

一、概述
在上一篇文章中对一些CSS问题进行回答,发现很多都是知其然不知其所以然,而写文章的目的就是改变知其然不知其所以然的状态(因为这样的简历,人家不要我),而阅读了tali garsiel的一篇关于浏览器工作原理的中文版,觉得文章不是很适合XX阅读,读起来比较生涩,所以花了差不多XX小时整理了这篇文章。
参考文章: 浏览器的工作原理:新式网络浏览器幕后揭秘
作者注:
英文原文:howbrowserswork
浏览器工作流程
- 通过网络引擎获取到文档;
- 开始解析文档,在遇到脚本时立即执行脚本,文档停止解析,如果是外部脚本则等待资源加载并执行完成,外部脚本可通过加defer或者async告诉浏览器异步处理,这样不会打断解析;
- 布局,为每个节点分配一个应出现在屏幕上的确切坐标;
- 绘制,呈现引擎会遍历呈现树,由用户界面后端层将每个节点绘制出来;
- 显示,值得注意的是这一步并不会等到文档解析完成,会将部分已解析的文档尽快显示。
作者注:很多现代浏览器都有进行预解析优化,即主解析器解析DOM树,使用其他线程解析外部资源的引用。
作者注:为什么会停止解析?因为脚本在文档解析阶段会请求样式信息。如果当时还没有加载和解析样式,脚本就会获得错误的回复,这样显然会产生很多问题。
呈现引擎工作流程
呈现引擎从网络层获取文档数据,拥有数据后的呈现引擎开始解析HTML文档,并将各标记逐个转化为内容树上的DOM节点。同时也会解析外部CSS 文件以及样式元素中的样式数据,HTML 中这些带有视觉指令的样式信息将用于创建另一个树结构将创建另一个树结构:呈现树。
呈现树构建完毕之后,进入“布局”处理阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标。下一个阶段是绘制- 呈现引擎会遍历呈现树,由用户界面后端层将每个节点绘制出来。
二、解析
在呈现引擎中解析是非常重要的环节。解析文档即是将文档转化为有意义的结构,解析后得到的结果通常代表了文档结构的节点树,被称作解析树或语法树。
而解析的过程一般为词法分析和语法分析,词法分析即是大量的标记过程,词法分析器根据特定的字典(语言的词汇)对输入内容进行标记;语法分析即是应用语言语法的过程。不同语言拥有不同的解析器,在这里不做多的赘述,如果想了解更多,那就去了解吧。
在浏览器中,有HTML解析器,CSS解析器,JavaScript解析器等。
HTML解析
HTML解析器输出的解析树是由DOM元素和属性节点构成的树结构(内容树或DOM树)。
具体解析算法:标记化和树构建,分别有标记生成器和树构建器完成
作者注:在这里提到的”标记”即为我们常说的标签
标记化算法:输入HTML内容,输出HTML标记
在查看具体算法之前,我们需要先了解一些基础的东西,便于对算法的理解。一个HTML元素包括其起始标记,结束标记,属性名称和属性值,以及内容。标记化通过状态机来表示,每一个状态接收输入的一个或多个字符,并根据这些字符更新状态。
具体算法如下:
初始状态:数据状态
遇到” < ”:标记打开状态
遇到字符:标记名称状态(上一状态为标记打开状态) // 这里原文说的是a-z
遇到“/ “:创建end tag token(上一状态为标记打开状态)
遇到字符:发送字符标记(上一状态为数据状态)
遇到” > ”:发送当前标记,修改状态为数据状态(上一状态为标记打开状态)树构建算法
在解析器标记化时,也会进行树构建。DOM树以Document为根节点,通过树构建器接收标记生成器发送的标记,并根据规范匹配并创建对应的DOM元素,创建的元素将被添加到DOM树以及开放的堆栈中。
原文注:此堆栈用于纠正嵌套错误和处理未关闭的标记
树构建的流程好像搞得半懂不懂的,有机会研究下源码,再记录吧。这里先大概记录下现在的理解吧。首先树构建器接收到标记,会根据状态判断以及容错规则判断处理方式,重复该操作。
-
状态处理规则:InitialMode,BeforeHTMLMode, BeforeHeadMode, InHeadMode, AfterHeadMode, InBodyMode,InTableMode, InCapationMode, InColumnGroupMode等,在这些状态时会根据接收到的标记进行判断,不符合规范则系统隐式创建符合规范的元素,附加到DOM树,并重新处理接收到的标记。
-
容错处理规则:
以下片段原文使用的引用,引用自W3C规范
1.明显不能在某些外部标记中添加的元素。在此情况下,我们应该关闭所有标记,直到出现禁止添加的元素,然后再加入该元素。
2.我们不能直接添加的元素。这很可能是网页作者忘记添加了其中的一些标记(或者其中的标记是可选的)。这些标签可能包括:HTML HEAD BODY TBODY TR TD LI(还有遗漏的吗?)。
3.向inline 元素内添加 block 元素。关闭所有inline 元素,直到出现下一个较高级的 block 元素。如果这样仍然无效,可关闭所有元素,直到可以添加元素为止,或者忽略该标记。
CSS解析
CSS解析和HTML不同,HTML由于要求处理较为“宽容“,允许省略某些隐式添加的标记,有时还能省略一些起始或者结束标记等等,他的语法不是与上下文无关的语法,以至于HTML 并不能很容易地用解析器所需的与上下文无关的语法来定义。而CSSCSS 是上下文无关的语法,可以使用常规解析器进行解析,浏览器的CSS解析器根据规范生成,如WebKit使用Flex和Bison解析器生成器,通过
CSS 语法文件自动创建解析器。向解析器输入css样式,解析器则输出相应的解析树。
三、呈现树构建
呈现树构建时间在文章中呈现引擎工作流程已介绍,它的作用就是按照正确的顺序绘制内容。Firefox 将呈现树中的元素称为“框架”。WebKit 使用的术语是呈现器或呈现对象。在原文中作者使用“呈现器”进行接下来的介绍,为了方便理解我们强制记住以下使用的“呈现器”即表示呈现树种的元素。
呈现树的构建基于DOM元素和CSS规则,而呈现树则是布局和绘制的基础,呈现树通过构建与DOM节点的呈现器以及计算相关节点的CSS规则构建。
呈现器构建规则:
呈现构造器根据css中定义的“display”属性以及元素类型创建不同的呈现器类型,每个呈现器都代表一个矩形框,可通常对应于相关节点的css框,包含了宽度,高度,位置等几何信息。这里根据不同元素主要是一些特殊元素,如表单,表格等,这些呈现器包含一些除了几何信息外的信息。
作者注:本来还以为呈现器的矩形框即是我们常说的盒子呢,后来才知道CSS框模型是布局后的矩形框。所以我好像猜对了。
样式计算:
在构建呈现树时,需要通过计算每个元素的样式属性来计算每个呈现器的可视化属性。其中样式来源包括浏览器的默认样式表、由网页提供的样式表以及由用户提供给浏览器的用户样式表。
当然计算样式有很多难点,比如数据复杂的结构,这里就不列出来了,有需求的可以阅读原文,这里只简单介绍浏览器如何计算。
样式的计算会用CSS解析器的解析结果,系统根据以样式规则最右边的选择器为键(这也解释了为什么CSS是从右向左匹配)将CSS规则(整体)添加到不同的选择器哈希表,如ID表,类表等。计算是只要从哈希表中提取元素相关的规则即可(这可以不考虑与元素无关的规则,从而减少计算)。剩下的工作就是从提取的规则中判断真正匹配元素的规则。
作者注:这里所说的CSS规则就是我们开发者写的CSS规则,如下即是一条规则
#my-container { color: #fff; background: #fff; }
样式表层叠顺序:
样式层叠顺序规则:浏览器申明<用户普通声明<作者普通声明<作者重要声明<用户重要声明。作者即开发者,用户即浏览器使用者。
特异性规则:按a-b-c-d顺序。a表示是否为style属性,是则为1,否则为0;b表示选择器ID的个数;c表示选择器中类,伪类,以及其他元素的个数;d表示元素名称和伪元素的个数。如form#form1 input[type=number] + label.input-label:before {…} 可表示为a=0 b=1 c=2 d=4
这也就导出了为什么属性可通过标记1000这样的权重计算规则。当然浏览器内部具体如何实现计算,还是不知道,对于普通开发者也没必要知道,这也足够解决开发问题了。
作者注: 可以看关于别人前端面试的问题的回答(CSS篇)中的关于CSS权重计算的问题
DOM树与呈现树的联系与区别
呈现器与DOM元素是相对应,但并非一一对应的。非可视化的元素不会插入呈现树,如HRAD,display属性为“none”的元素。而像“select”这样的复杂结构元素,则需要多个呈现器。
呈现树构建流程:
在Firefox中,呈现引擎(原文用的”系统”)通过注册展示层作为侦听器。通过展示层委托给FrameConstructor来解析样式并创建呈现器。在WebKit中,把解析样式和创建呈现器的过程称为”附加”(原文使用了“附加(Attachment)”,个人觉得该词不翻译更好)。附加是同步进行的,通过调用新节点的“attach”方法把节点插入DOM树,而调用节点的”attach”方法会根据创建呈现器规则判断是否需要创建呈现器,需要则创建呈现器。
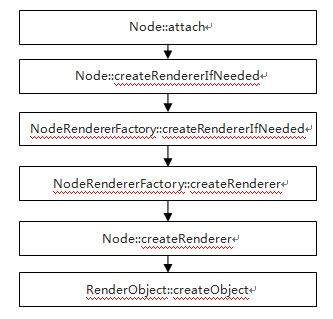
作者注: 图片原文地址
四、布局
呈现器在创建完成并添加都呈现树时并不包含位置和大小信息,把计算这些值得过程成为布局或重排。HTML采用基于流的布局模型,意味着大多数情况下只要一次遍历就能计算出几何信息(位置,大小),处于流中靠后位置的元素通常不会影响靠前位置元素的几何特征。
布局是一个递归的过程,从根呈现器(HTML元素)开始(0,0位置,浏览器左边),递归遍历部分或全部呈现器,并通过调用需要布局的子呈现器的”layout”或“reflow”方法计算子呈现器的几何信息(父元素被子元素撑开)。
而为了避免对所有细微的改动都进行整体布局(重绘),浏览器采用了一种”dirty”系统,对发生改变的呈现器,浏览器将其标记为“dirty”,表示需要重新布局。有两种标记“dirty”和“children are dirty”。“children are dirty”表示尽管呈现器自身没有改变,但是它至少一个子代需要重新布局(那么这种情况到底是只布局子代还是会布局这个呈现器本身和其子代呢?)。
当所有呈现器的全局样式(如字体大小更改)或者屏幕大小发生改变时会触发全局布局,当部分呈现器发送改变(标记为“dirty”)时会触发增量布局,如脚本操作DOM。
增量布局是异步执行的,Firefox使用队列,由调度程序触发布局,而WebKit使用定时器对呈现树进行遍历,对标记为“dirty”的呈现器进行布局。全局布局往往是同步的。
布局过程:
-
父呈现器确定自己高度
-
父呈现器处理子呈现器,为其设置坐标,在子呈现器为“dirty”或全局布局时,为子呈现器计算高度
-
父呈现器根据子呈现器高度以及边框,边距,补白等信息累加设置自身高度(递归的过程)。
-
将“dirty”标记改为false
如果在布局过程中,呈现器需要换行,则会停止布局,并告知父呈现器需要换行,父呈现器则会创建额外的呈现器,并进行布局。
五、绘制
系统遍历呈现树,并调用呈现器的“paint”方法,将呈现器的内容显示在屏幕上的过程称为绘制。
跟布局一样,绘制也分为全局绘制和增量绘制。在增量绘制中,部分呈现器发生了更改,但是不会影响整个树。更改后的呈现器将其在屏幕上对应的矩形区域设为无效,这导致OS 将其视为一块“dirty 区域”,并生成“paint”事件。
原文在这里对Firefox和chrome进行了介绍
在介绍绘制顺序前,先介绍下CSS的分层展示。分层有CSS的z-index属性指定,它代表了框的第三维度,也就是沿“z轴”方向的位置。这些框分散在多个堆栈(称为堆栈上下文),在每个堆栈中,会首先绘制后面的元素,然后再顶部绘制前面的元素,以便更靠近用户,对于重叠的元素,则最后绘制的在最前面。具有z-index属性的框形成了本地堆栈,视口具有外部堆栈(所以如果“dirty”会触发增量绘制?)。
接着介绍绘制顺序,绘制的顺序就是元素进入堆栈的顺序,这些堆栈会从后向前绘制,因此这样的顺序会影响绘制。而块呈现器的堆栈顺序为:背景色,背景图片,边框,子代,轮廓。
六、其他
呈现引擎线程
呈现引擎采用单线程,除网络操作外的所有操作都在单线程中进行。除chrome浏览器该线程为标签页线程,其他浏览器都使用浏览器主线程。网络操作可由多个并行线程执行。
事件循环
浏览器的主线程是事件循环,是一个无限循环,永远等待时间发生,并进行处理。
七、正文结束
虽然原文总的来说看了两遍,但是觉得还是很多地方似懂非懂,希望有机会查看一次他的源代码吧,不仅仅是弄清楚浏览器如何运行,更是希望能够重中学到其他工程师如何处理结构如此复杂的数据。
最后附上原文的两张主流程图
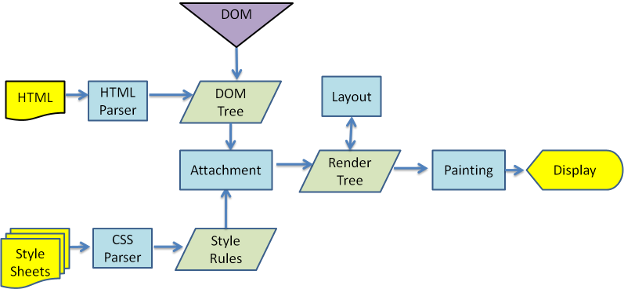
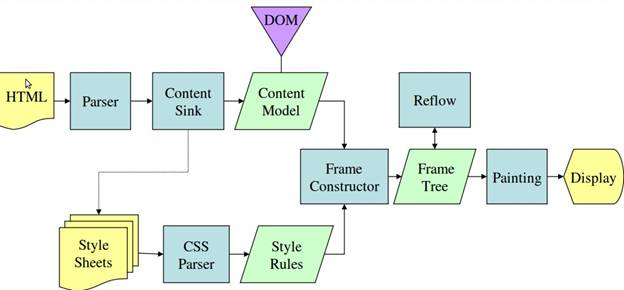
写在最后
时间成本:约12小时
价值几何:看官来说
欢迎关注微信号: 成长之路。提出你的问题,交给我来回答。一起踏上成长之路,在文章评论中留言你的问题也有机会被选中哦。
如果你发现文中有错误的地方,请指出,我将及时修改。
整理的不好,非常有幸被你看到,请指点。
