

理解Python网络编程
最近在学习Python网络编程时看了一些相关的文章,发现大多数要么讲的晦涩难懂,要么讲的比较浅显,我就想为什么不在学习的过程中写一篇心得呢,于是有了这篇文章。我相信技术不全是冰冷的,从人的角度出发,才能更好地领悟编程的乐趣,本文将尝试以简洁的文字分享如何理解Python中的网络编程。
在Python世界里,喜欢用Python做爬虫的人不在少数,那么在请求页面的过程中发生了什么呢?
现在编写一个最简单的Client/Server程序:
-
首先执行下面的命令开启一个监听8000端口的HTTP服务器:
python3 -m http.server 8000 Serving HTTP on 0.0.0.0 port 8000 ... -
接着编写一个程序,来对这个服务器发起HTTP请求:
import requests r = requests.get('http://127.0.0.1:8000/') print(r) -
再执行这个程序:
bash-3.2$ python test.py <Response [200]>
可以看到,服务器返回了一个200成功响应。
好,现在我们来总结请求过程:
- 客户端向服务器端发起了一个HTTP(GET)请求。
- 服务器端向客户端返回了一个HTTP(200)响应。
这是我们能看到的最抽象的过程,下面再用tcpdump细看发生了什么:
在命令行用tcpdump来监听本地网卡的tcp连接,
tcpdump -i lo0 port 8000或者你也可以用-w参数把信息写出到文件,再通过wireshark来观察结果:
tcpdump -i lo0 port 8000 -w test.cap现在执行程序:
bash-3.2$ python test.py
<Response [200]>不出意外的话,我们就能观察到tcpdump输出类似如下的结果:
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo0, link-type NULL (BSD loopback), capture size 262144 bytes
23:46:06.464962 IP localhost.49329 > localhost.irdmi: Flags [S], seq 1191154495, win 65535, options [mss 16344,nop,wscale 5,nop,nop,TS val 178410641 ecr 0,sackOK,eol], length 0
23:46:06.465018 IP localhost.irdmi > localhost.49329: Flags [S.], seq 1405387906, ack 1191154496, win 65535, options [mss 16344,nop,wscale 5,nop,nop,TS val 178410641 ecr 178410641,sackOK,eol], length 0
23:46:06.465029 IP localhost.49329 > localhost.irdmi: Flags [.], ack 1, win 12759, options [nop,nop,TS val 178410641 ecr 178410641], length 0
23:46:06.465039 IP localhost.irdmi > localhost.49329: Flags [.], ack 1, win 12759, options [nop,nop,TS val 178410641 ecr 178410641], length 0
23:46:06.465065 IP localhost.49329 > localhost.irdmi: Flags [P.], seq 1:146, ack 1, win 12759, options [nop,nop,TS val 178410641 ecr 178410641], length 145
23:46:06.465079 IP localhost.irdmi > localhost.49329: Flags [.], ack 146, win 12754, options [nop,nop,TS val 178410641 ecr 178410641], length 0
23:46:06.467141 IP localhost.irdmi > localhost.49329: Flags [P.], seq 1:156, ack 146, win 12754, options [nop,nop,TS val 178410642 ecr 178410641], length 155
23:46:06.467171 IP localhost.49329 > localhost.irdmi: Flags [.], ack 156, win 12754, options [nop,nop,TS val 178410643 ecr 178410642], length 0
23:46:06.467231 IP localhost.irdmi > localhost.49329: Flags [P.], seq 156:5324, ack 146, win 12754, options [nop,nop,TS val 178410643 ecr 178410643], length 5168
23:46:06.467245 IP localhost.49329 > localhost.irdmi: Flags [.], ack 5324, win 12593, options [nop,nop,TS val 178410643 ecr 178410643], length 0
23:46:06.467313 IP localhost.irdmi > localhost.49329: Flags [F.], seq 5324, ack 146, win 12754, options [nop,nop,TS val 178410643 ecr 178410643], length 0
23:46:06.467331 IP localhost.49329 > localhost.irdmi: Flags [.], ack 5325, win 12593, options [nop,nop,TS val 178410643 ecr 178410643], length 0
23:46:06.468442 IP localhost.49329 > localhost.irdmi: Flags [F.], seq 146, ack 5325, win 12593, options [nop,nop,TS val 178410644 ecr 178410643], length 0
23:46:06.468479 IP localhost.irdmi > localhost.49329: Flags [.], ack 147, win 12754, options [nop,nop,TS val 178410644 ecr 178410644], length 0通过结果能看到:
- 客户端发起一个SYN报文,向服务器请求建立一个TCP连接。
- 服务器端返回一个SYN+ACK报文,表示服务器收到了客户端传来的请求,并同意与客户端建立TCP连接。
- 客户端返回一个ACK报文,表示已经知道服务器同意建立TCP连接,这时候双方开始通信。
- 客户端和服务器端不断地交换信息,接收报文,返回应答。
- 最后数据传输完毕,服务器发起一个FIN报文,表示要结束通信,客户端返回一个ACK应答,接着又发送一个FIN报文,最后服务器端返回一个ACK应答,此时连接过程结束。
仔细一想,这个过程跟现实世界中的“打电话”是非常相似的,与之代替的不就是拨打电话、建立连接、确认应答、交换信息、关闭连接吗,我们经常说TCP是面向连接的也是这个道理。
现在再来看服务器端的状态,通过lsof命令来查看绑定8000端口的描述符信息:
lsof -n -i:8000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python3.4 1128 tonnie 4u IPv4 0x17036ae156ec58cf 0t0 TCP *:irdmi (LISTEN)通过结果可以观察到服务器的进程的一些信息,服务器进程处于LISTEN阶段,说明服务器处于保持着监听连接的状态:
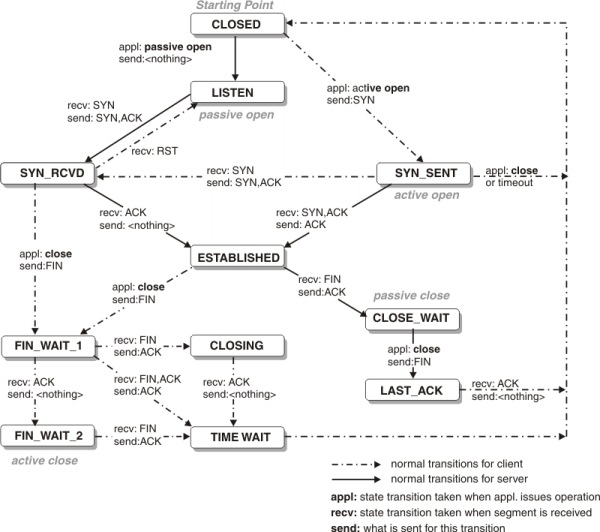
现在用刚才的例子来解释TCP中状态迁移的概念,这时候,如果从客户端到来一个请求:
- 服务器端接收到客户端的SYN报文,返回SYN+ACK报文,服务器端进入SYN_RCVD状态。
- 服务器端收到客户端返回的ACK应答后,连接建立,进入ESTABLISHED状态。
- 服务器端的数据传输完毕,给客户端发送FIN报文,进入FIN_WAIT_1状态。
- 服务器端接收到客户端返回的ACK应答后,进入FIN_WAIT_2状态。
- 服务器端接收到客户端的FIN报文,接着返回一个ACK应答,等待连接关闭,进入TIME_WAIT状态。
- 服务器端经过2MSL时间后进入CLOSED状态,此时连接关闭。
至于客户端,在每个阶段也有各自的状态,下图表示了TCP状态迁移的过程:
下面来看TCP/IP的四层模型:
- 应用层,在这一层上的有HTTP、DNS、FTP、SSH等。
- 传输层,在这一层上的有TCP、UDP等。
- 网络层,在这一层上的有IP、ARP等。
- 网络接口层,在这一层上的有以太网、PPP等。
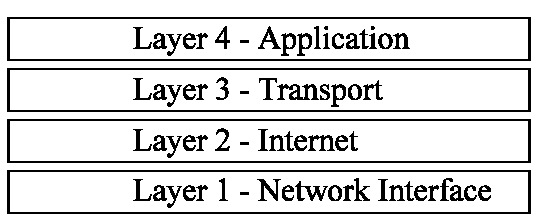
在上面的程序中,客户端与服务器端的通信都要经过这四个层来打交道。那么这段Python程序是如何操作连接的建立和关闭以及数据的传输呢?答案是通过socket提供的一系列方法。
socket是一种IPC方法,它使得同一主机或不同主机的应用程序能交换数据,socket在上图中处于第三层和第四层之间,所以可以把socket理解为在传输层和应用层之间的一组通信接口,或者是一个抽象的通信设备,应用程序借助socket就能方便地与其他应用程序进行交流。
现在把客户端的代码简化为用socket表现的最简形式:
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(('127.0.0.1', 8000))
sock.send(b'GET / HTTP/1.1\r\nHost: 127.0.0.1:8000\r\n\r\n')
data = sock.recv(4096)
print(data)
sock.close()是不是感觉跟上面TCP的连接过程十分相似?只是用代码的方式把这一具现过程给抽象表现出来罢了。
再看服务器端的最简化代码:
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(('127.0.0.1', 8000))
sock.listen(5)
while 1:
cli_sock, cli_addr = sock.accept()
req = cli_sock.recv(4096)
cli_sock.send(b'hello world')
cli_sock.close()过程同样很简单,总结一下它们的过程:
服务器端:
- 调用socket.socket建立一个socket对象,指定域(domain)和协议(protocol),此时一个文件描述符会绑定到这个socket对象。
- 调用sock.setsockopt设置这个socket选项,本例中把socket.SO_REUSEADDR设置为1,表示服务器端进程终止后,操作系统会为它绑定的端口保留一段时间,以防其他进程在它结束后抢占这个端口。
- 调用sock.bind为这个socket对象绑定到一个地址上,它需要一个主机地址和端口组成的元组作为参数。
- 调用sock.listen通知系统开始侦听来自客户端的连接,参数是在队列中最大的未决连接数量。
- 调用sock.accept阻塞调用直至返回一个元组,里面包含了用于与客户端进行对话的socket对象以及客户端的地址信息。
- 调用cli_sock.recv方法接受来自客户端发来的数据,在这个例子中拿到的是b'GET / HTTP/1.1\r\nHost: 127.0.0.1:8000\r\n\r\n'。
- 调用cli_sock.send方法把数据发送给客户端。
- 调用cli_sock.close结束连接。
客户端:
- 调用socket.socket建立一个socket对象,指定域(domain)和协议(protocol),此时一个文件描述符会绑定到这个socket对象。
- 调用sock.connect通过指定的主机和端口连接到对端的服务器进程。
- 调用sock.send给服务器端发送数据。
- 调用sock.recv接收服务器端发来的数据。
- 调用sock.close关闭连接。
socket的数据是通过内核维护的读写缓冲区来获取的,如下图中的表示:
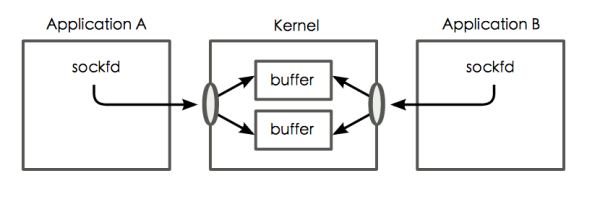
每次从缓冲区写入或读入数据都会发起标准的系统调用,如:
int read(fd, buf, bufsize);
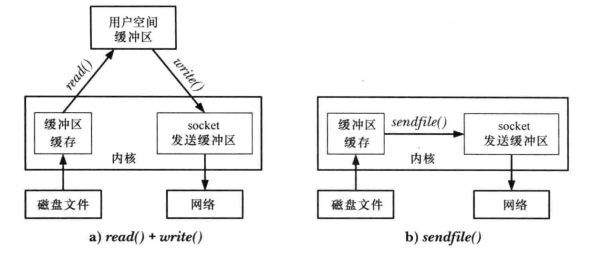
int write(fd, buf, bufwrite);来进行数据的写或读。当然对于大文件来说,执行多次read、write等系统调用的耗费是相当可观的,这时候就要用到sendfile系统调用:
socket的域
在上面的程序中我们建立socket对象都是使用了AF_INET这个参数,它表示这个socket是通过IPV4的方式进行通信的。
这种socket也被叫做Internet Domain Socket,它定义的地址形式是这样的:
struct in_addr {
in_addr_t s_addr; //32位无符号整数。
};
struct sockaddr_in {
sa_family_t sin_family; //AF_INET
in_port_t sin_port; //端口号
struct in_addr sin_addr; //ipv4地址
unsigned char __pad[X];
};与之相对的,还有一种socket类型为Unix Domain Socket,它通过AF_UNIX这个参数来创建。它定义的地址形式是这样的:
struct sockaddr_un {
sa_family_t sun_family; //AF_UNIX
char sun_path[108]; //socket路径名
};当用Unix Domain Socket发起bind操作时,会在文件系统中创建一个条目,socket和路径名为一对一关系。一般来说,Unix Domain Socket只针对在同一主机下应用程序下的网络通信,它还有一个特点是可以使用目录权限来控制socket的访问。(例如我们使用mysql时用到的mysql.sock就是使用unix domain sokcet的载体)
socket的协议
在protocol上我们使用了SOCK_STREAM,表示这是个流式套接字(即TCP),除此之外我们还可以把它指定为SOCK_DGRAM,表示这是个数据报套接字(即UDP)。
TCP跟UDP的一些基本区别:
- TCP面向连接,UDP不面向连接。
- TCP面向字节,不存在消息边界,可能存在粘包问题。UDP则面向报文。
- TCP会尽力保证数据的可靠交付,而UDP默认不做保证。
- TCP头部20字节,UDP头部8字节。
socket的通道
一般来说,socket的信道是双向的,即一个socket既能读又能写。有时候你需要建立一个半开放的socket,这时候就要使用socket的shutdown调用,它接收一个标记,其中:
- SHUT_RD代表关闭连接的读端。
- SHUT_WR代表关闭连接的写端。
- SHUT_RDWR代表关闭连接的读端跟写端。
shutdown()不会显式关闭文件描述符,需要另外调用close()。
现在你应该对socket有一个大致的了解了,现在我们再来探讨一个socket服务器是怎么编写的。
再回到最开始的那段代码:
python3 -m http.server 8000
Serving HTTP on 0.0.0.0 port 8000 ...我们直接用python内置的HTTPServer绑定了8000这个端口上。
查看python3的http.server所在的源码:
def test(HandlerClass=BaseHTTPRequestHandler,
ServerClass=HTTPServer, protocol="HTTP/1.0", port=8000, bind=""):
server_address = (bind, port)
HandlerClass.protocol_version = protocol
httpd = ServerClass(server_address, HandlerClass)
sa = httpd.socket.getsockname()
print("Serving HTTP on", sa[0], "port", sa[1], "...")
try:
httpd.serve_forever()
except KeyboardInterrupt:
print("\nKeyboard interrupt received, exiting.")
httpd.server_close()
sys.exit(0)当http.server以模块方式运行时会调用test方法,创建一个测试服务器,这个服务器默认使用了HTTPServer作为服务器的类,BaseHTTPRequestHandler作为请求的处理类。
看HTTPServer,也就是我们一开始使用的服务器:
class HTTPServer(socketserver.TCPServer):
allow_reuse_address = 1
def server_bind(self):
socketserver.TCPServer.server_bind(self)
host, port = self.socket.getsockname()[:2]
self.server_name = socket.getfqdn(host)
self.server_port = port它继承了socketserver.TCPServer这个类,找到socketserver所在的源码,发现有一段注释,说明了几个服务器类之间的关系。
+------------+
| BaseServer |
+------------+
|
v
+-----------+ +------------------+
| TCPServer |------->| UnixStreamServer |
+-----------+ +------------------+
|
v
+-----------+ +--------------------+
| UDPServer |------->| UnixDatagramServer |
+-----------+ +--------------------+可以看到,TCPServer继承自BaseServer,而UDPServer又继承自TCPServer。
找到TCPServer这个类,可以看到它默认使用socket.AF_INET(IPV4)和socket.SOCK_STREAM(TCP)协议,并会在初始化的时候建立一个socket对象,注意这时候这个socket对象仅仅只是被创建处理,它还没有做任何的绑定。
class TCPServer(BaseServer):
address_family = socket.AF_INET
socket_type = socket.SOCK_STREAM
request_queue_size = 5
allow_reuse_address = False
def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True):
BaseServer.__init__(self, server_address, RequestHandlerClass)
self.socket = socket.socket(self.address_family,
self.socket_type)
if bind_and_activate:
try:
self.server_bind()
self.server_activate()
except:
self.server_close()
raise真正的绑定操作发生在self.server_bind()这行代码里,现在我们查看这个方法,它把socket对象绑定到__init__初始化中得到的地址上,并获取服务端的地址:
def server_bind(self):
if self.allow_reuse_address:
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.socket.bind(self.server_address)
self.server_address = self.socket.getsockname()绑定后的监听动作则发生在self.server_activate()这行里,它紧跟着binding后进行,在这个方法里socket会在绑定的地址上监听到来的连接。
def server_activate(self):
self.socket.listen(self.request_queue_size)现在我们关心的是,如果现在有一个客户端发起了连接请求,服务器类会怎么处理呢?我们可以在TCPServer继承的BaseServer找到答案。
找到BaseServer的serve_forever方法:
def serve_forever(self, poll_interval=0.5):
self.__is_shut_down.clear()
try:
while not self.__shutdown_request:
r, w, e = _eintr_retry(select.select, [self], [], [],
poll_interval)
if self in r:
self._handle_request_noblock()
self.service_actions()
finally:
self.__shutdown_request = False
self.__is_shut_down.set()当服务器没被shutdown时,就会在while循环中用select去轮询活跃的socket,返回活跃的文件描述符,当检测到当前有可读事件时,就会调用_handle_request_noblock方法来处理socket:
def get_request(self):
return self.socket.accept()
def _handle_request_noblock(self):
try:
request, client_address = self.get_request()
except OSError:
return
if self.verify_request(request, client_address):
try:
self.process_request(request, client_address)
except:
self.handle_error(request, client_address)
self.shutdown_request(request)在_handle_request_noblock方法中,服务器拿到可读的socket(request),调用process_request方法来处理请求,当发生异常时调用handle_error处理错误,接着调用shutdown_request关闭请求。
def process_request(self, request, client_address):
self.finish_request(request, client_address)
self.shutdown_request(request)
def finish_request(self, request, client_address):
self.RequestHandlerClass(request, client_address, self)
def shutdown_request(self, request):
self.close_request(request)最后来看process_request方法做了什么事情,首先它调用finish_request方法,实例化出一个RequestHandlerClass(请求处理类)来处理本次请求,处理完成后调用shutdown_request方法来结束请求。
看看UDPServer,几乎是换汤不换药,只修改了TCPServer的几个重要的参数:
class UDPServer(TCPServer):
allow_reuse_address = False
socket_type = socket.SOCK_DGRAM
max_packet_size = 8192
def get_request(self):
data, client_addr = self.socket.recvfrom(self.max_packet_size)
return (data, self.socket), client_addr服务器类差不多就这样了,再来看RequestHandler。
先看最原始的BaseRequestHandler类:
class BaseRequestHandler:
def __init__(self, request, client_address, server):
self.request = request
self.client_address = client_address
self.server = server
self.setup()
try:
self.handle()
finally:
self.finish()它接收一个请求(socket)作为参数,调用self.setup()建立用于读写的文件描述符,接着调用self.handle()来处理这次请求,最终调用self.finish()结束处理。
现在看StreamRequestHandler类:
class StreamRequestHandler(BaseRequestHandler):
rbufsize = -1
wbufsize = 0
timeout = None
disable_nagle_algorithm = False
def setup(self):
self.connection = self.request
if self.timeout is not None:
self.connection.settimeout(self.timeout)
if self.disable_nagle_algorithm:
self.connection.setsockopt(socket.IPPROTO_TCP,
socket.TCP_NODELAY, True)
self.rfile = self.connection.makefile('rb', self.rbufsize)
self.wfile = self.connection.makefile('wb', self.wbufsize)
def finish(self):
if not self.wfile.closed:
try:
self.wfile.flush()
except socket.error:
pass
self.wfile.close()
self.rfile.close()在setup过程为socket建立了一个用于读的文件描述符以及一个用于写的文件描述符,在finish的过程中会把写缓冲区刷新,关闭读写两个文件描述符。
从上面得知handle是处理请求的核心过程,在BaseHTTPRequestHandler中是这样实现的,handler会处理一个socket请求,如果该请求是断续请求而且没有超时或异常的话,就会继续处理下一个请求(例如keep-alive、大数据传输):
class BaseHTTPRequestHandler(socketserver.StreamRequestHandler):
def handle(self):
self.handle_one_request()
while not self.close_connection:
self.handle_one_request()其他部分太琐碎就不贴了,完成这一步后,服务器端就完成了一个来自客户端的请求的处理。
有的人还是可能觉得BaseHTTPRequestHandler和SimpleHTTPRequestHandler这类的处理类太挫太不灵活了,针对这个http.server模块还提供了一种处理类:CGIHTTPRequestHandler,它可以通过请求信息选择执行指向的cgi脚本。cgi虽然更灵活,但也有一些弊端,于是后面又有了各种方案:fastcgi、mod_python、wsgi...有兴趣的可以看 HOWTO Use Python in the web。但在不复杂的情况下,这些自带的请求处理类也勉强够用了。
再谈到之前说的HTTPServer,在线上环境中一般没有人会这么傻,直接使用这个内置的HTTPServer的。因为它是单进程而且在请求的生命周期内都只能处理同一个请求,不过好在socketserver这个模块也提供了ThreadingMixIn以及ForkingMixIn,他们的目的是当一个请求到来时使用新建一个线程或一个进程去处理它。
使用方法十分简单,用ThreadingMixIn或ForkingMixIn与Server类组成混合类就行了:
class ThreadingHTTPServer(ThreadingMixIn, HTTPServer):
pass通过ThreadingMixIn的源码确实可以看到它重写了process_request这个方法,它会覆盖混合类中Server类的process_request方法,当Server处理请求时就会调用到这个方法,在ThreadingMixIn的处理中,会新起一个线程来处理请求。这样一来,服务器的并发能力就比原来有了很大的提升了。
class ThreadingMixIn:
daemon_threads = False
def process_request_thread(self, request, client_address):
try:
self.finish_request(request, client_address)
self.shutdown_request(request)
except:
self.handle_error(request, client_address)
self.shutdown_request(request)
def process_request(self, request, client_address):
t = threading.Thread(target = self.process_request_thread,
args = (request, client_address))
t.daemon = self.daemon_threads
t.start()但有的人看到这里不一定会满意,一个请求一个线程,一百个请求一百个线程,一万个、十万个...还不得上天啊。在实际环境中,一般需要把线程控制在一定的数量内(例如线程池)以降低系统负载。
现在继续把目光转移到我们一开始讨论的socket上,再来扯IO模型的问题。
我们知道socket的输入需要两个阶段:
- 等待数据准备好。
- 从内核向进程复制数据。
因为等待的过程是阻塞式,所以我们上面使用多线程就是降低这个阻塞所带来的影响。
现在来看五种IO模型:
阻塞IO模型
recv->无数据报准备好->等待数据->数据报准备好->数据从内核复制到用户空间->复制完成->返回成功指示
非阻塞IO模型
recv->无数据报准备好->返回EWOULDBLOCK->recv->无数据报准备好->返回EWOULDBLOCK->数据报准备好->数据从内核复制到用户空间->复制完成->返回成功指示
特点:轮询操作,大量占用cpu时间。
IO复用模型
select->无数据报准备好->据报准备好->返回可读条件->recv->数据从内核复制到用户空间->复制完成->返回成功指示
信号驱动模型
建立信号处理程序(sigaction)->递交SIGIO->recv->数据从内核复制到用户空间->复制完成->返回成功指示
异步IO模型
aio_read->无数据准备好->数据报准备好->数据从内核复制到用户空间->复制完成->递交aio_read中指定的信号
特点:直到数据复制完成产生信号的过程中进程都不被阻塞。
毫无疑问,我们从开始一直使用着阻塞的IO模型,这个效率是低下的。
为了获取更好的性能,我们一般采用IO多路复用模型,例如select和poll操作,运行进程同时检查多个文件描述符以找出它们任意一个是否可以进行IO操作,内核一旦发现进程指定的一个或多个IO条件就绪(输入准备被读取,或描述符能承接更多的输出),它就通知进程。
但前面说了select和poll有一个弊端就是他们在检查可用描述符的时候都是不断地遍历又遍历,当要监听的socket的文件描述符数量庞大时,性能会急剧下降,CPU消耗严重。
信号驱动模型比他们优越的地方在于,当有输入数据来到指定的文件描述符时,内核向请求数据的进程发送一个信号,进程可以处理其他任务,通过接收信号以获得通知。
而epoll则更进一步,用事件驱动的方式来监听fd,避免了信号处理的繁琐,在文件描述符上注册事件函数,由系统监视这些文件描述符,当在文件描述符可就绪时,内核通知应用进程。
在一些高并发的网络操作上,epoll的性能通常比select跟poll好几个数量级。
IO调用中有两个概念:
- 水平触发:如果文件描述符可以非阻塞地进行io调用,此时认为他已经就绪)。(支持模型:select,poll,epoll等)
- 边缘触发:如果文件描述符自上次来的时候有了新的io活动(新的输入),触发通知。(支持模型:信号驱动,epoll等)
在实际开发中要注意他们的区别,知道边缘触发为什么可能产生socket饥饿问题,怎么解决。
用一张图总结5个IO模型是这样的:

使用多路IO复用模型能有效提高网络编程的质量。
HTTP
现在再来看HTTP,HTTP是在TCP之上的无状态的协议,处于四层模型中的应用层,HTTP使用TCP来传输报文数据。
以浏览器输入一个网址打开为例,看HTTP的请求过程:
- 浏览器首先从URL中解析出主机名,端口等信息,URL的通用格式为:<schema>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<flag>。
- 浏览器把主机名转换为IP地址(DNS)。
- 浏览器与服务器建立一条TCP连接。
- 浏览器在TCP连接上发送一条HTTP请求报文。
- 服务器在TCP连接上返回一条HTTP响应报文。
- 关闭连接,浏览器渲染文档。
HTTP的请求信息包括几个要素:
- 请求行,例如GET /index.html HTTP/1.1,表示要请求index.html这个文件。
- 请求头(首部)。
- 空行。
- 消息体。
例如在第一个例子中,我们向8000端口发起请求:
GET / HTTP/1.1 (请求行)
Host: 127.0.0.1:8000 (请求头)会得到以下回应:
HTTP/1.0 200 OK (响应行)
Content-Length: 5252
Content-type: text/html; charset=utf-8
Date: Tue, 21 Feb 2017 08:36:01 GMT
Server: SimpleHTTP/0.6 Python/3.4.5
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>Directory listing for /</title>
</head>
<body>
<h1>Directory listing for /</h1>
....HTTP的关键之处在于它的首部,HTTP的首部信息决定了客户端和服务器端能做什么事情。
HTTP状态码
HTTP & DOM
DOM,又称Document Object Module,即文档对象模型。我们在写爬虫的时候通常都需要对html页面进行解析,这时候就需要dom解析器来对抓取的页面进行分析。
平时我们用lxml和BeautifulSoup用得爽了,但他们是怎么去解析html的呢?
在python的html.parser模块中就带了一个HTML解析器:
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Encountered a start tag:", tag)
def handle_endtag(self, tag):
print("Encountered an end tag :", tag)
def handle_data(self, data):
print("Encountered some data :", data)
parser = MyHTMLParser()
parser.feed('<html><head><title>Test</title></head>'
'<body><h1>Parse me!</h1></body></html>')
# ------------------------------------------------------------------
'''
Encountered a start tag: html
Encountered a start tag: head
Encountered a start tag: title
Encountered some data : Test
Encountered an end tag : title
Encountered an end tag : head
Encountered a start tag: body
Encountered a start tag: h1
Encountered some data : Parse me!
Encountered an end tag : h1
Encountered an end tag : body
Encountered an end tag : html
'''可以通过它的源码中来观察dom是如何被解析的。
HTTP & RESTful
推荐阅读:RESTful API 设计最佳实践
HTTP More
推荐阅读:《HTTP权威指南》
DNS
主机到IP的转换通常要经过DNS查询,DNS是一个庞大的分布式数据库,它将主机名组织在一个层级的空间中,一个节点的域名由该节点到根的路径所有节点组成的名字连接而成。
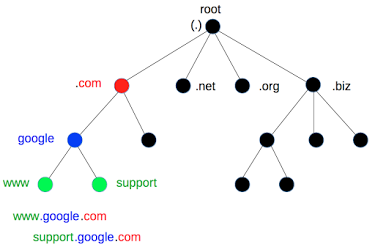
使用dnspython包可以方便地进行dns查询:
import dns.resolver
domain = 'baidu.com'
A = dns.resolver.query(domain, 'A')
for answer in A.response.answer:
for item in answer.items:
print(item.address)FTP
在python世界里,使用ftp非常简单,只需要使用内置的ftplib模块就可以使用ftp协议对远端机器进行操作:
from ftplib import FTP
with FTP("ftp1.at.proftpd.org") as ftp:
ftp.login()
ftp.dir()
'230 Anonymous login ok, restrictions apply.'
dr-xr-xr-x 9 ftp ftp 154 May 6 10:43 .
dr-xr-xr-x 9 ftp ftp 154 May 6 10:43 ..
dr-xr-xr-x 5 ftp ftp 4096 May 6 10:43 CentOS
dr-xr-xr-x 3 ftp ftp 18 Jul 10 2008 FedoraXML-RPC
建立一个XML-RPC的服务器跟客户端同样很简单。
Server
from xmlrpc.server import SimpleXMLRPCServer
import datetime
class ExampleService:
def getData(self):
return '42'
class currentTime:
@staticmethod
def getCurrentTime():
return datetime.datetime.now()
server = SimpleXMLRPCServer(("localhost", 8000))
server.register_function(pow)
server.register_function(lambda x,y: x+y, 'add')
server.register_instance(ExampleService(), allow_dotted_names=True)
server.register_multicall_functions()
print('Serving XML-RPC on localhost port 8000')
try:
server.serve_forever()
except KeyboardInterrupt:
print("\nKeyboard interrupt received, exiting.")
sys.exit(0)Client
from xmlrpc.client import ServerProxy, MultiCall
server = ServerProxy("http://localhost:8000")
try:
print(server.currentTime.getCurrentTime())
except Error as v:
print("ERROR", v)
multi = MultiCall(server)
multi.getData()
multi.pow(2,9)
multi.add(1,2)
try:
for response in multi():
print(response)
except Error as v:
print("ERROR", v)SMTP & POP3
import smtplib
import poplibEnd
关于网络编程,这里只是冰山一角,还有很多可以说的,鉴于本人水平不足,有兴趣的读者可以去自行了解。
