties(node, props)
var children = vnode.children
for (var i = 0; i < children.length; i++) {
var childNode = createElement(children[i], opts)
if (childNode) {
node.appendChild(childNode)
}
}
过程如下:
- 通过 createElement/createElementNS 创建 dom 元素。
- 用 applyProperties 方法将属性 props 通过 setAttribute / removeAttribute / dom[key] = value 的方式设置到 dom 上。
- 当前节点自身生成好后,遍历子元素,递归创建节点,将子节点 appendChild 到当前 node 中。
这样,一个真实完整的 dom 节点就创建好。
5. diff - 新旧 VNode 差异对比
// @vtree/diff.js
function diff(a, b) {
var patch = { a: a }
walk(a, b, patch, 0)
return patch
}
当有状态更新后,会 render 出一个新的 VNode 。virtual-dom 则通过 diff 方法比较出其中的差异,生成一个 patch 对象。结构如下:
patch = {
0: {VPatch},
1: {VPatch},
...
a: VNode
};
最后 a 的 value 为旧 VNode。数字 key 代表旧 VNode 子节点的索引,value 为相应的 VPatch 或者 Array<VPatch>。通过 walk 方法的递归将一个个 VPatch 打进 patch 中。
为了方便理解,可以这么描述,walk 是用来对比 a b 两个新旧 VNode,如检测到其中第 index 节点有状态更新,则将 VPatch 打到 patch[index] 上。
// @vtree/diff.js
function walk(a, b, patch, index) {
// 全等则直接返回
if (a === b) {
return
}
var apply = patch[index]
// 当新旧节点类型不同时,标记是否清除旧节点的所有属性以及状态
var applyClear = false
// case: 对 Thunk 的处理
// thunks 方法内部将 a , b 转成 VNode ,再调用 diff(a, b) 进行递归
if (isThunk(a) || isThunk(b)) {
thunks(a, b, patch, index)
}
// case: 对新节点为 null 的处理
else if (b == null) {
// case: 旧元素不是 Widget
// 调用 clearState 方法,该方法干了两件事
//
// unhook():
// 通过将该元素以及其子孙元素的所有 hook 属性全都设置为 null 的方式,释放 hook 绑定的方法。
//
// destroyWidgets():
// 递归删除该元素中所有 Widget。
// 当然这里的删除,并不是硬删除,而是新建一个 Remove-VPatch。
if (!isWidget(a)) {
clearState(a, patch, index)
apply = patch[index]
}
// 删除自身,旧元素,无论是它是 Widget 还是 VNode。
// 所以,源码中有这样一段注释
// "This prevents adding two remove patches for a widget."
// 如果旧元素 a 本身是一个 Widget,而上面的条件不判断,会出现有什么情况呢?
// 就会发现在 destroyWidgets 中递归时,就已经自身打了个 Remove-VPatch
// 如果这里删除自身再次打一个,显然就重复了。
apply = appendPatch(apply, new VPatch(VPatch.REMOVE, a, b))
}
// case: 对 VNode 的处理
else if (isVNode(b)) {
if (isVNode(a)) {
// case: 新旧元素节点相同,只是更新了属性
if (a.tagName === b.tagName &&
a.namespace === b.namespace &&
a.key === b.key) {
// 对比出更新的属性
var propsPatch = diffProps(a.properties, b.properties)
if (propsPatch) {
// 打 Props-VPatch
apply = appendPatch(apply,
new VPatch(VPatch.PROPS, a, propsPatch))
}
// 对比子孙元素,递归
apply = diffChildren(a, b, patch, apply, index)
} else {
// 新旧同为 VNode ,但标签不用,直接新节点更新旧节点
apply = appendPatch(apply, new VPatch(VPatch.VNODE, a, b))
applyClear = true
}
} else {
// 新节点为 VNode ,旧节点不是,直接新节点更新旧节点
apply = appendPatch(apply, new VPatch(VPatch.VNODE, a, b))
applyClear = true
}
}
// case: 对 VText 的处理
else if (isVText(b)) {
// 新节点为 VText ,旧节点不是,直接新节点更新旧节点
if (!isVText(a)) {
apply = appendPatch(apply, new VPatch(VPatch.VTEXT, a, b))
applyClear = true
}else if (a.text !== b.text) {
// 同为 VText ,内容不同,直接新节点更新旧节点
apply = appendPatch(apply, new VPatch(VPatch.VTEXT, a, b))
}
}
// case: 对 Widget 的处理
else if (isWidget(b)) {
if (!isWidget(a)) {
applyClear = true
}
// 新节点为 Widget,旧节点无论是否为 Widget,都直接更新
apply = appendPatch(apply, new VPatch(VPatch.WIDGET, a, b))
}
if (apply) {
patch[index] = apply
}
if (applyClear) {
clearState(a, patch, index)
}
}
walk 方法并没有返回值,由于 patch 是传引用,直接对它进行了修改。这里需要着重说明的是 diffChildren 方法,它主要用来遍历和递归子节点。另外,其中的 reorder 方法特别值得关注。
// @vtree/diff.js
function diffChildren(a, b, patch, apply, index) {
var aChildren = a.children
// 对新旧节点的子节点进行一个对比,重新排序,生成一个操作队列对象
// 内容暂且略过,后面会着重来谈。
// {
// children: [],
// moves: {
// removes: removes,
// inserts: inserts
// }
// }
var orderedSet = reorder(aChildren, b.children)
var bChildren = orderedSet.children
var aLen = aChildren.length
var bLen = bChildren.length
var len = aLen > bLen ? aLen : bLen
for (var i = 0; i < len; i++) {
var leftNode = aChildren[i]
var rightNode = bChildren[i]
index += 1
// 旧节点子节点为 null ,新子节点直接插入
if (!leftNode) {
if (rightNode) {
apply = appendPatch(apply,
new VPatch(VPatch.INSERT, null, rightNode))
}
} else {
// 递归
walk(leftNode, rightNode, patch, index)
}
// 跳过这个子节点
if (isVNode(leftNode) && leftNode.count) {
index += leftNode.count
}
}
// 是否有需要移动的操作
// 只有当有节点有 key 属性时,才会需要移动。
if (orderedSet.moves) {
apply = appendPatch(apply, new VPatch(
VPatch.ORDER,
a,
orderedSet.moves
))
}
return apply
}
6. patch - 将 patch 更新 dom 节点
通过上一步差异对比,已经拿到 patch 对象,接下来,需要做的,就是依照这个 patch 对象,将 dom 进行更新。在 patchRecursive 中,通过遍历 patch 对象依次操作相应 dom 节点。
// @vdom/patch.js
function patchRecursive(rootNode, patches, renderOptions) {
var indices = patchIndices(patches)
if (indices.length === 0) {
return rootNode
}
var index = domIndex(rootNode, patches.a, indices)
var ownerDocument = rootNode.ownerDocument
if (!renderOptions.document && ownerDocument !== document) {
renderOptions.document = ownerDocument
}
for (var i = 0; i < indices.length; i++) {
var nodeIndex = indices[i]
rootNode = applyPatch(rootNode,
index[nodeIndex],
patches[nodeIndex],
renderOptions)
}
return rootNode
}
前面有提过,patches 对象的数字 key 为子节点索引,value 为相应的 VPatch。那么看看,这里做了些什么,过程如下:
- 通过 patchIndices 方法将索引取出组成数组 indices。
- 通过 domIndex 方法将节点索引和对应的 dom 节点映射上,生成 index 对象。
在 domIndex 方法中有个细节需要提一下。代码如下:
// @vdom/dom-index.js
indices.sort(ascending)
可能大家会想了,patch 对象中不都已经是这样的吗?
{
0: { ... },
1: { ... },
2: { ... },
a: { ... }
}
那么通过 patchIndices 中 for in 遍历 patches 生成出来的数组不应该就是递增的吗?为何还要在 domIndex 显式进行一次升序排序呢?
由于对象是 key-value 结构,无序的,无法完全保证在不同浏览器下,通过 for in 遍历出的顺序一致。所以,这里为了确保表现一致,显式地进行了一次升序排序。
接着通过在 applyPatch 中,调用 patchOp 给节点打上相应的 VPatch,也就是对 dom 进行操作,实现视图更新。结构较简单,这里就不多说了。部分代码如下:
// @vdom/patch-op.js
function applyPatch(vpatch, domNode, renderOptions) {
var type = vpatch.type
var vNode = vpatch.vNode
var patch = vpatch.patch
switch (type) {
case VPatch.REMOVE:
return removeNode(domNode, vNode)
case VPatch.INSERT:
return insertNode(domNode, patch, renderOptions)
...
}
}
7. reorder - 重新排序
不得不说,文章已经较长了,但抱歉还没结束。diff 阶段中有个当时被一笔带过的 reorder 方法。这里打算单独谈一谈。在 virtual-dom 的过程中,这个方法起到了很重要的作用。
reorder 会用在哪些场景呢?以 Vue 的语法,举几个栗子。
<!--
遍历对象
object 是个对象,结构如下
object = {
key1: value1
};
-->
<!-- case 1 -->
<ul>
<li v-for="(key, val) in object">
</li>
</ul>
<!-- case 2 -->
<ul>
<li v-for="value in object">
{{ $key }} : {{ value }}
</li>
</ul>
<!--
items 是个数组,结构如下
items = {
{
_uid: '...'
}...
}
-->
<!-- case 3 -->
<ul>
<li v-for="item in items"></li>
</ul>
<!-- case 4 -->
<ul>
<li v-for="item in items" track-by="_uid"></li>
</ul>
case 1、case 2 为遍历对象:之前谈过,对象由于是 key-value 结构,遍历顺序会有表现不确定性。所以这里内部需要调用 reorder 强制 key 按照第一次渲染的顺序进行排序,这样每次状态的更新,都能按照相对固定的顺序进行差异对比,性能最佳.
case 3、case 4 为遍历数组:这里又分了两种,区别在于是否用 track-by。问题来了,两种使用有啥区别呢,哪种更好。带着这个问题,我们开始对 reorder 的探索。
方法的最开始,进行了两个特殊逻辑判断。
// @vtree/diff.js
...
if (bFree.length === bChildren.length) {
return {
children: bChildren,
moves: null
}
}
...
if (aFree.length === aChildren.length) {
return {
children: bChildren,
moves: null
}
}
我们大多数时候不加 track-by 列表循环,在这里就直接 return 了。这时,是否会有疑惑,这样不就足够了吗,直接返回新的子节点,然后按次序和旧子节点进行对比,对结果也不会有影响。我们来看看下面这个栗子。
var oldItems = [
{
uid: '1',
value: 1
},
{
uid: '2',
value: 2
},
{
uid: '3',
value: 3
}
];
var newItems = [
{
uid: '3',
value: 3
},
{
uid: '1',
value: 1
},
{
uid: '2',
value: 2
}
];
不用 track-by 的场景下,在做 diff 时,会直接按照数组的顺序进行比较,结果是,所有节点都有状态更新,然后执行 3 条 dom 更新操作。这显示是没必要的,因为列表数据并没有发生改变,只是位置改变。(当然前提是,业务只关心数据,不关心顺序)由于 Js 的执行速度是比 dom 操作快很多。所以为了尽量减少 dom 操作,预先以 uid 为 key 将 newItems 按照 oldItems 的顺序进行排序,再做 diff ,则无需更新 dom 了。
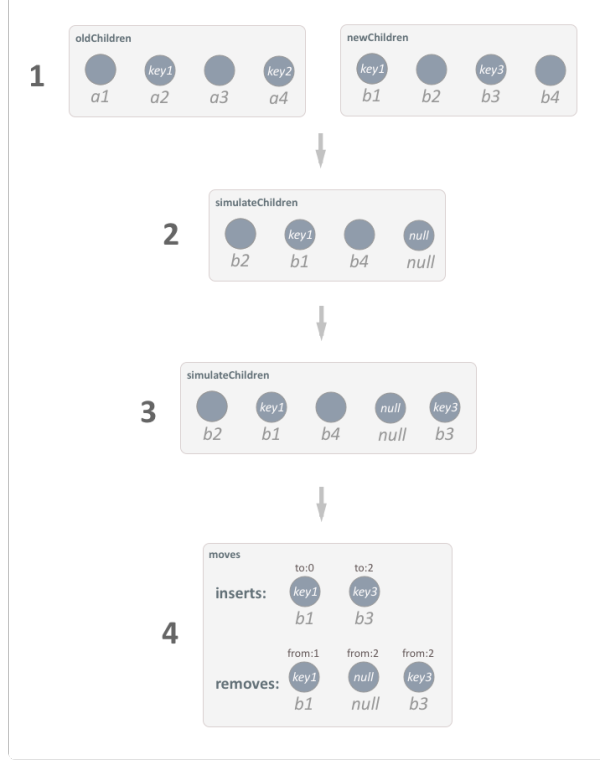
那么 reorder 是如何重新排序的呢?先上个图:
 首先要明确一点,在 reorder 阶段的排序,并没有真正将 newChildren 进行重新排序,而只是生成一个 insert 和 remove 操作记录数组,将在 patch 阶段时对 dom 节点进行操作。
首先要明确一点,在 reorder 阶段的排序,并没有真正将 newChildren 进行重新排序,而只是生成一个 insert 和 remove 操作记录数组,将在 patch 阶段时对 dom 节点进行操作。
为了辅助说明,这里将 reorder 的过程粗略分为四个阶段,分别称之为 「 准备阶段 」,「 key 类型顺序还原阶段 」,「 新增 key 添加阶段 」,「 新旧顺序转换阶段 」。
同时还定义了 「 key 类型 」这个概念,分为 3 种类型。
- 无 key 节点: 如 { VText('string') }
- key 节点:如 { h('div', { key: 'key1' }) }, { h('div', { key: 'key2' }) }
- null 节点:标识被删除的元素
1. 准备阶段
newChildren,oldChildren 为新旧子节点。这里设定的两个新旧子节点还是比较有典型性的。特点如下:
- 有新增 key 的节点
- 有删除 key 的节点
- 有相同 key 的节点
- 有无 key 节点
2. 相同 key 还原阶段
这个阶段的原则是,按照 oldChildren 子节点的 key 类型顺序,将 newChildren 还原回去。如旧子节点 key 顺序为
[无key, key1, 无key, key2]
还原步骤如下:
- oldChildren 第一个节点为无 key 节点,对应的 newChildren 中的第一个无 key 节点为 b2 。
- oldChildren 第二个节点为 key1 节点,newChildren 中的 key1 节点为 b1。
依次类推,得出 simulateChildren 数组为:
[b2, b1, b4, null]
为啥最后是个 null 呢,因为 oldChildren 中的 key2 在 newChildren 中并没有找到,表示被删除。
3. 新增 key 添加阶段
在上面阶段,只是完成了按照旧节点 key 类型顺序,将新节点进行了一个还原。但对于新节点中的新 key 类型节点并没有处理。这个阶段则是将新 key 类型的节点,插到 simulateChildren 结尾。
[b2, b1, b4, null, b3]
4. 新旧顺序转换阶段
这一步算法还是有点绕,建议直接看源码,一步步来观察转换的过程(其实就是我文字太弱,表达不清楚。 = =)。总结起来就是,如何将 simulateChildren的 key 类型顺序 转换成 newChildren 的 key 类型顺序的过程。
[无key, key1, 无key, null, key3] ==> [key1, 无key, key3, 无key]
最后会生成一个操作队列对象 moves。这里有个问题,为啥将 simulateChildren 变成 newChildren 的过程就是 oldChildren 变成 newChildren 的过程呢?
很显然了,因为通过 2,3 两步,已经将 simulateChildren 的 key 类型顺序和 oldChildren 做成一样了。
所以,是否适合用 track-by 要看具体的场景。如果子节点状态更新幅度很大,重复数据数据较少,如翻页,就不适合用 track-by ,省去 reorder 这一步直接做 diff。如果是较少数据会更新,如对于往固定列表中插入一行数据或者几行数据的变更等等,这时用 track-by 可以减少 dom 操作。
8. 结尾
好吧,差不多了。暂时能够聊的就这么多。(这次是真要结束了)
因理解深度,文字水平有限。有没说清楚的地方请各位看官多包涵,有误的地方,请留言指正。谢谢。
^_^
