

在这篇文章中,我们会介绍 Node.js API 的最佳实践,包括路由命名,身份验证,黑盒测试以及为这些资源使用合适的缓存 header 等主题。
Node.js 最受欢迎的用例之一就是用其开发 RESTful API。 但是,我们在使用 Trace, 我们的 Node.js 监控工具 帮助我们的用户在他们的应用中找到问题所在的过程中,我们不断地发现很多开发者在 REST API 上有许多的问题。
我希望这些我们在 RisingStack 使用的最佳实践可以帮到你:
#1 - 使用 HTTP 请求方法的 API 路由
想象你正在开发一个用来创建、更新、获取和删除用户的 Node.js RESTful API。对于这些操作,HTTP 已经有足够的工具集:POST, PUT, GET, PATCH 或 DELETE.
作为一个最佳实践,你的 API 路由应该使用名词来作为资源标识符。有关用户的资源,路由可以是这样的:
- POST /user 或者 PUT /user:/id 用来创建新用户。
- GET /user 查询用户列表。
- GET /user/:id 查询单个用户。
- PATCH /user/:id 修改已存在的用户记录。
- DELETE /user/:id 删除单个用户。
#2 - 正确地使用 HTTP 状态码
如果处理请求时发生了错误,你应该在响应中为此设置正确的状态码:
- 2xx, 一切正常。
- 3xx, 被请求的资源已被移走。
- 4xx, 因为客户端的错误导致请求无法处理(如请求一个不存在的资源)。
- 5xx,服务器在处理的过程中发生了错误(如意外情况发生)。
如果你用的框架是 Express,可以很容易通过
res.status(500).send({error: 'Internal server error happened'})
来设置状态码。用 Restify 也类似:
res.status(201)
访问 HTTP 状态码,查看完整的状态码列表。
#3 - 使用 HTTP 头字段来发送元数据
想附上关于你想发送的有效数据的元数据,那就加在 HTTP 头字段里吧。头字段可以含有这些信息:
- 分页
- 访问频次限制
- 或者身份认证
可以在这里找到标准的 HTTP 头字段列表。
如果你需要在头字段中设置任何自定义的元数据,最好使用“X”作为前缀。例如,如果您使用 CSRF 令牌,一般(虽然不是标准)会将其命名为 X-Csrf-Token。然而,根据 RFC 6648 ,它们被弃用了。新 API 应该尽可能地避免使用会和其他应用冲突的名称 例如,OpenStack 用 “OpenStack” 为其头标前缀:
OpenStack-Identity-Account-ID
OpenStack-Networking-Host-Name
OpenStack-Object-Storage-Policy
注意,HTTP 标准没有对头字段定义任何大小的限制;然而,Node.js (文章撰写时候的版本) 出于实际情况给头字段强加了 80 KB 的限制。
“不允许 HTTP 头字段(包括状态行)的总大小超过 HTTP_MAX_HEADER_SIZE 。这个检查是为了防止攻击者通过一个没有尽头的头字段来进行拒绝服务式攻击。”
#4 - 给你的 Node.js REST API 选择正确的框架
选择最适合你的使用场景的框架非常重要。
Express, Koa 还是 Hapi
Express, Koa 和 Hapi 可以被用来构建浏览器应用,正因如此,它们支持模板和渲染 - 这些只是它们一部分的功能而已。 如果你的应用也需要面向终端用户,接下来说的对你有意义。
Restify
Restify 致力于帮你建立 REST 服务。 它可以让你构建严格意义上的可维护的和可观察的 API 服务。 Restify 也附带了对所有处理程序的自动 DTrace 支持。
Restify 在生产环境中也被用于主要的应用上,比如 npm 和 Netflix。
#5 - 对你的 Node.js API 进行黑盒测试
测试你的 REST API 最好的方法之一就是黑盒测试。
黑盒测试是一种测试应用程序功能的方法,测试人员不用关心其内部结构或它如何工作的。 没有任何依赖会被 mock 或者 stub,整个系统会作为一个整体来进行测试。
supertest 可以帮助你进行黑盒测试。
如下代码实现了一个使用 mocha ,来检测是否返回了一个用户的测试用例:
const request = require('supertest')
describe('GET /user/:id', function() {
it('returns a user', function() {
// newer mocha versions accepts promises as well
return request(app)
.get('/user')
.set('Accept', 'application/json')
.expect(200, {
id: '1',
name: 'John Math'
}, done)
})
})
你可能会问:如何将数据填充到为 REST API 提供服务的数据库中?
通常,一种好的编写测试的方法是尽可能少地假设系统的状态。但是在某些场景下,你发现自己必须要知道系统的具体状态,这时你可以对其做一些断言从而达到更高的测试覆盖率。
根据你的需求,有如下方法可以让你把测试数据写进数据库:
- 在生产环境下已知数据的子集上进行黑盒测试
- 在测试之前,自行填充数据
当然,黑盒测试并不意味着你不需要单元测试,你仍然需要为你的 API 写单元测试
#6 - 使用基于 JWT 的无状态认证
由于你的 REST API 必须是无状态的,因此你的身份验证也是如此。为了处理这个,JWT (JSON Web Token) 是个不错的选择。
JWT 包含三个方面:
- 头,包含 token 的类型和散列算法
- 有效数据,包括声明
- 签名, (JWT 没有加密负载数据,只是签名)
往你的应用添加 JWT 验证非常简单:
const koa = require('koa')
const jwt = require('koa-jwt')
const app = koa()
app.use(jwt({
secret: 'very-secret'
}))
// Protected middleware
app.use(function *(){
// content of the token will be available on this.state.user
this.body = {
secret: '42'
}
})
然后,JWT 会保护你的 API 接口。要访问受保护的接口,你需要提供“授权”头字段中的 token 。
curl --header "Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ" my-website.com
值得注意的是,JWT 不依赖任何数据存储层。这是因为所有 JWT token 都可以自己验证,并且它们还可以包含生存时间。
此外,你必须确保所有 API 接口只能通过使用 HTTPS 的安全连接访问。
在前一篇文章中,我们详细解释了 Web 身份验证方法 - 我建议看看这篇文章
#7 - 使用条件请求
条件请求是根据特定 HTTP 头执行不同的 HTTP 请求。 你可以认为把这些头字段作为前提条件:如果它们被满足,请求将以不同的方式执行。
这些头字段试图检查存储在服务器上的资源的版本是否匹配相同资源的版本。 因为这个原因,这些头可以
- 最后一次修改的时间戳
- 或每个版本的标签
这些头字段是:
- Last-Modified (表示资源上次修改的时间),
- Etag (表示标签),
- If-Modified-Since(与 Last-Modified 标题一起使用),
- If-None-Match (与 Etag 标题一起使用),
来看一个例子吧!
如图所示的客户端没有任何以前的版本的 doc 资源,所以资源发送时头字段不会应用 if-Modified-Since 和 If-None-Match。 然后,服务器响应时会在头字段里正确地设置 Etag 和 Last-Modified。
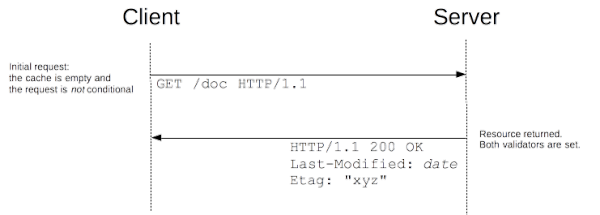
图片出自 MDN Conditional request documentation
客户端可以在尝试请求相同资源时设置 If-Modified-Since 和 If-None-Match 头字段,只要它现在有一个版本。 如果响应是相同的,服务器只是响应 304 - Not Modified 状态,并且不再发送资源。

图片出自 MDN Conditional request documentation
#8 - 拥抱访问频次限制
通过访问频次限制来控制对你的 API 的请求数量。
为了告诉你的 API 有多少用户请求离开,你需要在头字段中包含这些:
- X-Rate-Limit-Limit,在给定时间间隔内允许的请求数
- X-Rate-Limit-Remaining,在同一间隔内剩余的请求数,
- X-Rate-Limit-Reset,当速率限制时将被重置的时间。
大部分 HTTP 框架开箱(或者结合插件)就有这个功能。比如,Koa,它有一个模块 koa-ratelimit 可以做到这个事。
注意,时间窗口可以根据不同的 API 提供方而变化 - 例如,GitHub 使用一个小时,而 Twitter 是15分钟.
#9 - 创建正确的 API 文档
你开发的 API 是为了其他人可以使用它们,并从中受益。提供一份你的 Node.js REST API 文档是非常关键的。
这几个开源项目可能会帮助你建立你的 API 文档:
或者,如果你想使用第三方文档服务商,试试 Apiary。
#10 - 别错过 API 的未来
在过去的几年间,出现了两种主要的 API 查询语言 - Facebook 的 GraphQL 和 Netflix 的 Falcor。我们为什么需要他们?
想象下面的 RESTful 资源请求:
/org/1/space/2/docs/1/collaborators?include=email&page=1&limit=10
这很容易让你的 API 失控 - 因为你只是想在任何时候对你所有的模块中得到同样的响应格式。GraphQL 和 Falcor 都可以帮你解决这个问题。
关于 GraphQL关于 FalcorGraphQL 是一种用于 API 的查询语言,能在运行的时候使用现有数据完成这些查询。 GraphQL 为您的 API 的数据提供了一个完整和可理解的描述,使客户能够准确地询问他们需要什么,不需要什么,使得随着时间的推移更容易演化 API,并支持强大的开发工具。 - 阅读更多点击这里
Falcor 是支持 Netflix UI 的创新数据平台。 Falcor 允许您将所有后端数据建模为节点服务器上的单个虚拟 JSON 对象。 在客户端上,使用熟悉的 JavaScript 操作(如 get,set 和 call )处理远程 JSON 对象。 如果你知道你的数据,你就知道你的 API。 - 阅读更多点击这里
非常不错的 REST API 以供参考
如果你即将开始开发 Node.js REST API 或在旧版本基础上的开发新版本, 我们收集了四个值得你看看的实例:
我希望现在你能更好地理解如何使用 Node.js 编写 API。 有什么问题就在评论里提吧!
